Bayesian Neural Networks
1.0.0
Pytorch實現以下大約推斷方法:
我們還提供:
該項目用Python 2.7和Pytorch 1.0.1編寫。如果有CUDA可用,它將自動使用。這些模型也可以在CPU上運行,因為它們並不大。
我們在玩具數據集上進行了(高斯流程地面真相)以及實際數據(六個UCI數據集),在玩具數據集上進行了均勻的和異質的回歸體驗。
筆記本/分類/(modelName)_(實驗類型).ipynb :包含(實驗類型),即使用(modelName),即同型/異源性。異質的筆記本電腦包含給定(模型名稱)的玩具和UCI數據集實驗。
我們還提供Google Colab筆記本。這意味著您可以在GPU上運行(免費!)。無需修改 - 所有依賴項和數據集都是從筆記本中添加的 - 除了選擇運行時 - >更改運行時類型 - >硬件加速器 - > GPU。
train_(modelname)_(數據集).py :trains(模型名稱)(數據集)。培訓指標和模型權重將保存到指定的目錄。
SRC/ :通用實用程序和模型定義。
筆記本/分類:筆記本的延遲,可以進行模型培訓,數字旋轉不確定性實驗的評估和運行。它們還允許進行體重分佈塊和修剪。它們允許加載預訓練的模型進行實驗。
(https://arxiv.org/abs/1505.05424)
帶回歸模型的COLAB筆記本:BBP同型 /異質機
