L2M
1.0.0
Thomas Schmied 1 , Markus HofMarcher 2 , Fabian Paischer 1 , Razvan Pacscanu 3,4 , Sepp Hochreiter 1,5
1 Ellis Unit Linz et Lit AI Lab, Institute for Machine Learning, Johannes Kepler University Linz, Autriche
2 JKU Lit Sal ESPML Lab, Institute for Machine Learning, Johannes Kepler University Linz, Autriche
3 Google Deepmind
4 UCL
5 Institut de recherche avancée en intelligence artificielle (IARAI), Vienne, Autriche
Ce référentiel contient le code source pour "apprendre à moduler les modèles pré-formés dans RL" acceptés à Neirips 2023. Le document est disponible ici.
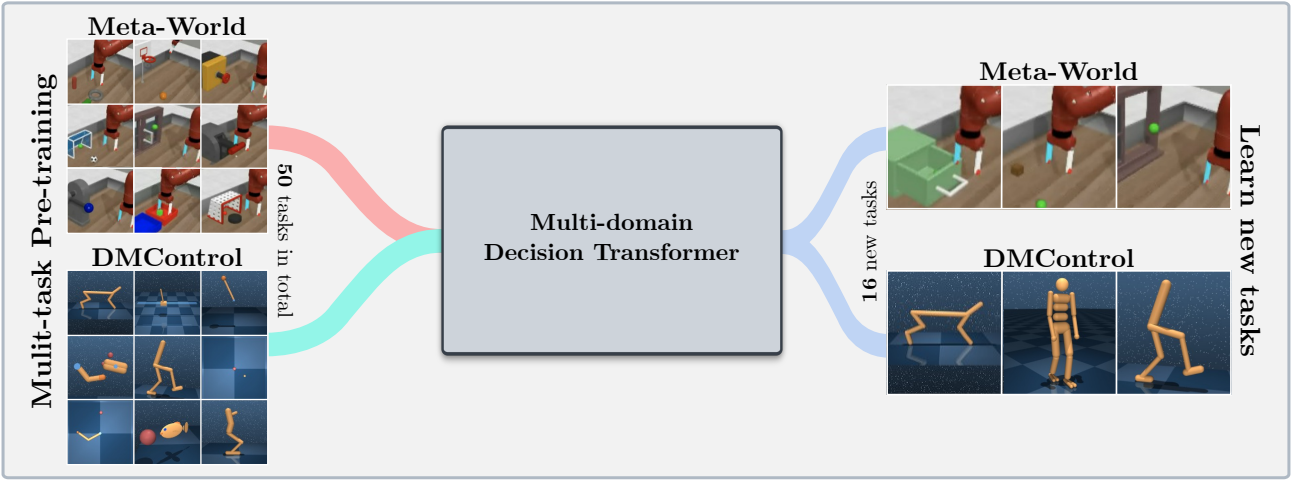
Cette base de code prend en charge les modèles de transformateur de décision de formation (DT) en ligne ou à partir de jeux de données hors ligne sur les domaines suivants:
Cette base de code repose sur des cadres open source, notamment:
Qu'y a-t-il dans ce référentiel?
.
├── configs # Contains all .yaml config files for Hydra to configure agents, envs, etc.
│ ├── agent_params
│ ├── wandb_callback_params
│ ├── env_params
│ ├── eval_params
│ ├── run_params
│ └── config.yaml # Main config file for Hydra - specifies log/data/model directories.
├── continual_world # Submodule for Continual-World.
├── dmc2gym_custom # Custom wrapper for DMControl.
├── figures
├── scripts # Scrips for running experiments on Slurm/PBS in multi-gpu/node setups.
├── src # Main source directory.
│ ├── algos # Contains agent/model/prompt classes.
│ ├── augmentations # Image augmentations.
│ ├── buffers # Contains replay trajectory buffers.
│ ├── callbacks # Contains callbacks for training (e.g., WandB, evaluation, etc.).
│ ├── data # Contains data utilities (e.g., for downloading Atari)
│ ├── envs # Contains functionality for creating environments.
