LVCNet
1.0.0
LVCNETを使用して、Parallel Waveganの発電機とそれをトレーニングするのと同じ戦略を設計すると、新しいボコーダーの推論速度は、オーディオ品質の分解なしに、元のボコーダーよりも5倍以上速くなります。
現在の作品[紙]はICASSP2021によって受け入れられており、以前の作品はMelglowで説明されています。
データを準備し、https://keithito.com/ljspeech-dataset/からLJSpeechデータセットをダウンロードし、 data/LJSpeech-1.1に保存します。その後、実行します
python - m vocoder . preprocess - - data - dir . / data / LJSpeech - 1.1 - - config configs / lvcgan . v1 . yaml Mel-sepctrumsは計算され、フォルダーtemp/に保存されます。
トレーニングlvcnet
python - m vocoder . train - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1lvcnetをテストします
python - m vocoder . test - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1トレーニングログ、モデルチェックポイント、合成オーディオなどの実験結果は、フォルダーexps/exp.lvcgan.v1/に保存されます。
類似性では、Config File configs/pwg.v1.yamlを使用して、並列Wavganモデルをトレーニングすることもできます。
# training
python - m vocoder . train - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1
# test
python - m vocoder . test - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1 テンソルボードを使用して、実験的なトレーニングプロセスを表示します。
tensorboard --logdir exps
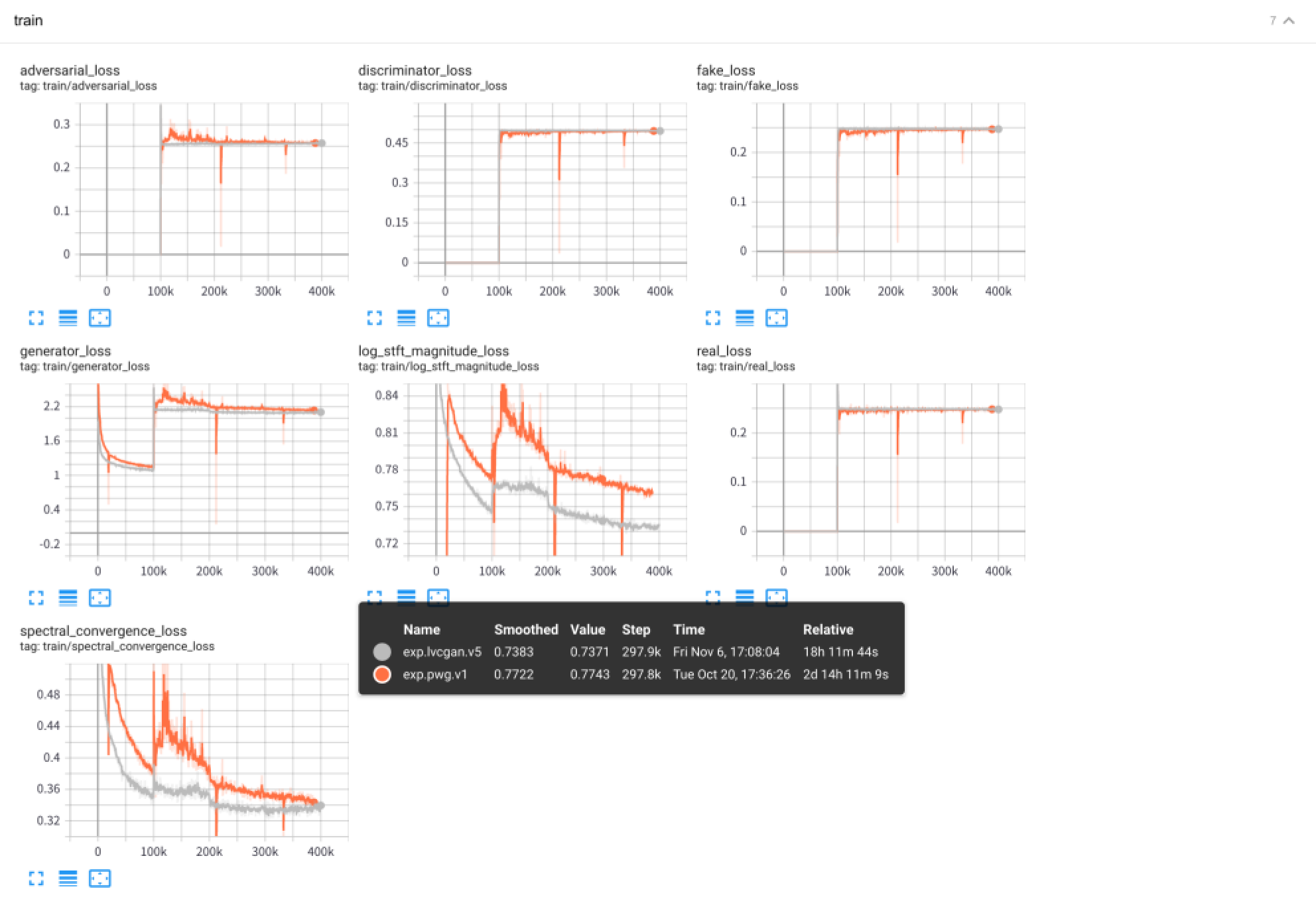
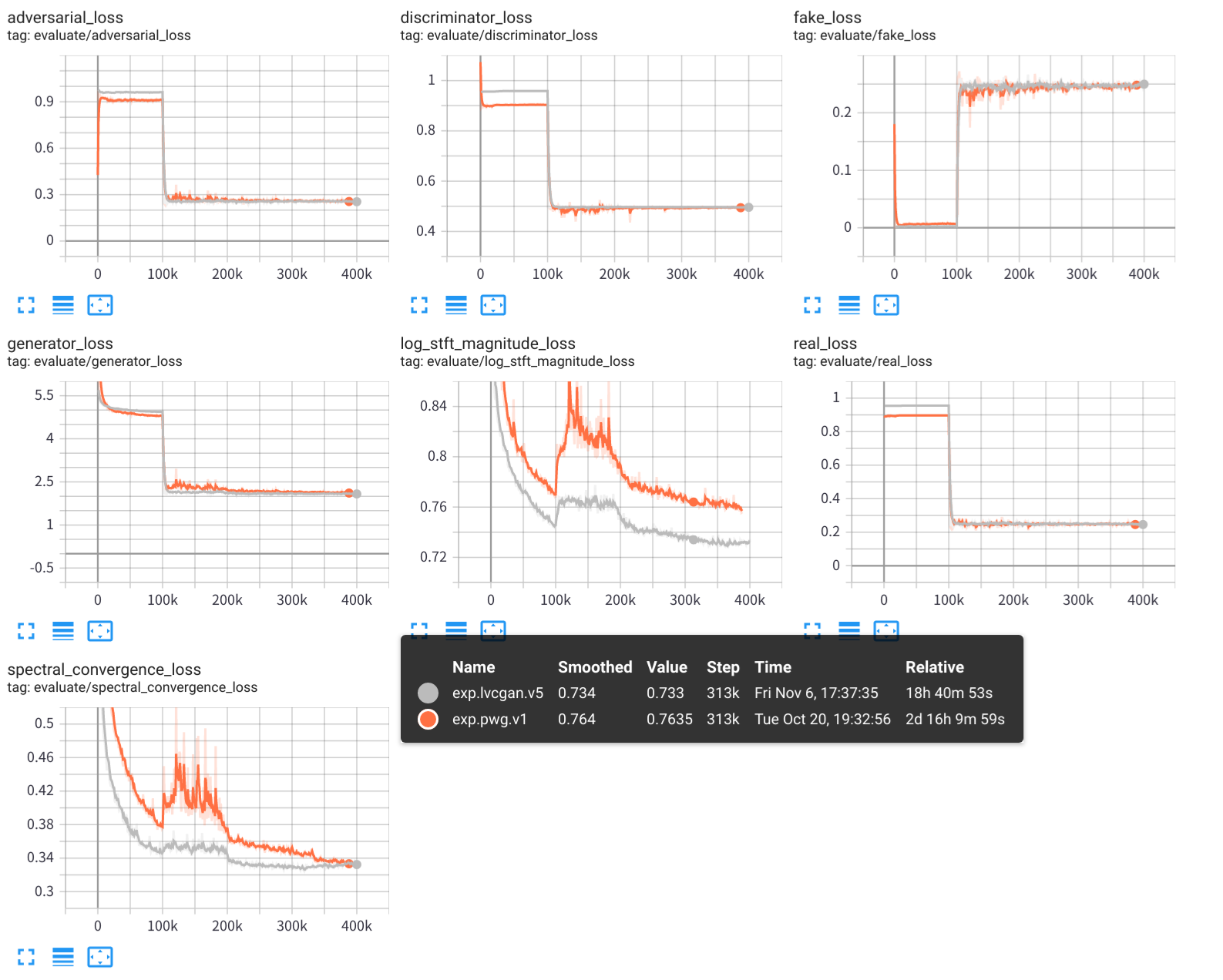
オーディオサンプルはsamples/で保存されます
samples/*_lvc.wavはlvcnetによって生成されます、samples/*_pwg.wavは、並列波線によって生成されます。samples/*_real.wavは実際のオーディオです。 LVCNET:波形生成のための効率的な条件依存モデリングネットワーク、https://arxiv.org/abs/2102.10815
MELGLOW:場所を利用できる畳み込みに基づく効率的な波形生成ネットワーク、https://arxiv.org/abs/2012.01684
https://github.com/kan-bayashi/parallelwavegan
https://github.com/lmnt-com/diffwave