培訓MNIST的模型:
python train_BayesByBackprop_MNIST.py [--model [MODEL]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]為了解釋腳本的論點:
python train_BayesByBackprop_MNIST.py -h最好的結果是通過Laplace先驗獲得的。
(https://arxiv.org/abs/1506.02557)
反向推理的貝葉斯,其中的平均值和激活方差以封閉形式計算。激活是採樣而不是權重。這使得Monte Carlo Elbo估計量表的方差為1/m,其中m是Minibatch尺寸。採樣重量量表(M-1)/m。高斯人之間的KL差異也可以以封閉形式計算,從而進一步降低了方差。每個時期的計算速度更快,因此收斂。
培訓MNIST的模型:
python train_BayesByBackprop_MNIST.py --model Local_Reparam [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]](https://arxiv.org/abs/1506.02142)
設置了固定的輟學率為0.5。
帶回歸模型的COLAB筆記本:MC輟學均應異性彈藥
培訓MNIST的模型:
python train_MCDropout_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]為了解釋腳本的論點:
python train_MCDropout_MNIST.py -h(https://www.ics.uci.edu/~welling/publications/papers/stoclangevin_v6.pdf)
為了使其在W上融合到真正的後部,應根據Robbins-Monro條件將學習率退火。實際上,我們使用固定的學習率。
帶回歸模型的COLAB筆記本:SGLD同型 /異源性
培訓MNIST的模型:
python train_SGLD_MNIST.py [--use_preconditioning [USE_PRECONDITIONING]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]為了解釋腳本的論點:
python train_SGLD_MNIST.py -h(https://arxiv.org/abs/1512.07666)
帶有RMSPROP預處理的SGLD。與香草SGLD相比,應使用更高的學習率。
培訓MNIST的模型:
python train_SGLD_MNIST.py --use_preconditioning True [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]多個網絡對數據集的子樣本進行了培訓。
