vall e
1.0.0
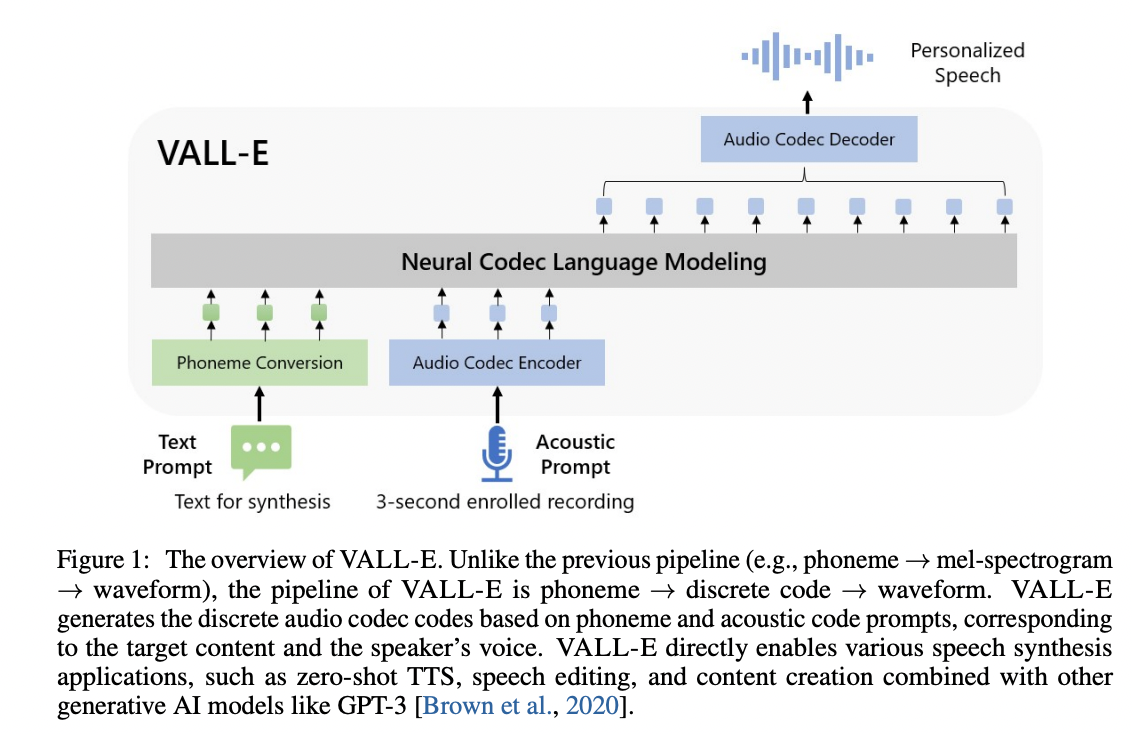
Encodec 토큰 화기를 기반으로 Vall-E의 비공식 Pytorch 구현.
장난감 Google Colab 예 :. 이 예는
data/test에서 단일 발화를 과도하게 유지하며 사용할 수 없습니다. 사전 예방 모델은 아직 오지 않았습니다.
트레이너는 DeepSpeed를 기반으로하기 때문에 DeepSpeed가 개발하고 테스트 한 GPU 와이 패키지를 설치하기 위해 사전 설치된 CUDA 또는 ROCM 컴파일러에 대해 테스트해야합니다.
pip install git+https://github.com/enhuiz/vall-e
또는 다음과 같이 복제 할 수 있습니다.
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
코드는 Python 3.10.7 에서만 테스트됩니다.
데이터를 폴더 (예 : data/your_data 에 넣으십시오. 오디오 파일은 접미사 .wav 및 텍스트 파일로 .normalized.txt 가진 텍스트 파일로 명명되어야합니다.
데이터를 정량화하십시오 :
python -m vall_e.emb.qnt data/your_data
python -m vall_e.emb.g2p data/your_data
config/your_data/ar.yml 및 config/your_data/nar.yml 작성하여 구성을 사용자 정의하십시오. 자세한 내용은 config/test 및 vall_e/config.py 의 예제 구성을 참조하십시오. 다른 모델 사전 설정을 선택하고 vall_e/vall_e/__init__.py 점검 할 수 있습니다.
다음 스크립트를 사용하여 AR 또는 NAR 모델을 교육하십시오.
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
CLI에 quit 입력하여 언제든지 훈련을 중단 할 수 있습니다. 최신 체크 포인트는 자동으로 저장됩니다.
두 훈련 된 모델 모두 특정 경로로 내보야합니다. 둘 중 하나를 내보내려면 실행하십시오.
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
이것은 최신 체크 포인트를 내보낼 것입니다.
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
@article { wang2023neural ,
title = { Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers } ,
author = { Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others } ,
journal = { arXiv preprint arXiv:2301.02111 } ,
year = { 2023 }
} @article { defossez2022highfi ,
title = { High Fidelity Neural Audio Compression } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2210.13438 } ,
year = { 2022 }
}

