L2M
1.0.0
トーマス・シュミーは1 、マルクス・ホフマーカー2 、ファビアン・パイシャー1 、ラズヴァン・パッカヌ3,4 、セップ・ホッホライター1,5
1エリスユニットリンツとライトAIラボ、機械学習研究所、ヨハネスケプラー大学リンツ、オーストリア
2 JKU LIT SAL ESPMLラボ、機械学習研究所、ヨハネスケプラー大学リンツ、オーストリア
3 Google Deepmind
4 UCL
5オーストリア、ウィーンの人工知能(IARAI)の高等研究所研究所
このリポジトリには、Neurips 2023で受け入れられている「RLで事前に訓練されたモデルを変調することを学習する」ソースコードが含まれています。この論文はここで入手できます。
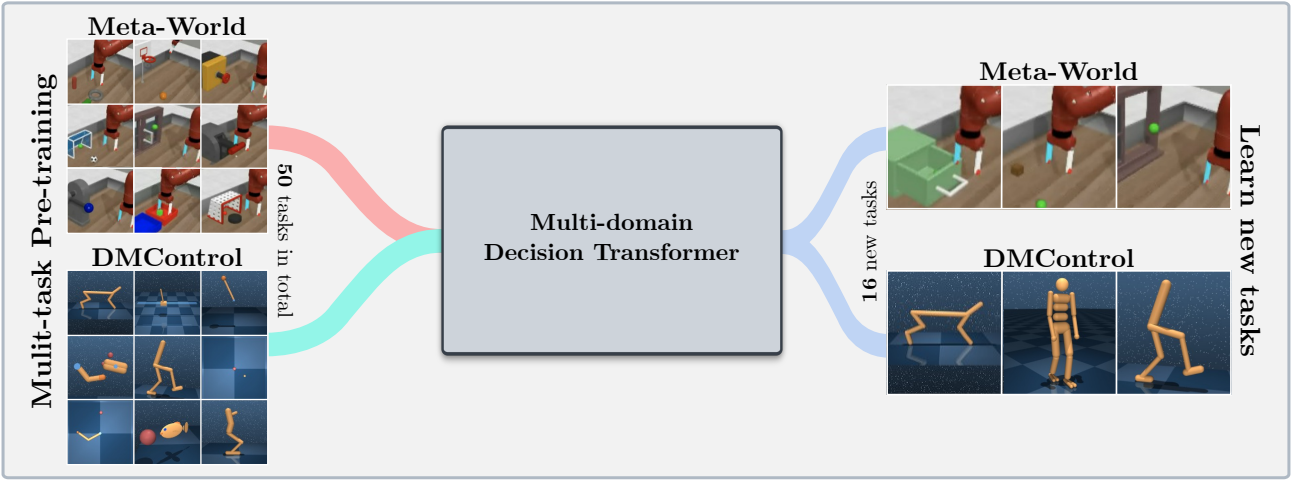
このコードベースは、オンラインまたは次のドメインのオフラインデータセットからトレーニング決定変圧器(DT)モデルをサポートしています。
このコードベースは、以下を含むオープンソースのフレームワークに依存しています。
このリポジトリには何がありますか?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
環境構成と依存関係は、 environment.yamlで利用できます。yamlおよびrequirements.txt 。
まず、コンドラ環境を作成します。
conda env create -f environment.yaml
conda activate mddt
次に、残りの要件をインストールします(ムホコが既にダウンロードされている場合、ここには表示されていない場合):
pip install -r requirements.txt
continualworldサブモジュールとインストールを開始します。
git submodule init
git submodule update
cd continualworld
pip install .
meta-worldをインストールします:
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
DMC2GYMのカスタムバージョンをインストールします。私たちのバージョンはflatten_obsオプションにするため、すべてのDMControl Envの完全な観測スペースを構築できます。
cd dmc2gym_custom
pip install -e .
Mujocoをダウンロード:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
次に、次の行を.bashrcに追加します。
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
次の問題は役に立ちました。
まず、次のパッケージをインストールします。
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
Symlinkを手動で作成します。
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
その後、:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
最後に、パスをrpm dirにエクスポートします( ~/.bashrcに追加):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
このコードベースは、 .yamlファイルを介して実験を構成するHydraに依存しています。 Hydraは、それぞれのconfig.yamlファイルで指定されているように、特定の実行のログフォルダー構造を自動的に作成します。
config.yamlメイン構成エントリポイントであり、デフォルトのパラメーターが含まれています。ファイルは、ブロックのdefaultsの下のそれぞれのデフォルトパラメーターファイルを参照します。さらに、 config.yamlは、ディレクトリパスを構成する4つの重要な定数が含まれています。
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
生成されたデータセットは現在、Webサーバーを介してホストされています。指定されたDATA_DIRにMeta-WorldおよびDMControlデータセットをダウンロードしてください。
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
データセットは、Huggingfaceハブでも利用できます。 huggingface-cliを使用してダウンロードしてください:
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
このフレームワークは、Atari、D4RL、およびVisual DMControlデータセットもサポートしています。 AtariおよびVisual DMControlについては、それぞれのReadmesを参照します。
以下では、紙の中で実験を実行する方法のいくつかの説明例を示します。
MT40 + DMC10で40mマルチドメイン決定トランス(MDDT)モデルを1つのGPUに3つの種子で訓練するには、実行します。
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
3つのシードを使用した単一のCW10タスクでLORAを使用して事前に訓練されたモデルを微調整するには、実行します。
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
すべてのCW10タスクでL2Mを使用して3つのシードを使用して列を並べて事前に訓練されたモデルを微調整するには、実行します。
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
マルチGPUトレーニングには、 torchrunを使用します。ツールはhydraと競合します。したがって、ランチャープラグインHYDRA_TORCHRUN_LAUNCHERが作成されました。
プラグインを有効にするには、 hydra Repo、CDをcontrib/hydra_torchrun_launcherにクローンし、PIPをプラグインをインストールします。
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
プラグインはコマンドラインから使用できます。
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
単一のノード上のローカルクラスターでの実験を実行することは、 CUDA_VISIBLE_DEVICESを介して実行して、使用するGPUを指定できます。
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Slurmでは、単一のノードでtorchrunを実行します。たとえば、単一のノードで2つのGPUで実行するには:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
SluRMまたはPBSのマルチGPUトレーニングの例のスクリプトは、 scriptsで利用できます。
マルチノードのセットアップでSluRM/PBSで実行するには、もう少し注意が必要です。スクリプトの例は、 scriptsで提供されています。
これが便利だと思う場合は、私たちの仕事を引用することを検討してください。
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