帶回歸模型的COLAB筆記本:地圖集成均應均勻 /異方差
培訓MNIST的合奏:
python train_Bootrap_Ensemble_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--subsample [SUBSAMPLE]] [--n_nets [N_NETS]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]為了解釋腳本的論點:
python train_Bootrap_Ensemble_MNIST.py -h(https://openreview.net/pdf?id=skdvd2xaz)
訓練一個地圖網絡,然後將二階Taylor系列aproxiamtion計算為圍繞後部模式的曲率。使用塊對角線黑森近似值,其中僅考慮了內部依賴性。黑森將進一步近似為單個數據點的Hessian因素的期望的Kronecker產品。近似Hessian可能需要一段時間。幸運的是,它只需要完成一次。
培訓MNIST和大約Hessian的地圖網絡:
python train_KFLaplace_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--hessian_diag_sig [HESSIAN_DIAG_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]為了解釋腳本的論點:
python train_KFLaplace_MNIST.py -h請注意,我們節省了未量化和未經啟動的Hessian因素。這將允許在推理時間對先前的計算廉價更改,因為不需要重新計算Hessian。推論將需要反轉近似的Hessian因子並從基質正態分佈中取樣。這在筆記本/kfac_laplace_mnist.ipynb中顯示
(https://arxiv.org/abs/1402.4102)
我們實現了該算法的尺度適應版本,在此提議在燃燒期間自動找到超參數。我們在高斯的精確度上放置了高斯先前的網絡權重和伽馬超級優勢。
運行SG-HMC-SA燃燒和採樣器,從而在指定文件中節省了權重。
python train_SGHMC_MNIST.py [--epochs [EPOCHS]] [--sample_freq [SAMPLE_FREQ]] [--burn_in [BURN_IN]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]為了解釋腳本的論點:
