LVCNet
1.0.0
LVCNET을 사용하여 평행 파간의 생성기와이를 훈련시키기위한 동일한 전략을 설계하는 새로운 보코더의 추론 속도는 오디오 품질의 저하없이 원래 보코더보다 5 배 이상 빠릅니다 .
현재 작품 [종이]은 ICASSP2021에 의해 받아 들여졌으며 이전 작품은 Melglow에 설명되었습니다.
데이터를 준비하고 https://keithito.com/lj-speech-dataset/에서 LJSpeech 데이터 세트를 다운로드하고 data/LJSpeech-1.1 에 저장하십시오. 그런 다음 실행하십시오
python - m vocoder . preprocess - - data - dir . / data / LJSpeech - 1.1 - - config configs / lvcgan . v1 . yaml mel-sepctrums는 폴더 temp/ 에 계산되고 저장됩니다.
LVCNET 교육
python - m vocoder . train - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1LVCNET을 테스트하십시오
python - m vocoder . test - - config configs / lvcgan . v1 . yaml - - exp - dir exps / exp . lvcgan . v1 교육 로그, 모델 체크 포인트 및 합성 오디오를 포함한 실험 결과는 폴더 exps/exp.lvcgan.v1/ 에 저장됩니다.
유사성, 구성 파일 configs/pwg.v1.yaml 사용하여 병렬 Wavegan 모델을 훈련시킬 수도 있습니다.
# training
python - m vocoder . train - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1
# test
python - m vocoder . test - - config configs / pwg . v1 . yaml - - exp - dir exps / exp . pwg . v1 텐서 보드를 사용하여 실험 훈련 과정을보십시오.
tensorboard --logdir exps
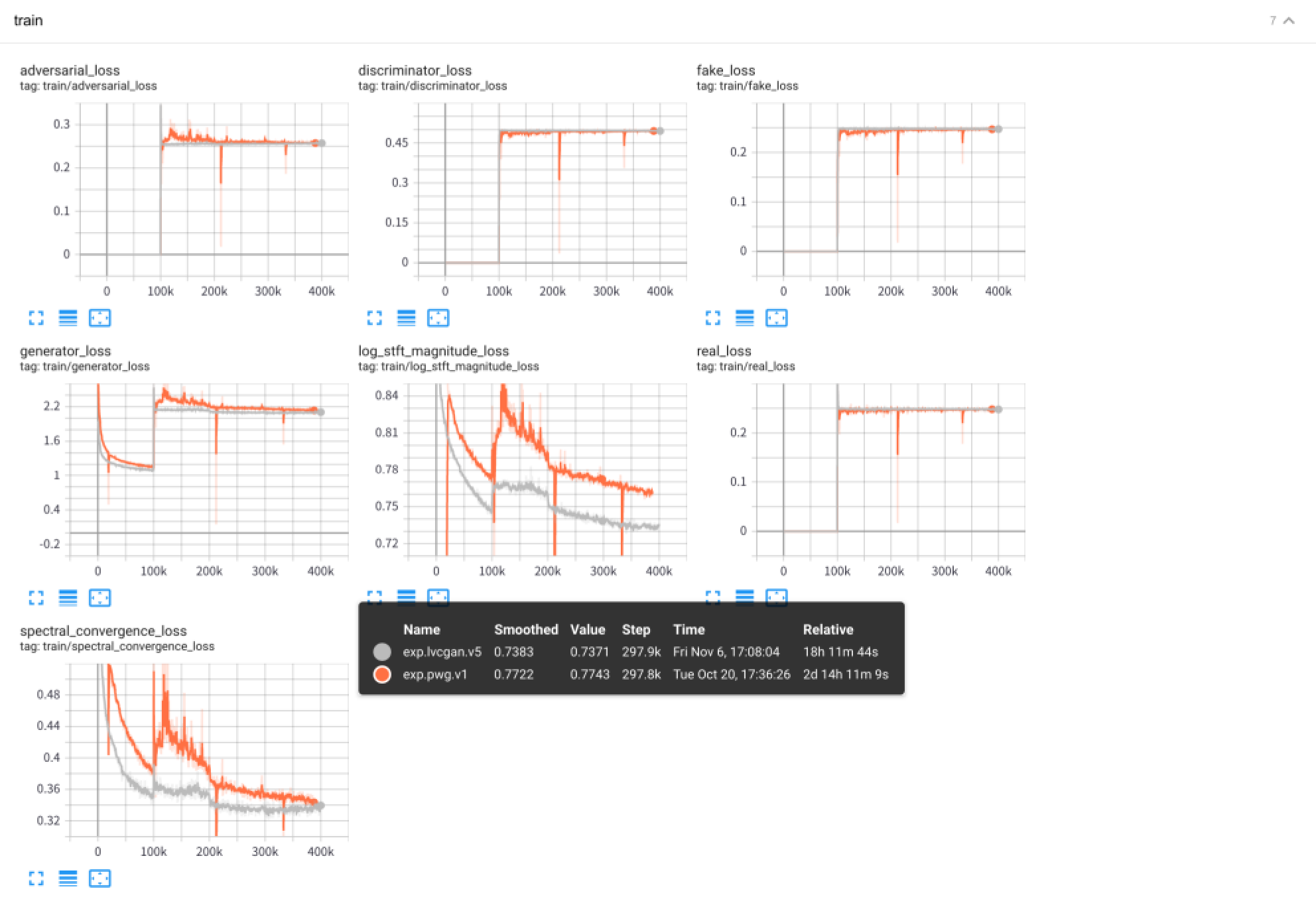
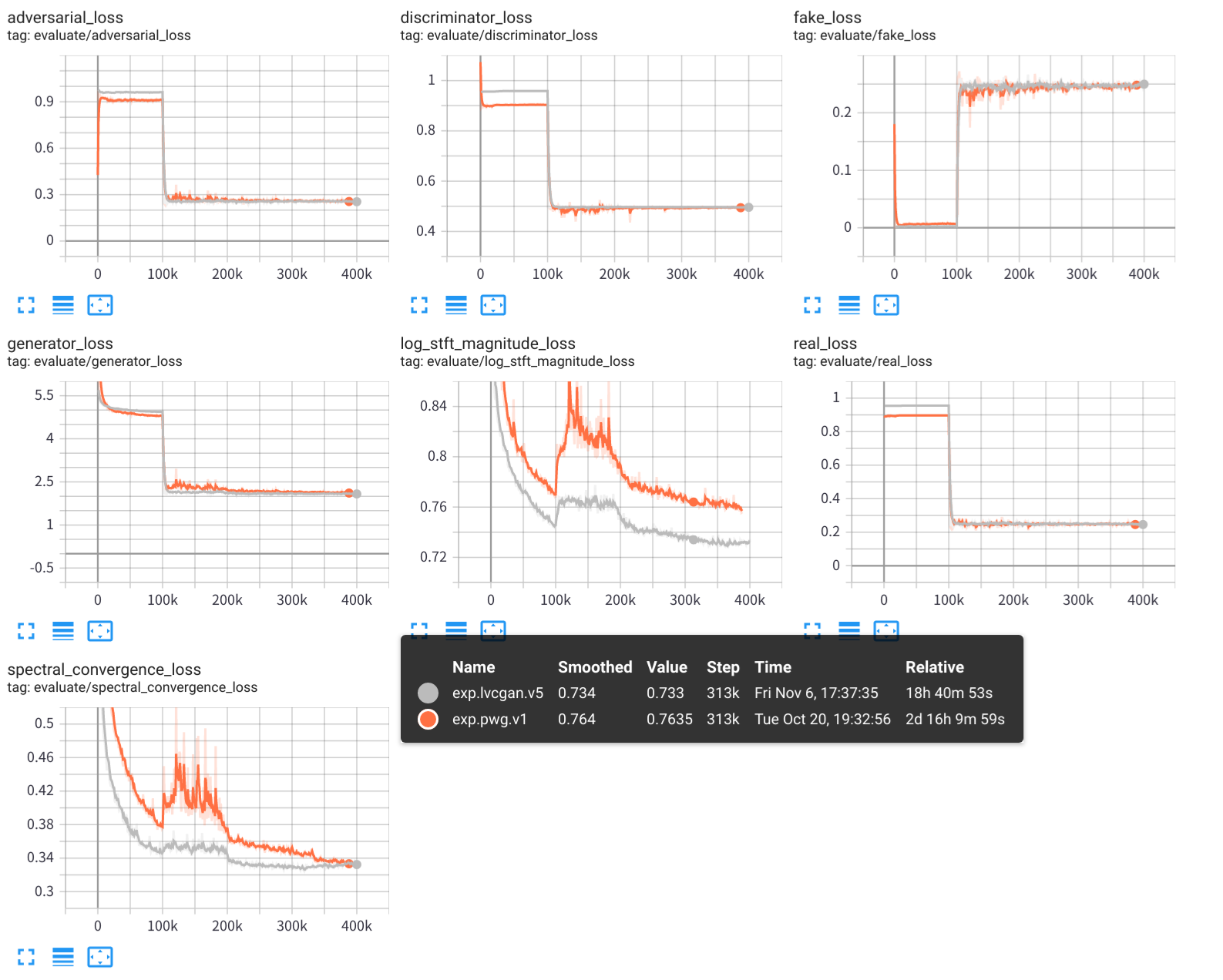
오디오 샘플은 samples/ , 어디에 저장됩니다
samples/*_lvc.wav 는 lvcnet에 의해 생성됩니다.samples/*_pwg.wav 평행 파간에 의해 생성됩니다.samples/*_real.wav 는 실제 오디오입니다. LVCNET : 파형 생성을위한 효율적인 조건-의존적 모델링 네트워크, https://arxiv.org/abs/2102.10815
Melglow : 위치-변수 컨볼 루션을 기반으로 한 효율적인 파형 생성 네트워크, https://arxiv.org/abs/2012.01684
https://github.com/kan-bayashi/parallelwavegan
https://github.com/lmnt-com/diffwave


