vall e
1.0.0
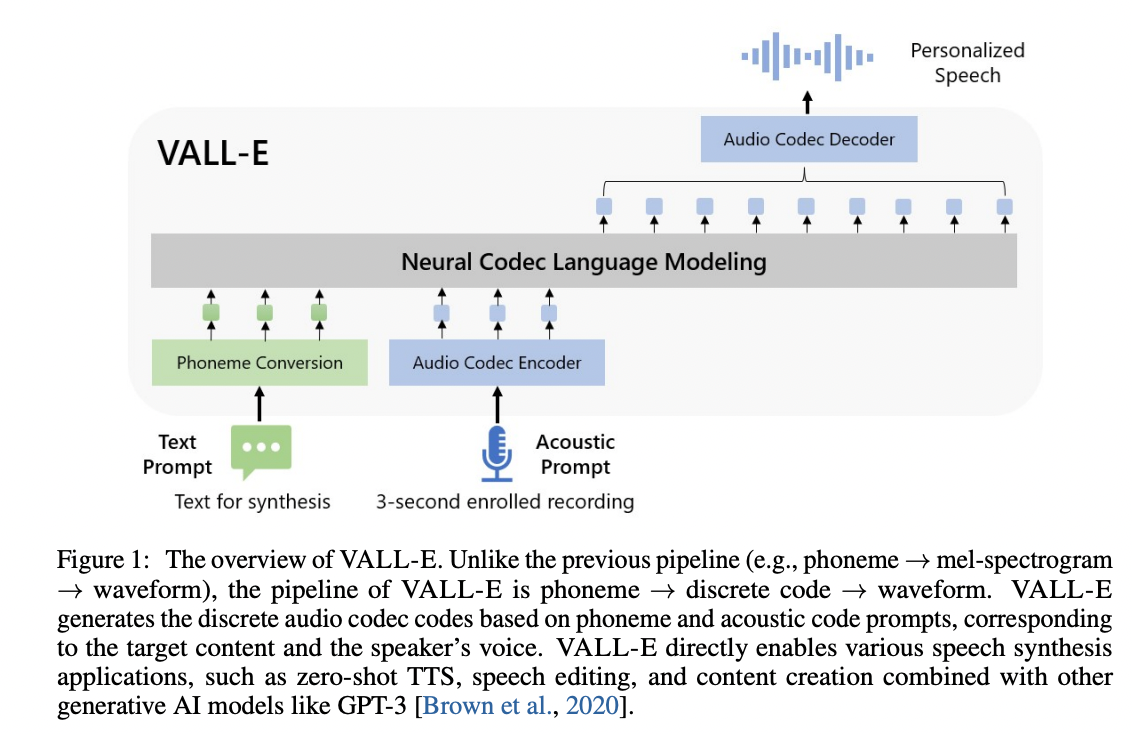
Une mise en œuvre non officielle de Pytorch de Vall-E, basée sur le tokenizer encode.
Un jouet Google Colab Exemple :. Veuillez noter que cet exemple survole un seul énoncé sous les
data/testet n'est pas utilisable. Le modèle pré-entraîné est encore à venir.
Étant donné que l'entraîneur est basé sur Deeppeed, vous devrez avoir un GPU contre lequel Deeppeed a développé et testé, ainsi qu'un compilateur CUDA ou ROCM préinstallé pour installer ce package.
pip install git+https://github.com/enhuiz/vall-e
Ou vous pouvez cloner par:
git clone --recurse-submodules https://github.com/enhuiz/vall-e.git
Notez que le code n'est testé que sous Python 3.10.7 .
Mettez vos données dans un dossier, par exemple data/your_data . Les fichiers audio doivent être nommés avec le suffixe .wav et les fichiers texte avec .normalized.txt .
Quantifier les données:
python -m vall_e.emb.qnt data/your_data
python -m vall_e.emb.g2p data/your_data
Personnalisez votre configuration en créant config/your_data/ar.yml et config/your_data/nar.yml . Reportez-vous aux configurations d'exemples dans config/test et vall_e/config.py pour plus de détails. Vous pouvez choisir différents préréglages de modèles, vérifier vall_e/vall_e/__init__.py .
Former le modèle AR ou NAR à l'aide des scripts suivants:
python -m vall_e.train yaml=config/your_data/ar_or_nar.yml
Vous pouvez quitter votre entraînement à tout moment en tapant simplement quit votre CLI. Le dernier point de contrôle sera automatiquement enregistré.
Les deux modèles qualifiés doivent être exportés vers un certain chemin. Pour exporter l'un d'eux, courez:
python -m vall_e.export zoo/ar_or_nar.pt yaml=config/your_data/ar_or_nar.yml
Cela exportera le dernier point de contrôle.
python -m vall_e <text> <ref_path> <out_path> --ar-ckpt zoo/ar.pt --nar-ckpt zoo/nar.pt
@article { wang2023neural ,
title = { Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers } ,
author = { Wang, Chengyi and Chen, Sanyuan and Wu, Yu and Zhang, Ziqiang and Zhou, Long and Liu, Shujie and Chen, Zhuo and Liu, Yanqing and Wang, Huaming and Li, Jinyu and others } ,
journal = { arXiv preprint arXiv:2301.02111 } ,
year = { 2023 }
} @article { defossez2022highfi ,
title = { High Fidelity Neural Audio Compression } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
journal = { arXiv preprint arXiv:2210.13438 } ,
year = { 2022 }
}