python train_SGHMC_MNIST.py -hMAP推斷提供了參數值的點估計值。當提供超出分佈輸入(例如旋轉數字)時,這些模型將以高度置信度進行錯誤的預測。
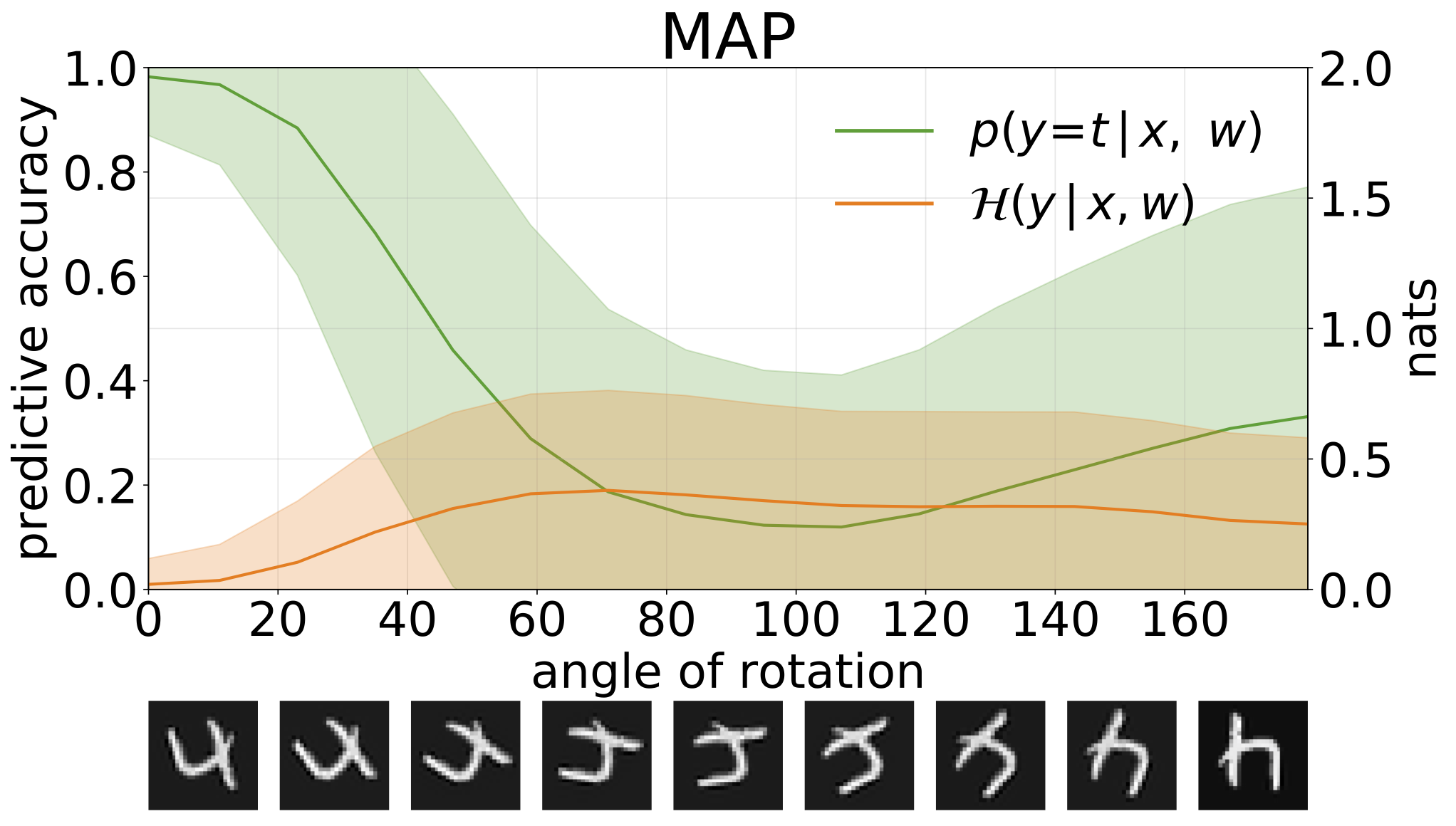
我們可以通過預測性熵來衡量模型預測的不確定性。我們可以分解此術語,以區分兩種類型的不確定性。可以將數據中噪聲或息肉不確定性引起的不確定性量化為模型預測的預期熵。模型的不確定性或認知不確定性可以測量為總熵和核熵之間的差異。
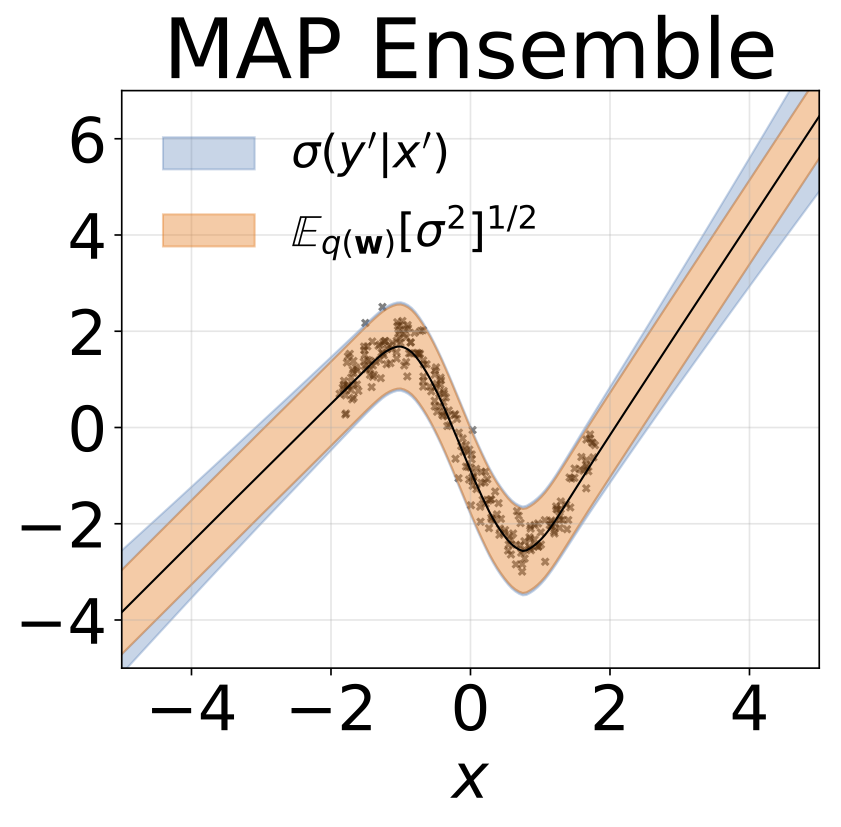
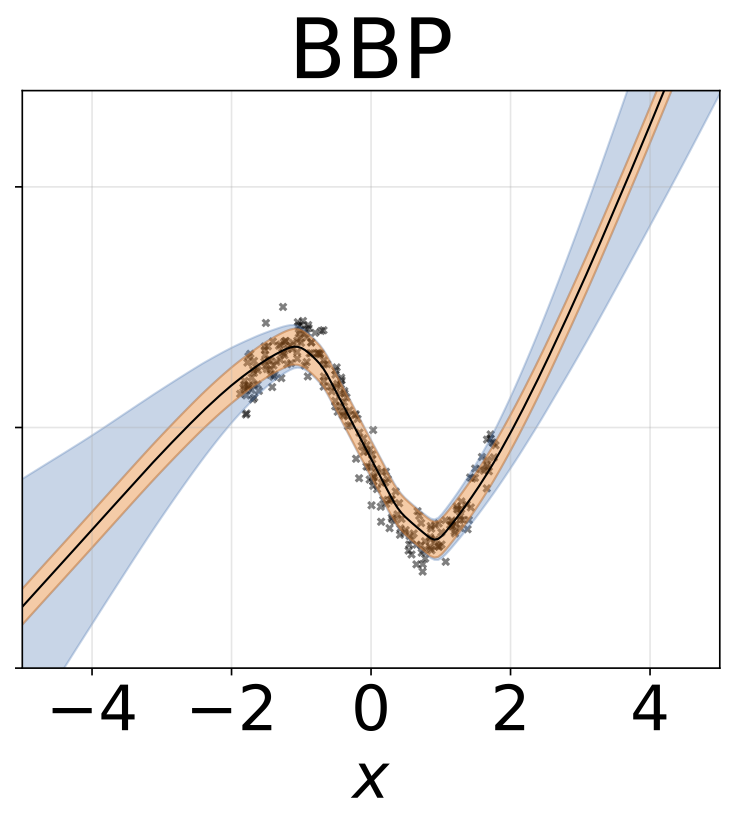
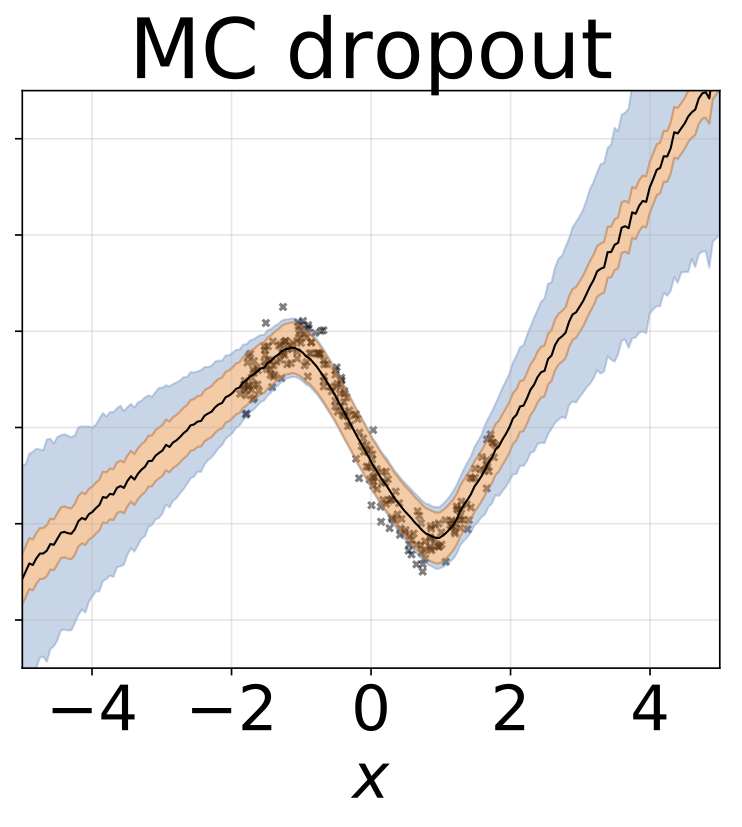
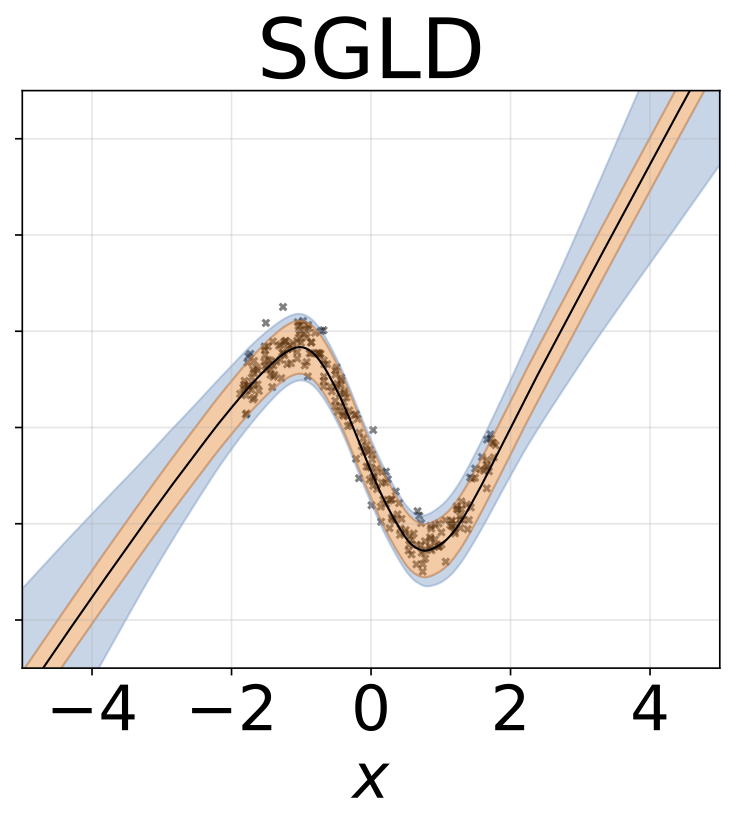
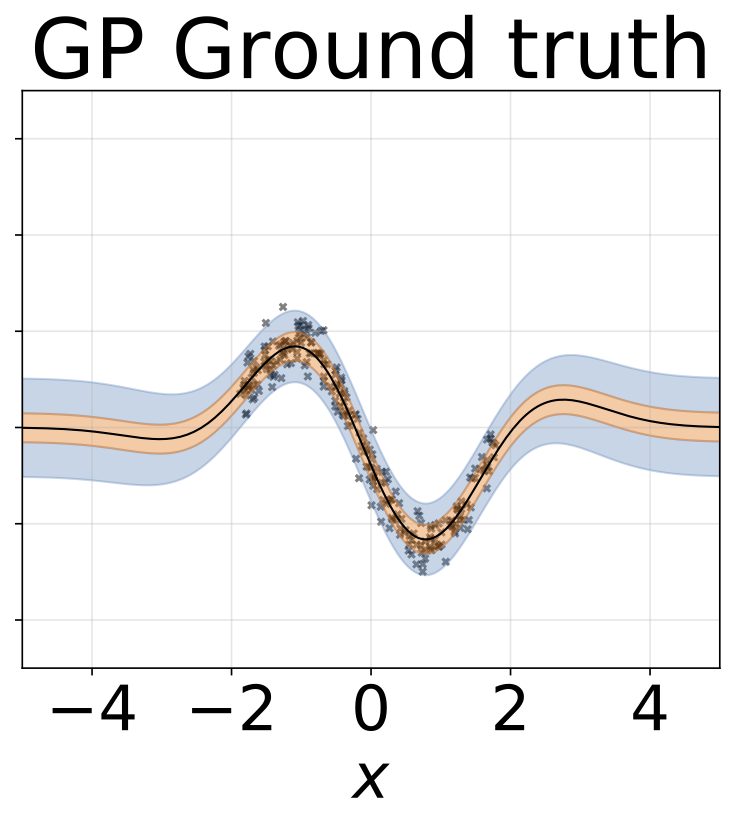
玩具同性戀回歸任務。數據由帶有RBF內核的GP生成(L = 1,σN= 0.3)。我們使用一個單輸出FC網絡,該網絡具有200個Relu單元的一個隱藏層,以預測回歸平均值μ(x)。固定的logσ分別學習。
與上一節相同的方案,但從輸入預測logσ(x)。
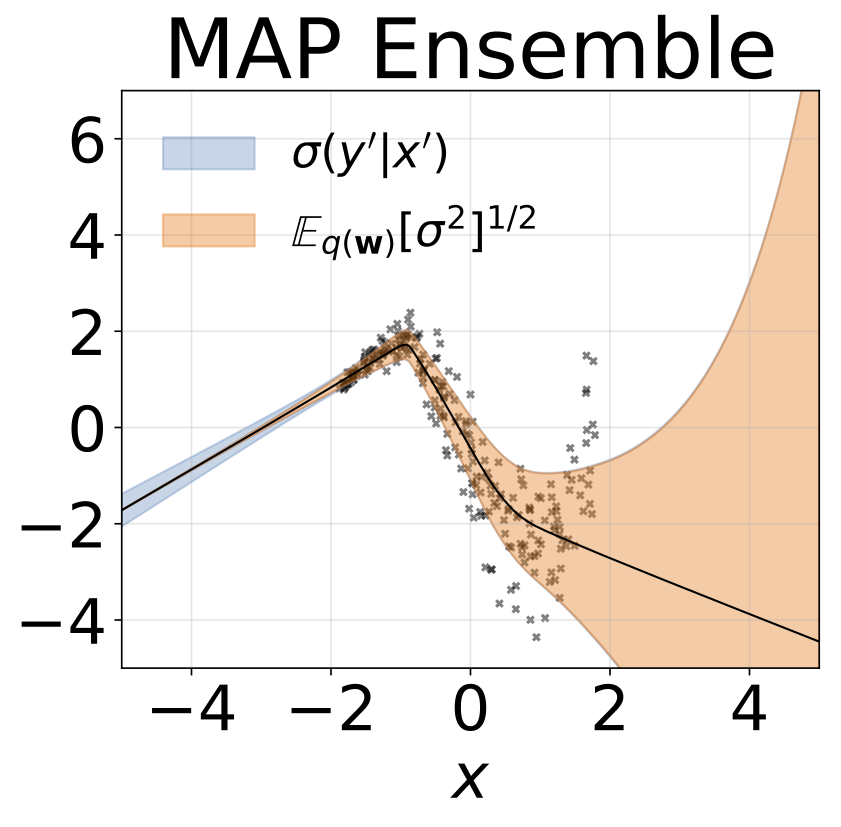
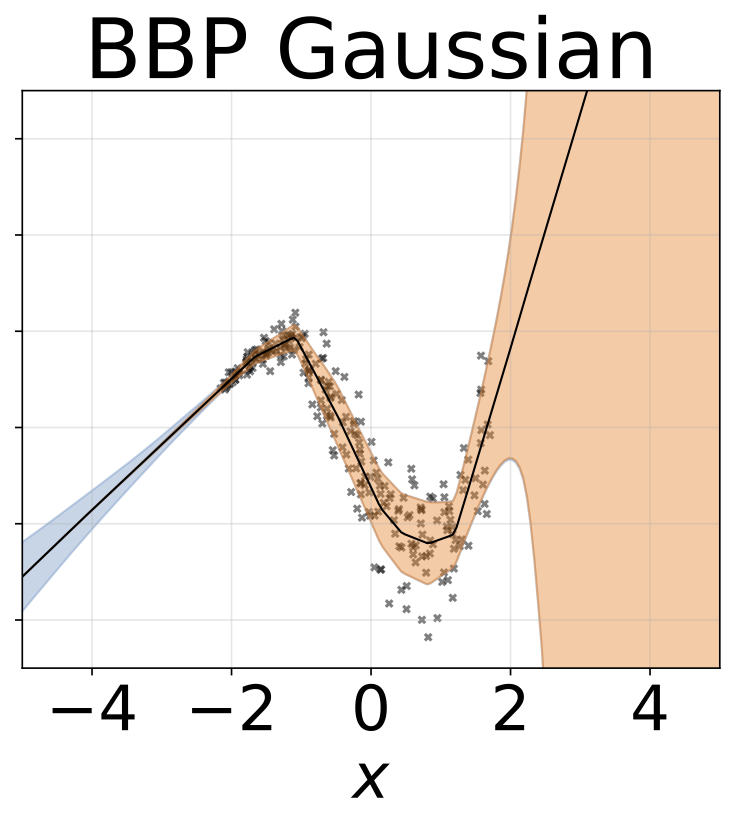
