LVCNet
1.0.0
باستخدام LVCNET لتصميم مولد Wavegan المتوازي ونفس الإستراتيجية لتدريبه ، فإن سرعة الاستدلال للمتفرج الجديد هي أكثر من 5x أسرع من الماسك الأصلي دون أي تدهور في جودة الصوت .
تم قبول أعمالنا الحالية [Paper] بواسطة ICASSP2021 ، وتم وصف أعمالنا السابقة في Melglow.
قم بإعداد البيانات ، وقم بتنزيل مجموعة بيانات LJSpeech من https://keithito.com/lj-spheade-dataset/ ، وحفظها في data/LJSpeech-1.1 . ثم ركض
python - m vocoder . preprocess - - data - dir . / data / LJSpeech - 1.1 - - config configs / lvcgan . v1 . yaml يتم حساب وحفظ mel-sepctrums في مجلد temp/ .
تدريب lvcnet
python - m vocoder . train - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1اختبار lvcnet
python - m vocoder . test - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1 يتم تخزين النتائج التجريبية ، بما في ذلك سجلات التدريب ، ونقاط التفتيش النموذجية والسماعات المصنفة ، في المجلد exps/exp.lvcgan.v1/ .
التشابه ، يمكنك أيضًا استخدام ملف config configs/pwg.v1.yaml لتدريب نموذج موجة موازية.
# training
python - m vocoder . train - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1
# test
python - m vocoder . test - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1 استخدم Tensorboard لعرض عملية التدريب التجريبية:
tensorboard --logdir exps
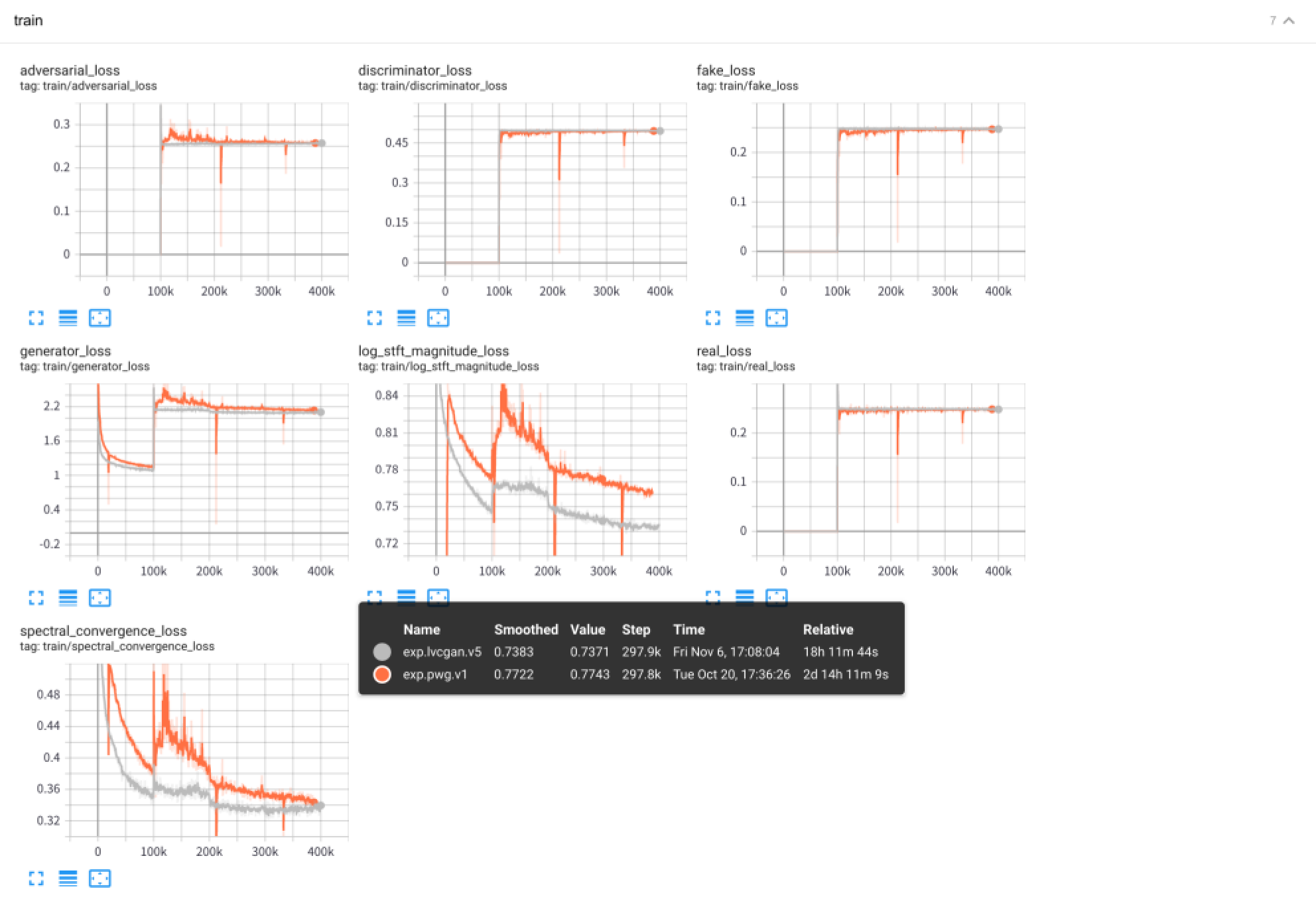
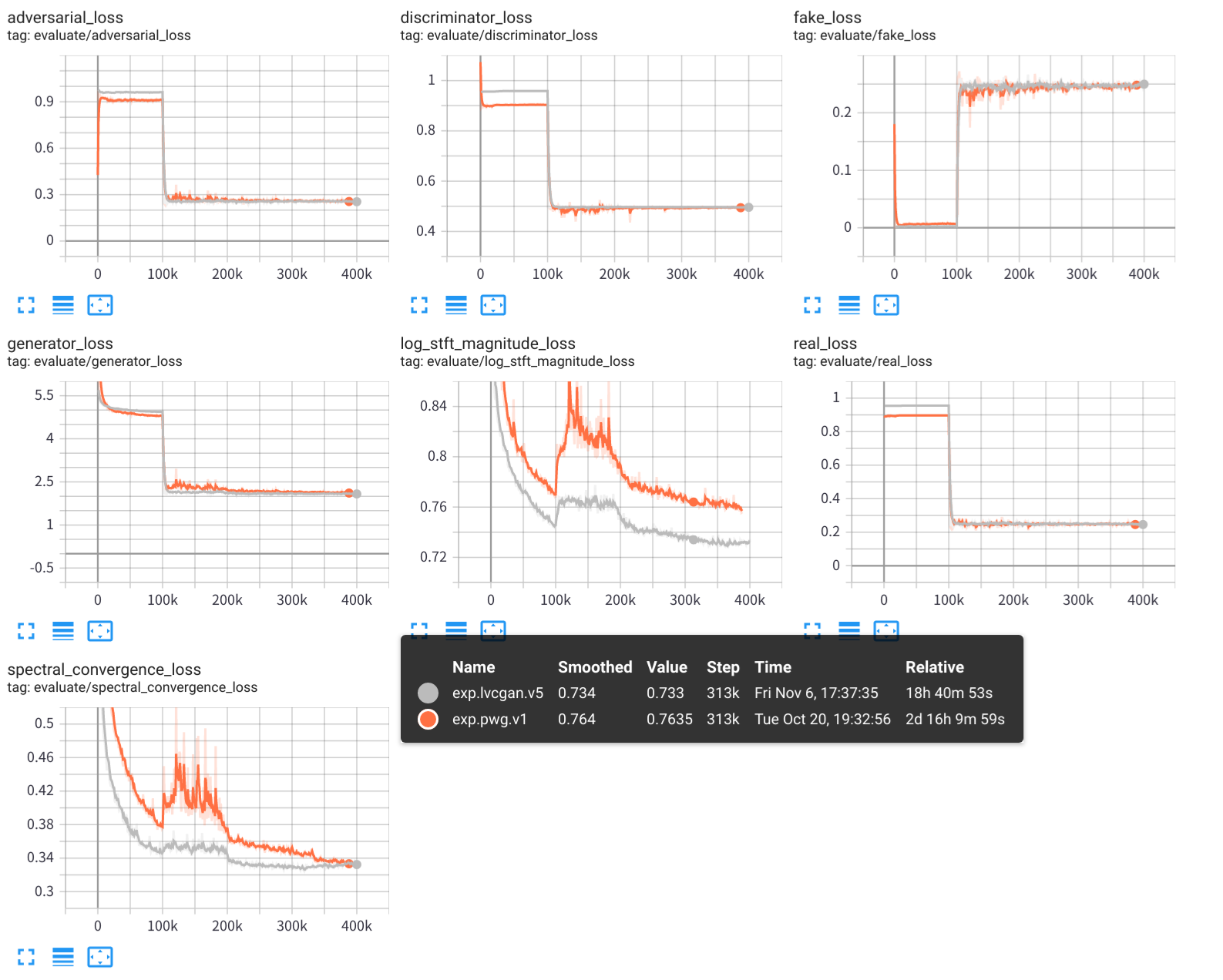
يتم حفظ عينات الصوت في samples/ ، حيث
samples/*_lvc.wav بواسطة LVCNET ،samples/*_pwg.wav بواسطة Wavegan المتوازي ،samples/*_real.wav هي الصوت الحقيقي. LVCNET: شبكة النمذجة المعتمدة على الحالة لتوليد الموجة ، https://arxiv.org/abs/2102.10815
Melglow: شبكة توليد موجة فعالة استنادًا إلى الالتفاف المتغير الموقع ، https://arxiv.org/abs/2012.01684
https://github.com/kan-bayashi/Parallelwavegan
https://github.com/lmnt-com/diffwave