│ ├── exploration # Contains exploration strategies.
│ ├── optimizers # Contains (custom) optimizers.
│ ├── schedulers # Contains learning rate schedulers.
│ ├── tokenizers_custom # Contains custom tokenizers for discretizing states/actions.
│ ├── utils
│ └── __init__.py
├── LICENSE
├── README.md
├── environment.yaml
├── requirements.txt
└── main.py # Main entry point for training/evaluating agents.
La configuration et les dépendances de l'environnement sont disponibles dans environment.yaml et requirements.txt .
Tout d'abord, créez l'environnement conda.
conda env create -f environment.yaml
conda activate mddt
Installez ensuite les exigences restantes (avec Mujoco déjà téléchargé, sinon voir ici):
pip install -r requirements.txt
Init le sous-module continualworld et installer:
git submodule init
git submodule update
cd continualworld
pip install .
Installer meta-world :
pip install git+https://github.com/rlworkgroup/metaworld.git@18118a28c06893da0f363786696cc792457b062b
Installez la version personnalisée de DMC2GYM. Notre version rend flatten_obs en option et, par conséquent, nous permet de construire l'espace d'observation complet de tous les Envs DmControl.
cd dmc2gym_custom
pip install -e .
Téléchargez Mujoco:
mkdir ~/.mujoco
cd ~/.mujoco
wget https://www.roboti.us/download/mujoco200_linux.zip
unzip mujoco200_linux.zip
mv mujoco200_linux mujoco200
wget https://www.roboti.us/file/mjkey.txt
Ajoutez ensuite la ligne suivante à .bashrc :
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/.mujoco/mujoco200/bin
Les problèmes suivants ont été utiles:
Tout d'abord, installez les packages suivants:
conda install -c conda-forge glew mesalib
conda install -c menpo glfw3 osmesa
pip install patchelf
Créez manuellement le lien symbolique:
cp /usr/lib64/libGL.so.1 $CONDA_PREFIX/lib
ln -s $CONDA_PREFIX/lib/libGL.so.1 $CONDA_PREFIX/lib/libGL.so
Alors faites:
mkdir ~/rpm
cd ~/rpm
curl -o libgcrypt11.rpm ftp://ftp.pbone.net/mirror/ftp5.gwdg.de/pub/opensuse/repositories/home:/bosconovic:/branches:/home:/elimat:/lsi/openSUSE_Leap_15.1/x86_64/libgcrypt11-1.5.4-lp151.23.29.x86_64.rpm
rpm2cpio libgcrypt11.rpm | cpio -id
Enfin, exportez le chemin vers rpm Dir (Ajouter à ~/.bashrc ):
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:~/rpm/usr/lib64
export LDFLAGS="-L/~/rpm/usr/lib64"
Cette base de code s'appuie sur HYDRA, qui configure des expériences via des fichiers .yaml . HYDRA crée automatiquement la structure du dossier de journal pour une exécution donnée, comme spécifié dans le fichier config.yaml respectif.
La config.yaml est le point d'entrée de configuration principal et contient les paramètres par défaut. Le fichier fait référence aux fichiers de paramètre par défaut respectifs sous les defaults du bloc. De plus, config.yaml contient 4 constantes importantes qui configurent les chemins de répertoire:
LOG_DIR: ../logs
DATA_DIR: ../data
SSD_DATA_DIR: ../data
MODELS_DIR: ../models
Les ensembles de données générés sont actuellement hébergés via notre serveur Web. Téléchargez des ensembles de données Meta-monde et DMControl sur DATA_DIR spécifié:
# Meta-World
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/metaworld
# DMControl
wget --recursive --no-parent --no-host-directories --cut-dirs=2 -R "index.html*" https://ml.jku.at/research/l2m/dm_control_1M
Les ensembles de données sont également disponibles sur le HuggingFace Hub. Téléchargez en utilisant le huggingface-cli :
# Meta-World
huggingface-cli download ml-jku/meta-world --local-dir=./meta-world --repo-type dataset
# DMControl
huggingface-cli download ml-jku/dm_control --local-dir=./dm_control --repo-type dataset
Le cadre prend également en charge les ensembles de données ATARI, D4RL et Visual DMControl. Pour Atari et Visual DMControl, nous nous référons aux Readmes respectifs.
