vall e
1.0.0
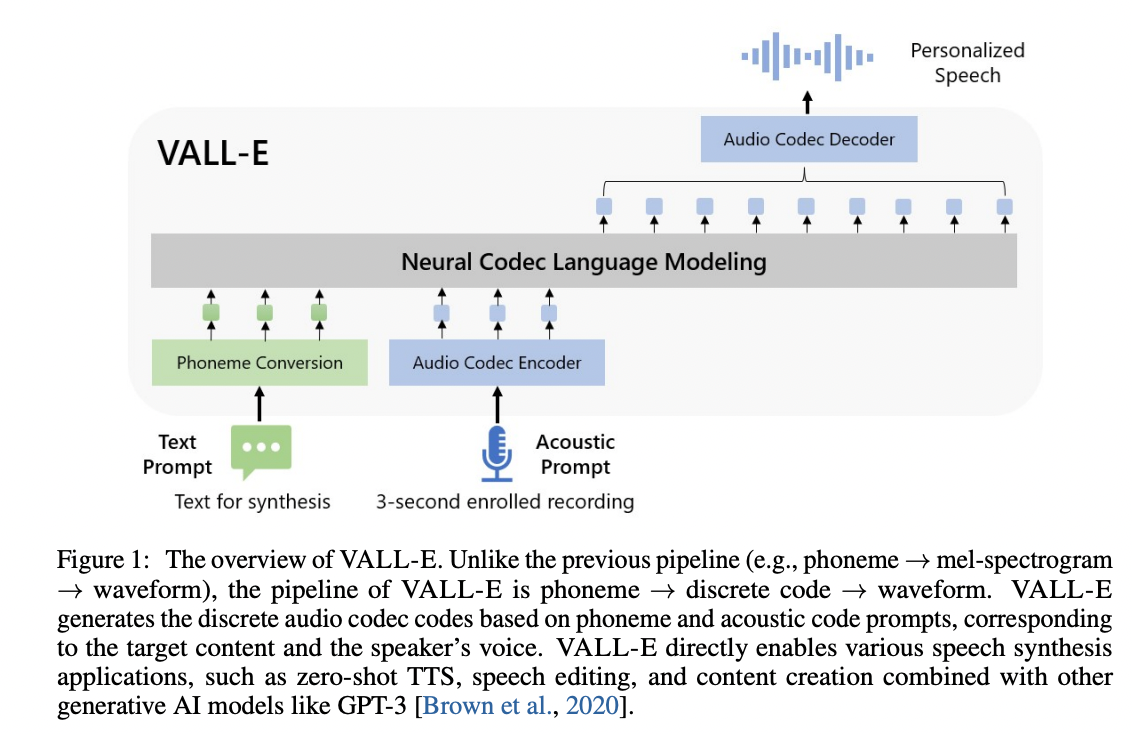
Encodecトークン剤に基づいたVall-Eの非公式のPytorch実装。
おもちゃのGoogle Colabの例:。この例は、
data/testの下で単一の発話を覆し、使用できないことに注意してください。前提条件のモデルはまだ来ていません。
トレーナーはDeepSpeedに基づいているため、DeepSpeedが開発およびテストしたGPUと、このパッケージをインストールするために事前にインストールされたCUDAまたはROCMコンパイラが必要です。
pip install git+https://github.com/enhuiz/vall-e
または、次のようにクローンできます。
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
コードはPython 3.10.7でのみテストされていることに注意してください。
データをフォルダー( data/your_dataに入れます。オーディオファイルは、suffix .wavおよび.normalized.txtを使用したテキストファイルで名前を付けてください。
データの量子化:
python -m vall_e.emb.qnt data/your_data
python -m vall_e.emb.g2p data/your_data
config/your_data/ar.yml and config/your_data/nar.ymlを作成して、構成をカスタマイズします。詳細については、 config/testとvall_e/config.pyの例を参照してください。さまざまなモデルプリセットを選択して、 vall_e/vall_e/__init__.pyを確認できます。
次のスクリプトを使用して、ARまたはNARモデルをトレーニングします。
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
CLIでquitだけで、いつでもトレーニングをやめることができます。最新のチェックポイントは自動的に保存されます。
両方の訓練されたモデルは、特定のパスにエクスポートする必要があります。それらのいずれかをエクスポートするには、実行してください。
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
これにより、最新のチェックポイントがエクスポートされます。
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
@article { wang2023neural ,
title = { Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers } ,
author = { Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others } ,
journal = { arXiv preprint arXiv:2301.02111 } ,
year = { 2023 }
} @article { defossez2022highfi ,
title = { High Fidelity Neural Audio Compression } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2210.13438 } ,
year = { 2022 }
}

