L2M
1.0.0
Thomas Schmied 1 , Markus Hofmarcher 2 , Fabian Paischer 1 , Razvan PacScanu 3,4 , Sepp Hochreiter 1,5
1 Ellis Unit Linz y Lit Ai Lab, Institute for Machine Learning, Johannes Kepler University Linz, Austria
2 JKU Lit Sal ESPML Lab, Instituto para el Aprendizaje Autor, Johannes Kepler University Linz, Austria
3 Google DeepMind
4 UCL
5 Instituto de Investigación Avanzada en Inteligencia Artificial (IARAI), Viena, Austria
Este repositorio contiene el código fuente para "aprender a modular modelos previamente capacitados en RL" aceptado en Neurips 2023. El documento está disponible aquí.
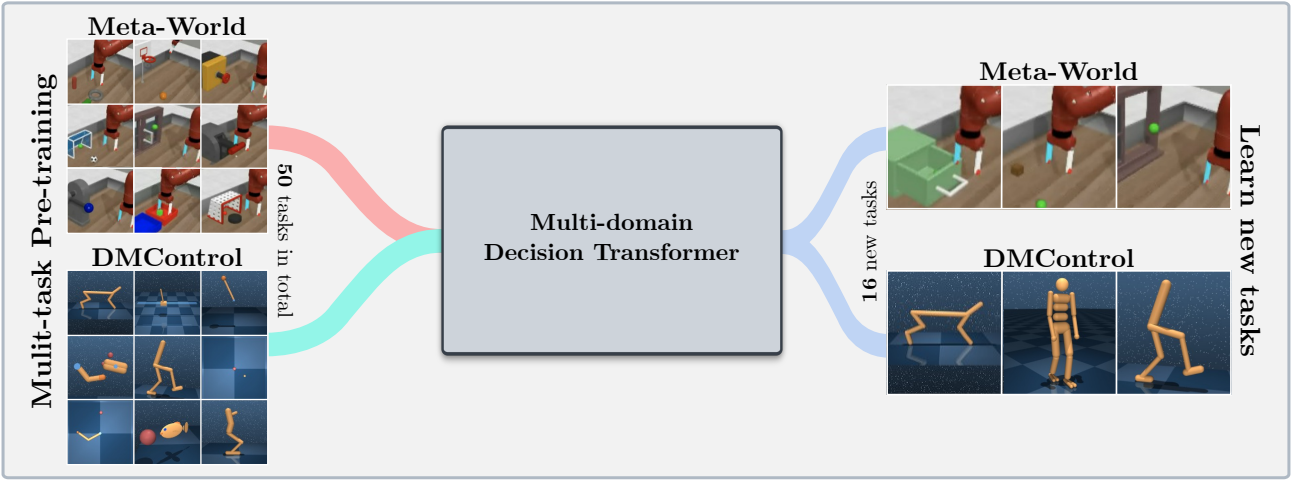
Esta base de código admite modelos de transformador de decisión de capacitación (DT) en línea o desde conjuntos de datos fuera de línea en los siguientes dominios:
Esta base de código se basa en marcos de código abierto, que incluyen:
¿Qué hay en este repositorio?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
La configuración y las dependencias del entorno están disponibles en environment.yaml y requirements.txt .
Primero, cree el entorno de conda.
conda env create -f environment.yaml
conda activate mddt
Luego instale los requisitos restantes (con Mujoco ya descargado, si no vea aquí):
pip install -r requirements.txt
Init The continualworld Submodule and Install:
git submodule init
git submodule update
cd continualworld
pip install .
Instalar meta-world :
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
Instale la versión personalizada de DMC2Gym. Nuestra versión hace que flatten_obs sea opcional y, por lo tanto, nos permite construir el espacio de observación completo de todos los envs de DMControl.
cd dmc2gym_custom
pip install -e .
Descargar Mujoco:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
Luego agregue la siguiente línea a .bashrc :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
Los siguientes problemas fueron útiles:
Primero, instale los siguientes paquetes:
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
Crea el enlace simbólico manualmente:
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
Entonces haz:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
Finalmente, exporte la ruta a rpm DIR (agregue a ~/.bashrc ):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
Esta base de código se basa en Hydra, que configura experimentos a través de archivos .yaml . Hydra crea automáticamente la estructura de la carpeta de registro para una ejecución dada, como se especifica en el archivo config.yaml respectivo.
config.yaml es el principal punto de entrada de configuración y contiene los parámetros predeterminados. El archivo hace referencia a los archivos de parámetro predeterminados respectivos en los defaults de bloque. Además, config.yaml contiene 4 constantes importantes que configuran las rutas de directorio:
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
Los conjuntos de datos generados se alojan actualmente a través de nuestro servidor web. Descargue los conjuntos de datos Meta-World y DMControl a los DATA_DIR especificados_dir:
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
Los conjuntos de datos también están disponibles en el Hub Huggingface. Descargar usando el huggingface-cli :
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
El marco también admite conjuntos de datos ATARI, D4RL y Visual DMControl. Para Atari y Visual DMControl, nos referimos a los reingresos respectivos.
A continuación, proporcionamos algunos ejemplos ilustrativos de cómo ejecutar los experimentos en el documento.
Para entrenar un modelo de transformador de decisión multidominio de 40 m (MDDT) en MT40 + DMC10 con 3 semillas en una sola GPU, Ejecutar:
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
Para ajustar el modelo previamente capacitado usando Lora en una sola tarea CW10 con 3 semillas, ejecute:
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
Para ajustar el modelo previamente capacitado usando L2M en todas las tareas CW10 de manera secuencial con 3 semillas, ejecute:
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
Para el entrenamiento multi-GPU, usamos torchrun . La herramienta entra en conflicto con hydra . Por lo tanto, se creó un complemento de lanzador HYDRA_TORCHRUN_LAUNCHER.
Para habilitar el complemento, clone el repositorio hydra , CD para contrib/hydra_torchrun_launcher , y pip instale el complemento:
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
El complemento se puede usar desde la línea de comandos:
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Se puede realizar experimentos en un clúster local en un solo nodo a través de CUDA_VISIBLE_DEVICES para especificar las GPU para usar:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
En Slurm, la ejecución torchrun en un solo nodo funciona por igual. Por ejemplo, ejecutar en 2 GPU en un solo nodo:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
Los scripts de ejemplo para capacitación multi-GPU en SLURM o PBS están disponibles en scripts .
Ejecutar Slurm/PBS en una configuración de múltiples nodos requiere un poco más de cuidado. Los scripts de ejemplo se proporcionan en scripts .
Si encuentra esto útil, considere citar nuestro trabajo:
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


