LVCNet
1.0.0
使用LVCNET來設計平行Wavegan的發電機和訓練它的相同策略,新Vocoder的推理速度比原始Vocoder快5倍以上,而沒有任何音頻質量降解。
ICASSP2021接受了我們目前的作品[論文],我們以前的作品在Melglow中進行了描述。
準備數據,從https://keithito.com/ljspeech-dataset/下載LJSpeech數據集,然後將其保存在data/LJSpeech-1.1中。然後運行
python - m vocoder . preprocess - - data - dir . / data / LJSpeech - 1.1 - - config configs / lvcgan . v1 . yaml計算MEL-SEPCTRUMS並保存在文件夾temp/中。
培訓LVCNET
python - m vocoder . train - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1測試LVCNET
python - m vocoder . test - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1實驗結果,包括訓練日誌,模型檢查點和合成的音頻,存儲在文件夾exps/exp.lvcgan.v1/ 。
相似性,您還可以使用Config File configs/pwg.v1.yaml來訓練並行Wavegan模型。
# training
python - m vocoder . train - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1
# test
python - m vocoder . test - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1 使用張板查看實驗訓練過程:
tensorboard --logdir exps
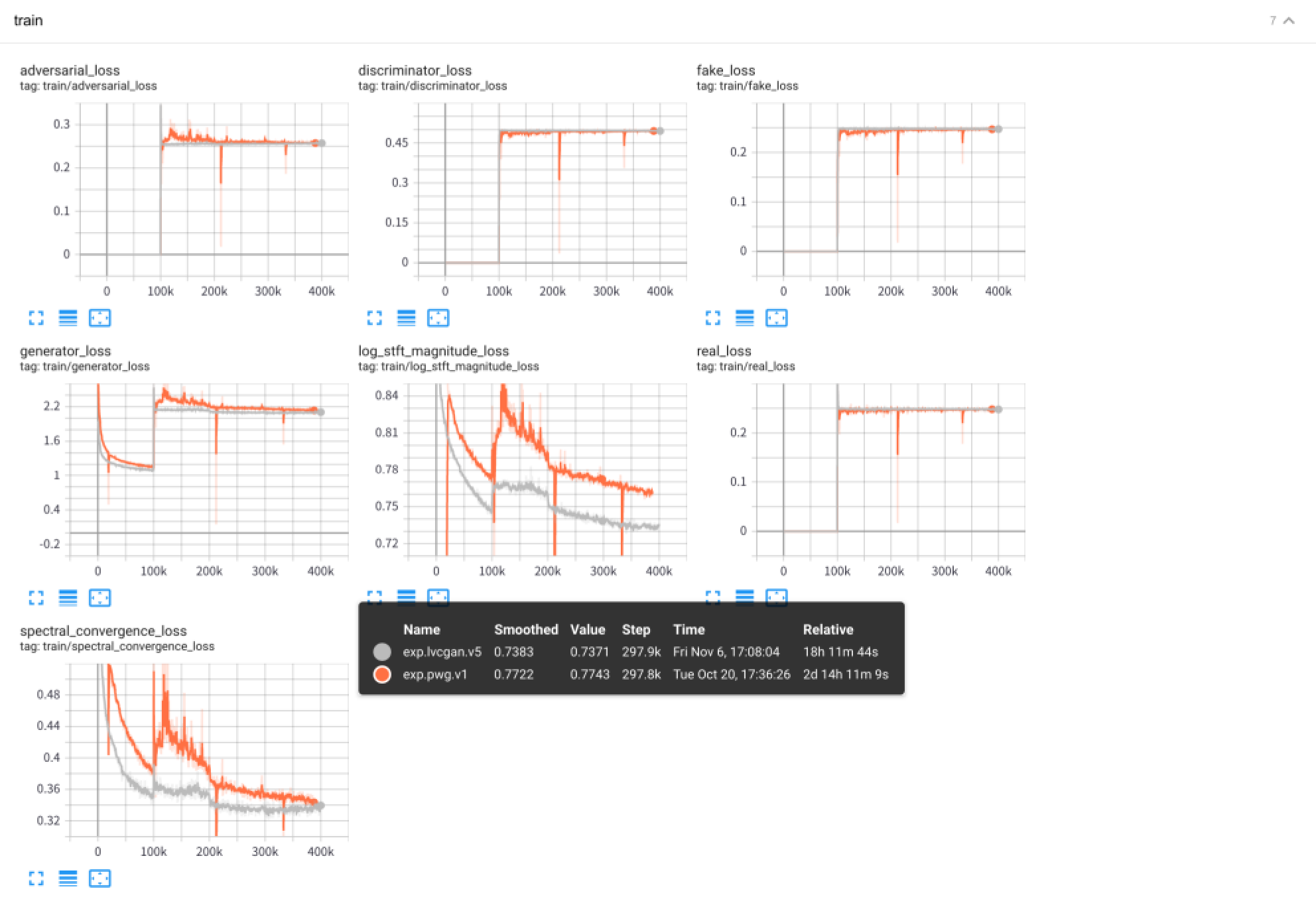
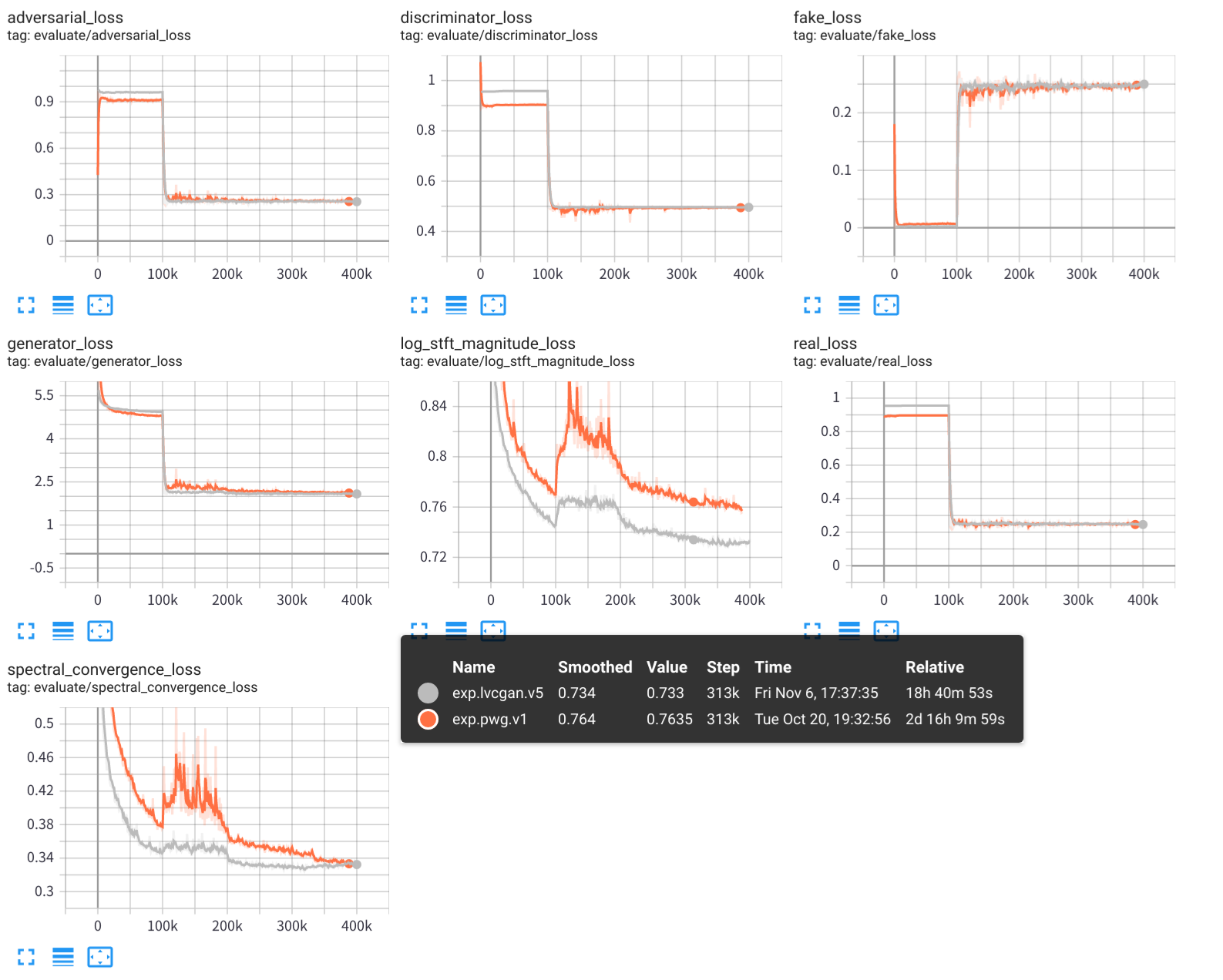
音頻樣品保存在samples/
samples/*_lvc.wav由lvcnet生成samples/*_pwg.wav由平行wavegan生成samples/*_real.wav是真實音頻。 LVCNET:波形生成的有效條件依賴性建模網絡,https://arxiv.org/abs/2102.10815
Melglow:基於位置變量卷積的有效波形生成網絡,https://arxiv.org/abs/2012.01684
https://github.com/kan-bayashi/parallelwavegan
https://github.com/lmnt-com/diffwave


