LVCNet
1.0.0
การใช้ LVCNET เพื่อออกแบบเครื่องกำเนิดไฟฟ้าของ Wavegan แบบขนานและ กลยุทธ์เดียวกัน ในการฝึกอบรมความเร็วการอนุมานของนักร้องใหม่นั้น เร็วกว่า 5 เท่าเร็ว กว่า Vocoder ดั้งเดิม โดยไม่มีการย่อยสลายคุณภาพเสียงใด ๆ
ผลงานปัจจุบันของเรา [กระดาษ] ได้รับการยอมรับจาก ICASSP2021 และผลงานก่อนหน้าของเราได้รับการอธิบายใน Melglow
เตรียมข้อมูลดาวน์โหลดชุดข้อมูล LJSpeech จาก https://keithito.com/lj-speech-dataset/ และบันทึกใน data/LJSpeech-1.1 จากนั้นวิ่ง
python - m vocoder . preprocess - - data - dir . / data / LJSpeech - 1.1 - - config configs / lvcgan . v1 . yaml mel-sepctrums คำนวณและบันทึกใน temp/
การฝึกอบรม lvcnet
python - m vocoder . train - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1ทดสอบ lvcnet
python - m vocoder . test - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1 ผลการทดลองรวมถึงบันทึกการฝึกอบรมจุดตรวจแบบจำลองและเสียงสังเคราะห์ถูกเก็บไว้ในโฟลเดอร์ exps/exp.lvcgan.v1/