Dans ce qui suit, nous fournissons quelques exemples illustratifs de la façon d'exécuter les expériences dans l'article.
Pour former un modèle de transformateur de décision multi-domaines de 40 m (MDDT) sur MT40 + DMC10 avec 3 graines sur un seul GPU, exécuter:
python main.py -m experiment_name=pretrain seed=42,43,44 env_params=multi_domain_mtdmc run_params=pretrain eval_params=pretrain_disc agent_params=cdt_pretrain_disc agent_params.kind=MDDT agent_params/model_kwargs=multi_domain_mtdmc agent_params/data_paths=mt40v2_dmc10 +agent_params/replay_buffer_kwargs=multi_domain_mtdmc +agent_params.accumulation_steps=2
Pour affiner le modèle pré-formé en utilisant LORA sur une seule tâche CW10 avec 3 graines, exécutez:
python main.py -m experiment_name=cw10_lora seed=42,43,44 env_params=mt50_pretrain run_params=finetune eval_params=finetune agent_params=cdt_mpdt_disc agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft agent_params/model_kwargs/prompt_kwargs=lora env_params.envid=hammer-v2 agent_params.data_paths.names='${env_params.envid}.pkl' env_params.eval_env_names=
Pour affiner le modèle pré-formé en utilisant L2M sur toutes les tâches CW10 de manière séquentielle avec 3 graines, exécutez:
python main.py -m experiment_name=cw10_cl_l2m seed=42,43,44 env_params=multi_domain_ft env_params.eval_env_names=cw10_v2 run_params=finetune_coff eval_params=finetune_md_cl agent_params=cdt_mpdt_disc +agent_params.steps_per_task=100000 agent_params/model_kwargs=mdmpdt_mtdmc agent_params/data_paths=cw10_v2_cwnet_2M +agent_params/replay_buffer_kwargs=mtdmc_ft +agent_params.replay_buffer_kwargs.kind=continual agent_params/model_kwargs/prompt_kwargs=l2m_lora
Pour la formation multi-GPU, nous utilisons torchrun . L'outil entre en conflit avec hydra . Par conséquent, un plugin de lanceur HYDRA_TORCHRUN_LAUNCHER a été créé.
Pour activer le plugin, clonez le repo hydra , CD à contrib/hydra_torchrun_launcher , et pip installer le plugin:
git clone https://github.com/facebookresearch/hydra.git
cd hydra/contrib/hydra_torchrun_launcher
pip install -e .
Le plugin peut être utilisé à partir de la ligne de commande:
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Les expériences en cours d'exécution sur un cluster local sur un seul nœud peuvent être effectuées via CUDA_VISIBLE_DEVICES pour spécifier les GPU à utiliser:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=4 [...]
Sur Slurm, l'exécution torchrun sur un seul nœud fonctionne comme. Par exemple, pour fonctionner sur 2 GPU sur un seul nœud:
#!/bin/bash
#SBATCH --account=X
#SBATCH --qos=X
#SBATCH --partition=X
#SBATCH --nodes=1
#SBATCH --gpus=2
#SBATCH --cpus-per-task=32
source activate mddt
python main.py -m hydra/launcher=torchrun hydra.launcher.nproc_per_node=2 [...]
Des exemples de scripts pour la formation multi-GPU sur Slurm ou PBS sont disponibles dans scripts .
Faire fonctionner sur Slurm / PBS dans une configuration multi-nœuds nécessite un peu plus de soins. Des exemples de scripts sont fournis dans scripts .
Si vous trouvez cela utile, envisagez de citer notre travail:
@article{schmied2024learning,
title={Learning to Modulate pre-trained Models in RL},
author={Schmied, Thomas and Hofmarcher, Markus and Paischer, Fabian and Pascanu, Razvan and Hochreiter, Sepp},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}