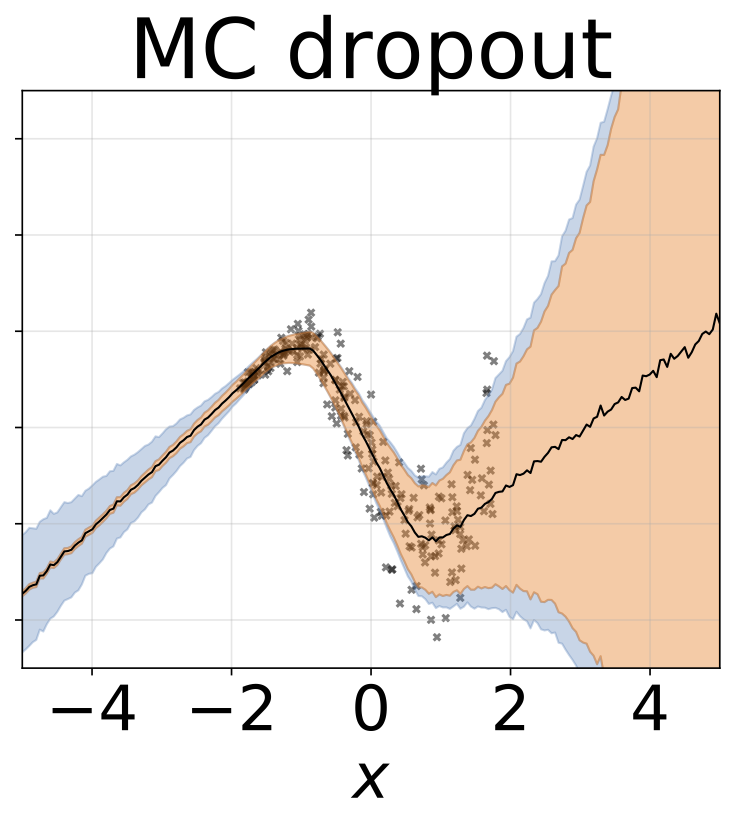
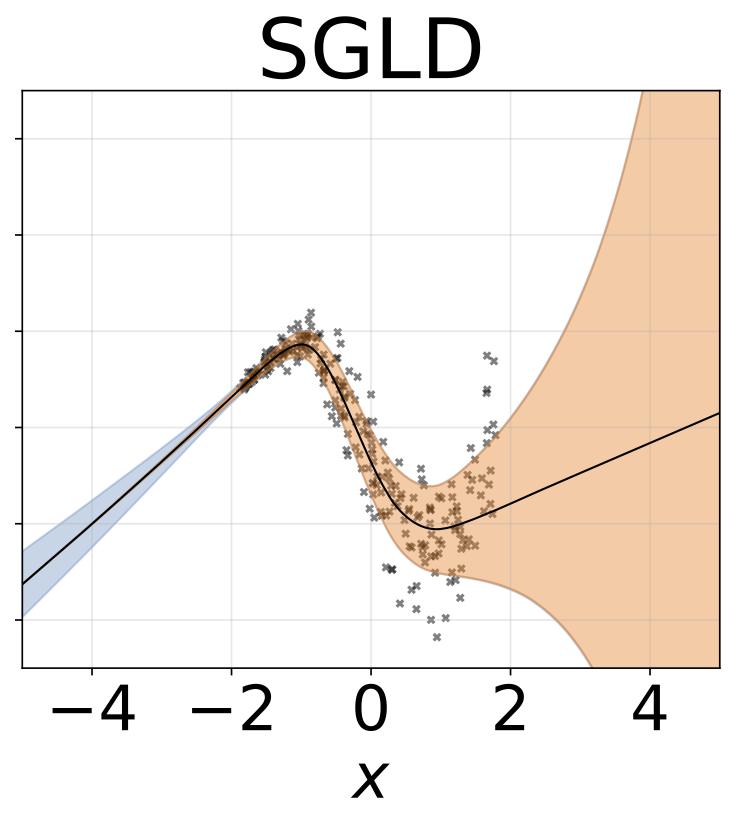
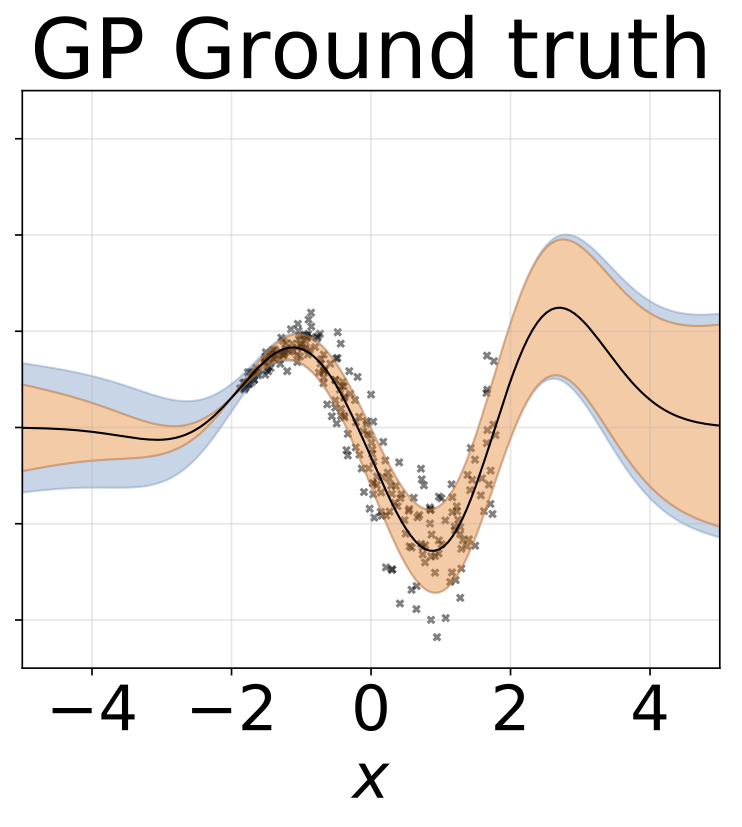
玩具異質的回歸任務。數據由帶有RBF內核的GP生成(L =1σN= 0.3·| x + 2 |)。我們使用具有200個relu單元的兩頭網絡來預測回歸平均值μ(x)和對數標準偏差logσ(x)。
我們使用10-Foild Cross驗證,對六個UCI數據集(外殼,混凝土,能源效率,發電廠,紅酒和遊艇數據集進行了異質分析回歸。所有這些實驗都包含在異性彈性筆記本中。請注意,結果在很大程度上取決於高參數的選擇。下面的圖顯示了火車上的對數可能性和RMSE(半透明的顏色)和測試(純色)。圓形和誤差條分別對應於10倍的交叉驗證平均值和標準偏差。
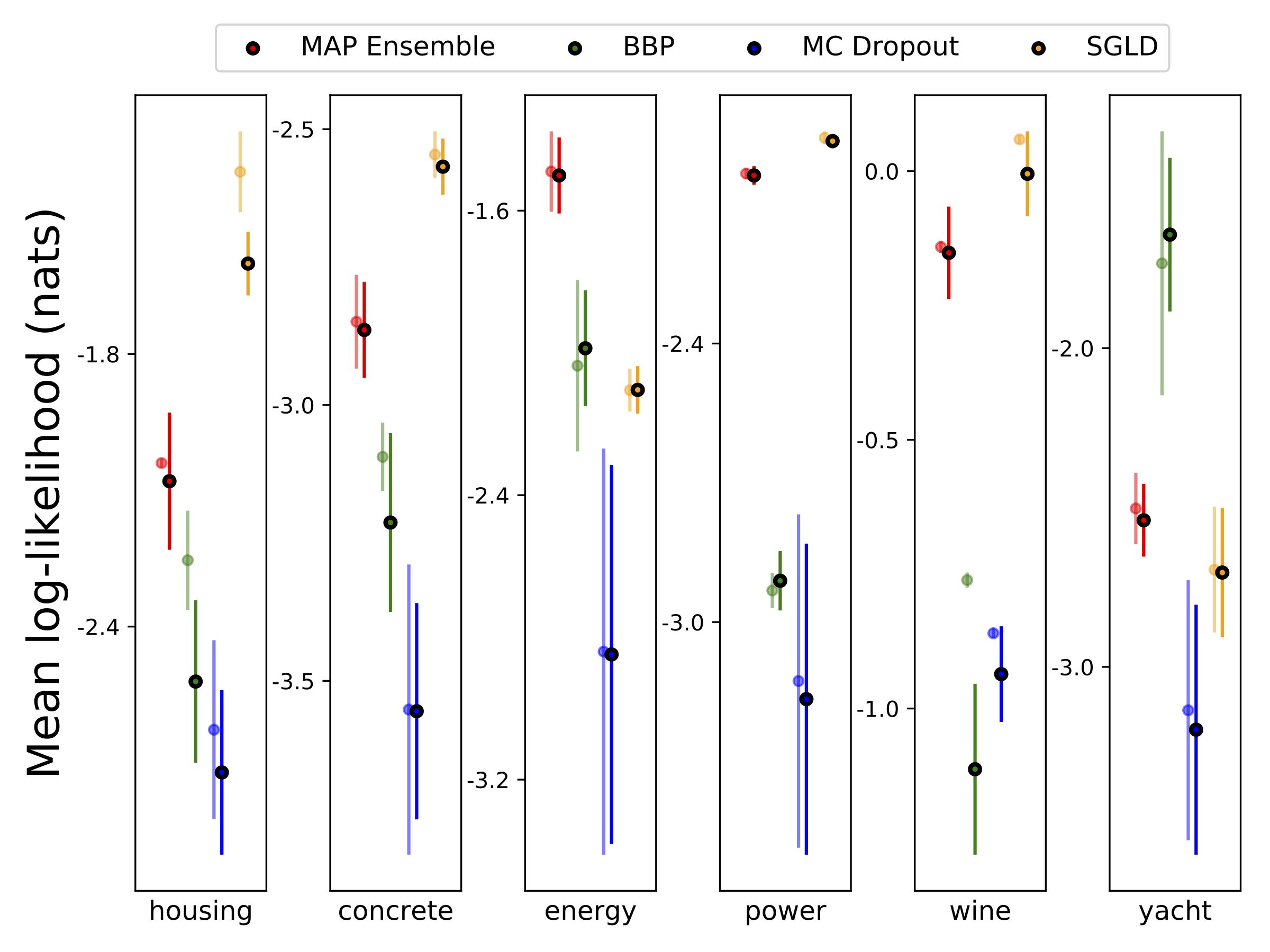
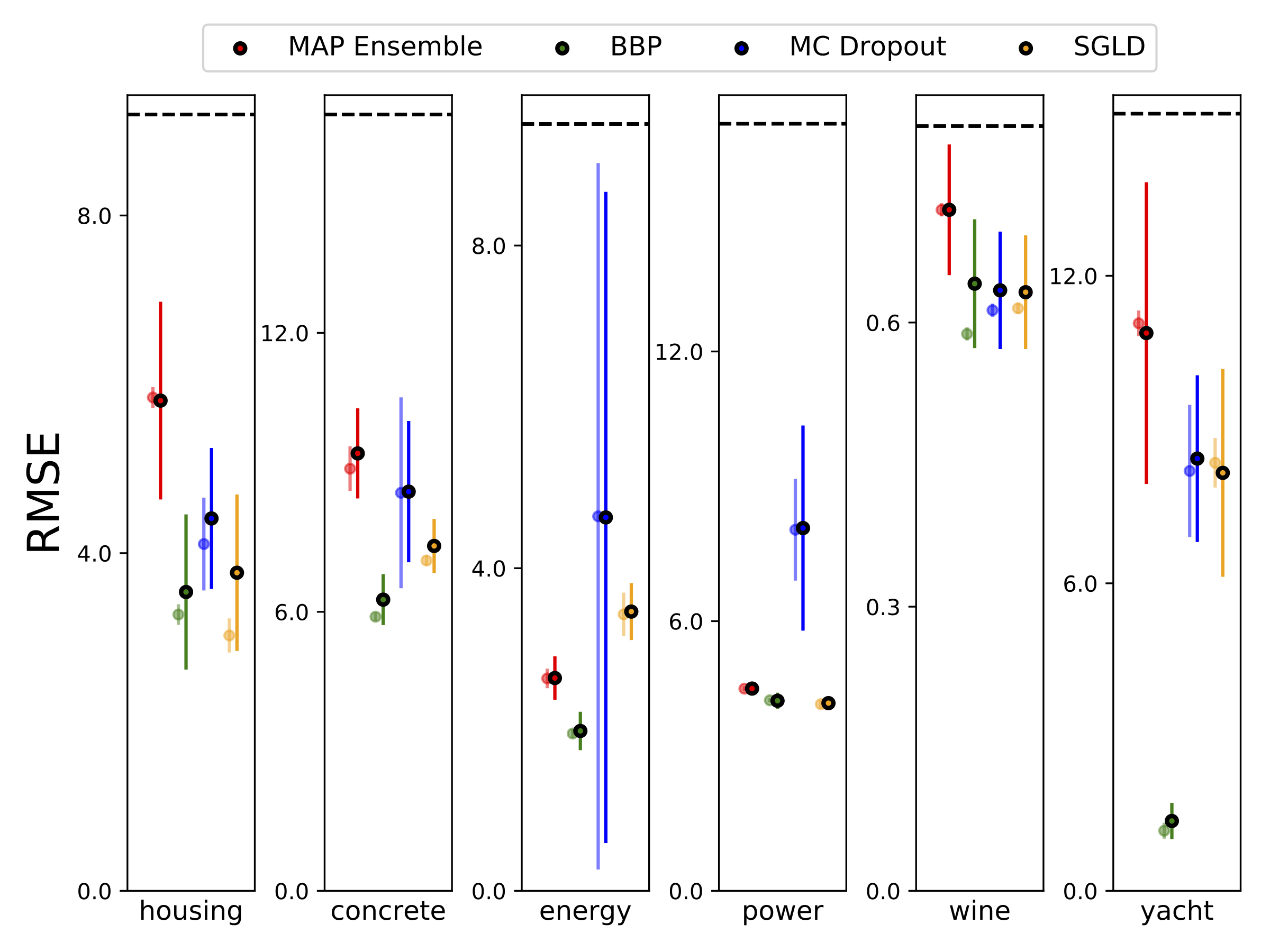
除了地圖外,所有模型的權重邊緣化,其中僅使用一組權重。
| MNIST測試 | 地圖 | 地圖合奏 | BBP高斯 | BBP GMM | BBP拉普拉斯 | BBP本地Reparam | MC輟學 | sgld | PSGLD |