ความคล้ายคลึงกันคุณยังสามารถใช้ไฟล์ config configs/pwg.v1.yaml เพื่อฝึกอบรมโมเดล Wavegan แบบขนาน
# training
python - m vocoder . train - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1
# test
python - m vocoder . test - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1 ใช้ Tensorboard เพื่อดูกระบวนการฝึกอบรมการทดลอง:
tensorboard --logdir exps
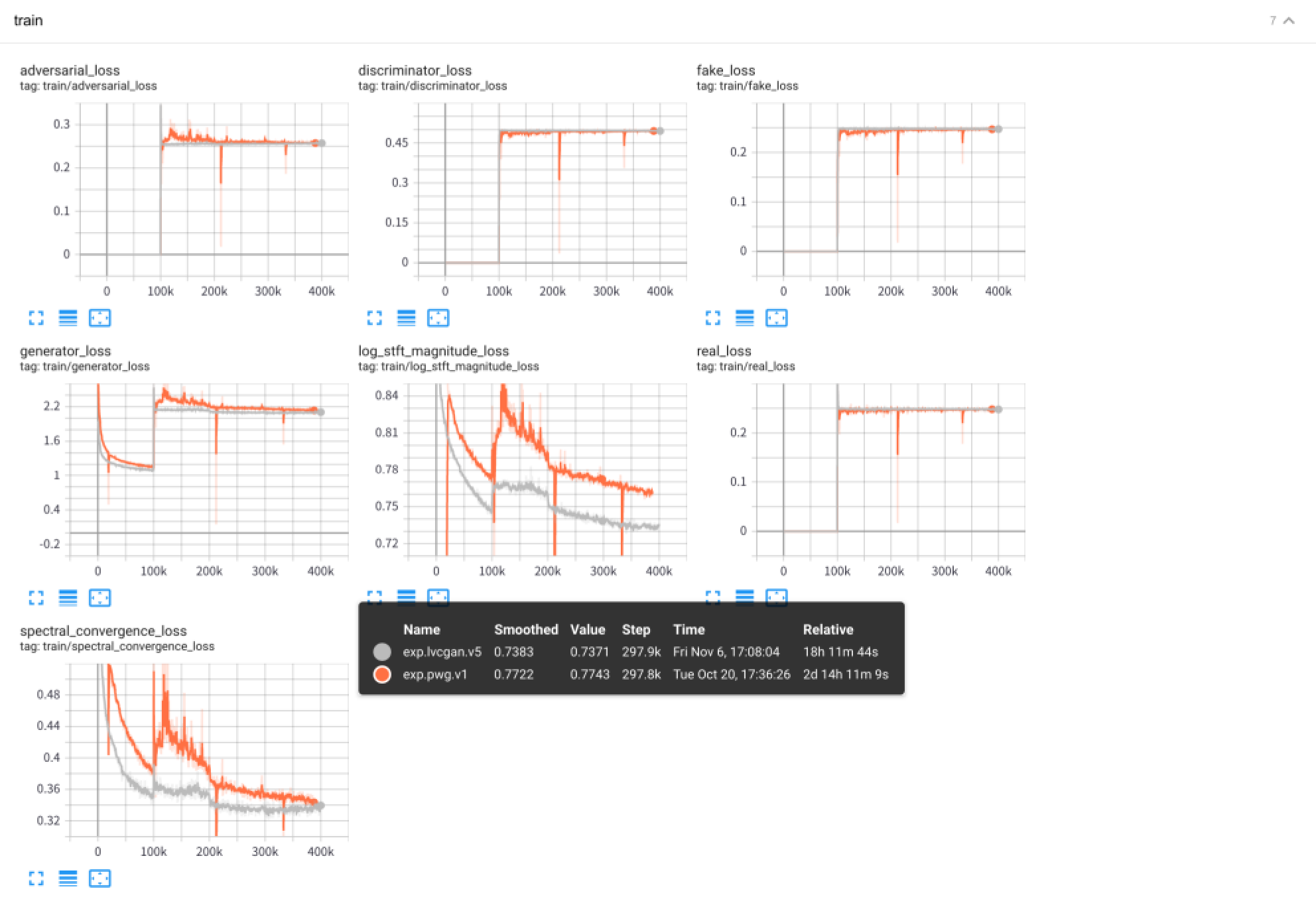
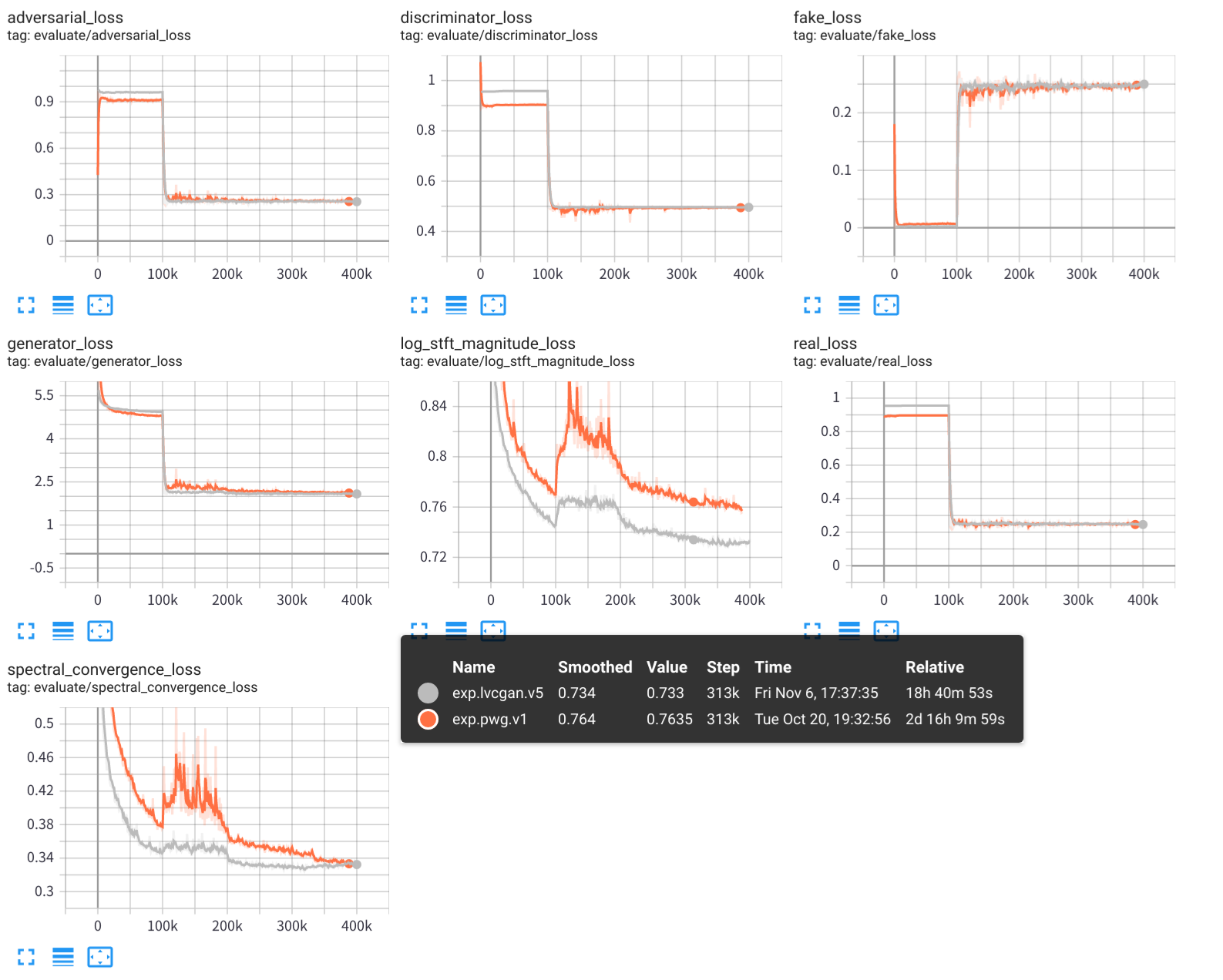
ตัวอย่างเสียงจะถูกบันทึกไว้ใน samples/ โดยที่
samples/*_lvc.wav ถูกสร้างขึ้นโดย lvcnetsamples/*_pwg.wav ถูกสร้างขึ้นโดย Wavegan คู่ขนานsamples/*_real.wav เป็นเสียงจริง LVCNET: เครือข่ายการสร้างแบบจำลองตามเงื่อนไขที่มีประสิทธิภาพสำหรับการสร้างรูปคลื่น https://arxiv.org/abs/2102.10815
Melglow: เครือข่ายการกำเนิดคลื่นที่มีประสิทธิภาพตามการควบคุมตำแหน่ง-ตัวแปร https://arxiv.org/abs/2012.01684
https://github.com/kan-bayashi/parallelwavegan
https://github.com/lmnt-com/diffwave


