vall e
1.0.0
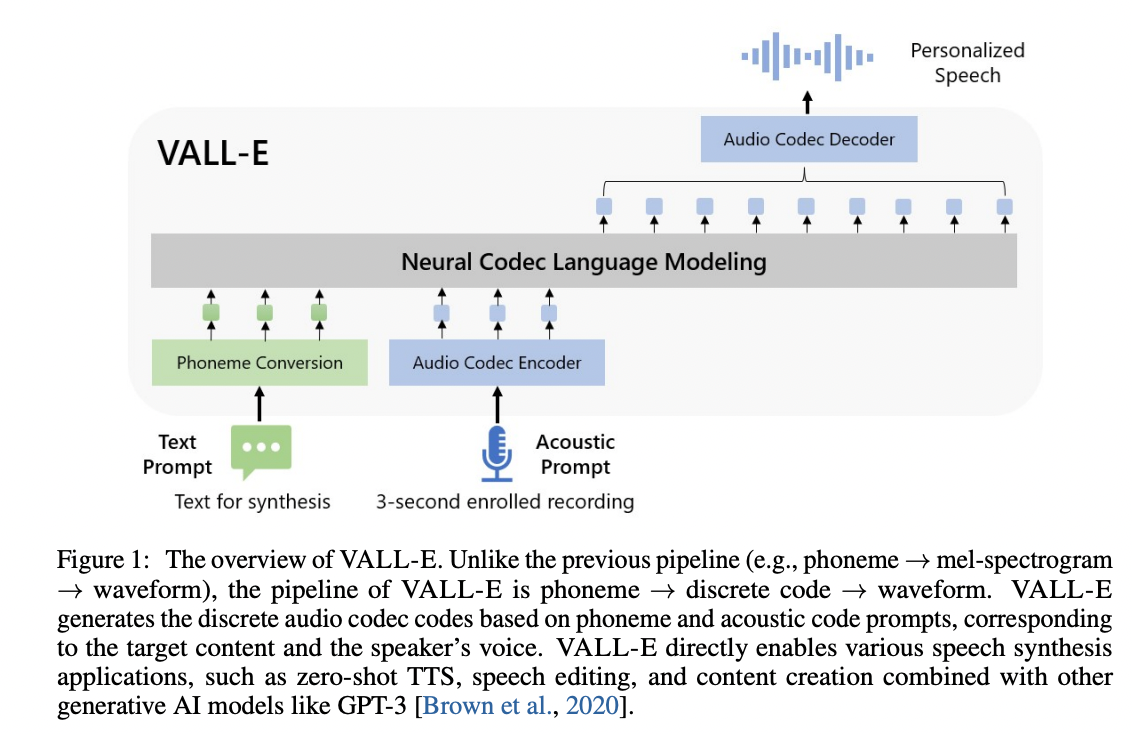
Eine inoffizielle Pytorch-Implementierung von Vall-E, basierend auf dem Encodec-Tokenizer.
Ein Spielzeug Google Colab Beispiel :. Bitte beachten Sie, dass dieses Beispiel eine einzige Äußerung unter den
data/testübertroffen und nicht verwendbar ist. Das vorbereitete Modell kommt noch.
Da der Trainer auf DeepSpeed basiert, müssen Sie eine GPU haben, gegen die DeepSpeed entwickelt und getestet hat, sowie einen CUDA- oder ROCM-Compiler, der vorinstalliert ist, um dieses Paket zu installieren.
pip install git+https://github.com/enhuiz/vall-e
Oder Sie können klonen durch:
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
Beachten Sie, dass der Code nur unter Python 3.10.7 getestet wird.
Legen Sie Ihre Daten in einen Ordner, z. B. data/your_data . Audiodateien sollten mit dem Suffix .wav und Textdateien mit .normalized.txt benannt werden.
Die Daten quantisieren:
python -m vall_e.emb.qnt data/your_data
python -m vall_e.emb.g2p data/your_data
Passen Sie Ihre Konfiguration an, indem Sie config/your_data/ar.yml und config/your_data/nar.yml erstellen. Weitere Informationen finden Sie in den Beispielkonfigurationen in config/test und vall_e/config.py . Sie können verschiedene Modellvoreinstellungen auswählen vall_e/vall_e/__init__.py
Trainieren Sie das AR- oder NAR -Modell mit den folgenden Skripten:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
Sie können Ihr Training jederzeit kündigen, indem Sie einfach in Ihrer CLI quit eingeben. Der neueste Kontrollpunkt wird automatisch gespeichert.
Beide geschulten Modelle müssen auf einen bestimmten Weg exportiert werden. Um einen von ihnen zu exportieren, rennen Sie:
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
Dadurch wird der neueste Kontrollpunkt exportiert.
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
@article { wang2023neural ,
title = { Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers } ,
author = { Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others } ,
journal = { arXiv preprint arXiv:2301.02111 } ,
year = { 2023 }
} @article { defossez2022highfi ,
title = { High Fidelity Neural Audio Compression } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2210.13438 } ,
year = { 2022 }
}

