vall e
1.0.0
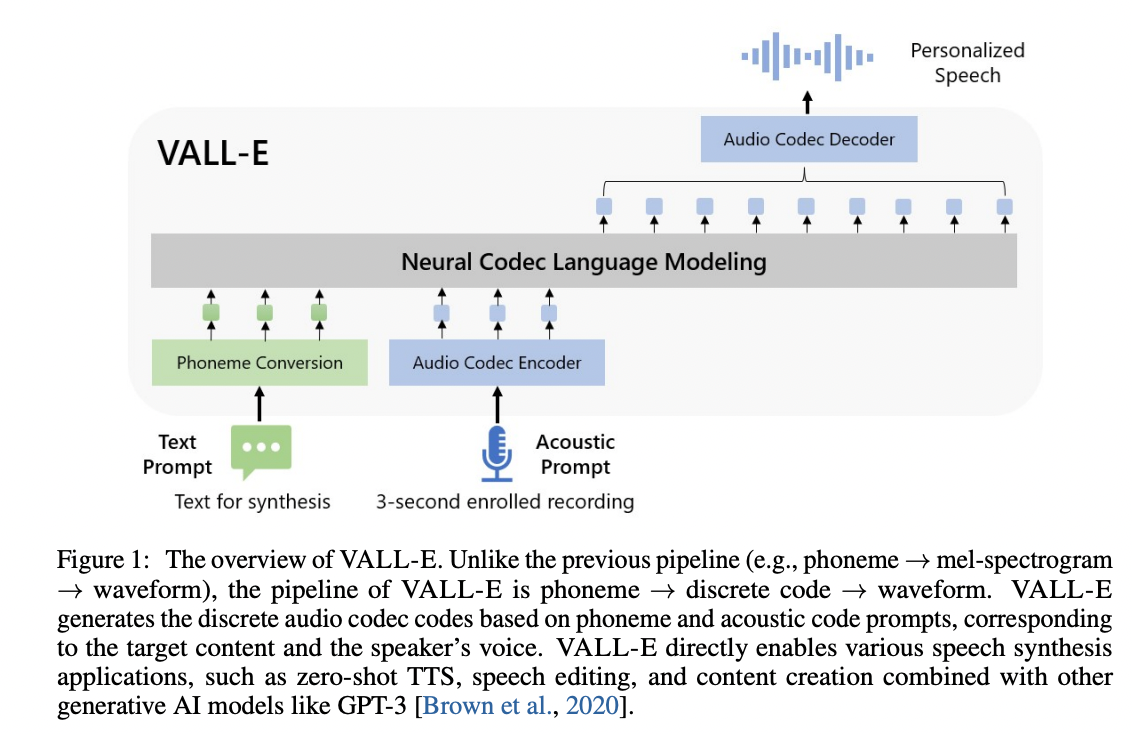
Uma implementação não oficial de Pytorch do Vall-E, com base no tokenizador do Encodec.
Um brinquedo Google Colab Exemplo :. Observe que este exemplo exagera um único enunciado sob os
data/teste não é utilizável. O modelo pré -treinado ainda está por vir.
Como o treinador é baseado no DeepSpeed, você precisará ter uma GPU que o DeepSpeed desenvolveu e testou, bem como um compilador CUDA ou ROCM pré-instalado para instalar este pacote.
pip install git+https://github.com/enhuiz/vall-e
Ou você pode clonar por:
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
Observe que o código é testado apenas em Python 3.10.7 .
Coloque seus dados em uma pasta, por exemplo, data/your_data . Os arquivos de áudio devem ser nomeados com o sufixo .wav e arquivos de texto com .normalized.txt .
Quantize os dados:
python -m vall_e.emb.qnt data/your_data
python -m vall_e.emb.g2p data/your_data
Personalize sua configuração criando config/your_data/ar.yml e config/your_data/nar.yml . Consulte as configurações de exemplo em config/test e vall_e/config.py para obter detalhes. Você pode escolher diferentes predefinições de modelo, verifique vall_e/vall_e/__init__.py .
Treine o modelo AR ou NAR usando os seguintes scripts:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
Você pode desistir do seu treinamento a qualquer momento, apenas quit em sua CLI. O ponto de verificação mais recente será salvo automaticamente.
Ambos os modelos treinados precisam ser exportados para um determinado caminho. Para exportar qualquer um deles, corra:
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
Isso exportará o ponto de verificação mais recente.
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
@article { wang2023neural ,
title = { Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers } ,
author = { Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others } ,
journal = { arXiv preprint arXiv:2301.02111 } ,
year = { 2023 }
} @article { defossez2022highfi ,
title = { High Fidelity Neural Audio Compression } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2210.13438 } ,
year = { 2022 }
}

