vall e
1.0.0
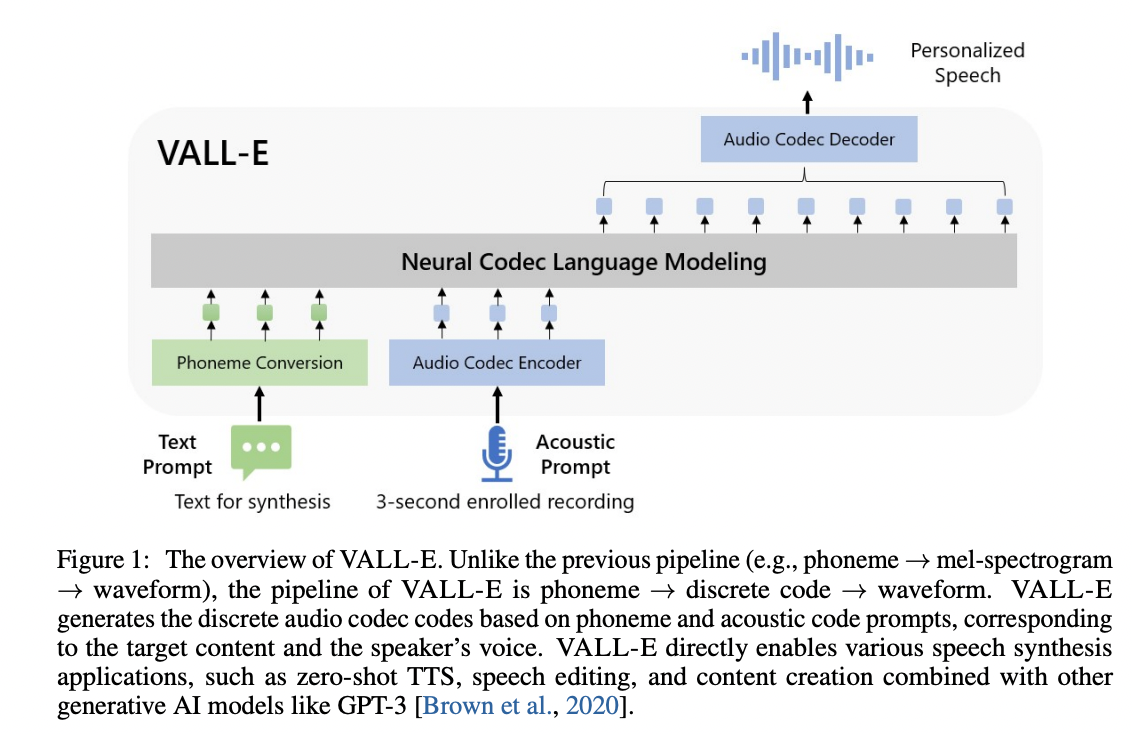
基於Encodec Tokenizer的VALL-E的非正式Pytorch實現。
玩具Google Colab示例:。請注意,此示例在
data/test下過多地說出了單個話語,並且不可用。預驗證的模型尚未到來。
由於培訓師是基於DeepSpeed的,因此您需要對DeepSpeed開發和測試的GPU,以及預先安裝的CUDA或ROCM編譯器以安裝此軟件包。
pip install git+https://github.com/enhuiz/vall-e
或者您可以通過:
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
請注意,該代碼僅在Python 3.10.7下進行測試。
將數據放入文件夾中,例如data/your_data 。音頻文件應使用後綴.wav和.normalized.txt命名。
量化數據:
python -m vall_e.emb.qnt data/your_data
python -m vall_e.emb.g2p data/your_data
通過創建config/your_data/ar.yml和config/your_data/nar.yml來自定義配置。有關詳細信息,請參閱config/test和vall_e/config.py中的示例配置。您可以選擇不同的型號預設,請檢查vall_e/vall_e/__init__.py 。
使用以下腳本訓練AR或NAR模型:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
您可以隨時僅通過在CLI中quit來退出培訓。最新的檢查點將自動保存。
兩種訓練有素的模型都需要導出到某個路徑。要導出其中的任何一個,請運行:
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
這將導出最新的檢查點。
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
@article { wang2023neural ,
title = { Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers } ,
author = { Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others } ,
journal = { arXiv preprint arXiv:2301.02111 } ,
year = { 2023 }
} @article { defossez2022highfi ,
title = { High Fidelity Neural Audio Compression } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2210.13438 } ,
year = { 2022 }
}