|---|---|---|---|---|---|---|---|---|---|
| log喜歡 | -572.9 | -496.54 | -1100.29 | -1008.28 | -892.85 | -1086.43 | -435.458 | -828.29 | -661.25 |
| 錯誤 % | 1.58 | 1.53 | 2.60 | 2.38 | 2.28 | 2.61 | 1.37 | 1.76 | 1.76 |
MNIST測試結果正在考慮的方法。尚未執行Estangive Hyparameter Tunning。我們用100個MC樣品近似後驗預測分佈。我們使用具有兩個1200個單元旋轉層的FC網絡。如果未指定,則先驗是std = 0.1的高斯。 P-SGLD使用RMSPROP預處理。
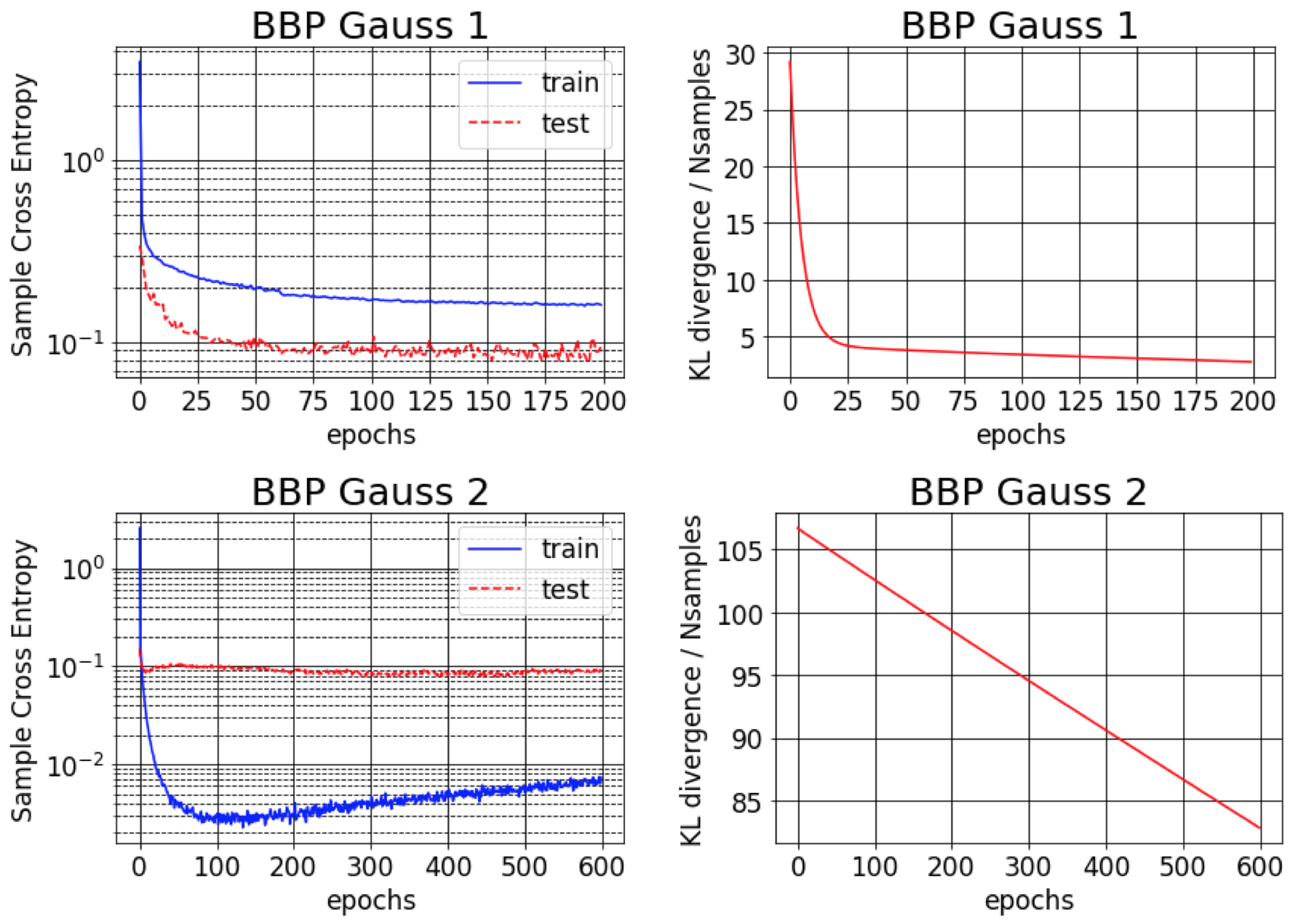
Backprop的貝葉斯原始紙報告報告了MNIST的1%錯誤。我們發現,只有在初始化的後差為小(BBP Gauss 2)時,才可以實現此結果。在這種情況下,權重的分佈類似於三角洲,提供了良好的預測性能,但不確定性估計不確定。但是,當初始化差異以匹配先驗的方差(BBP高斯1)時,我們獲得了上述結果。這兩種高參數配置方案的訓練曲線如下:
通過增加旋轉的MNIST測試集創建OOD樣品時,獲得的總,質和認知的不確定性是:
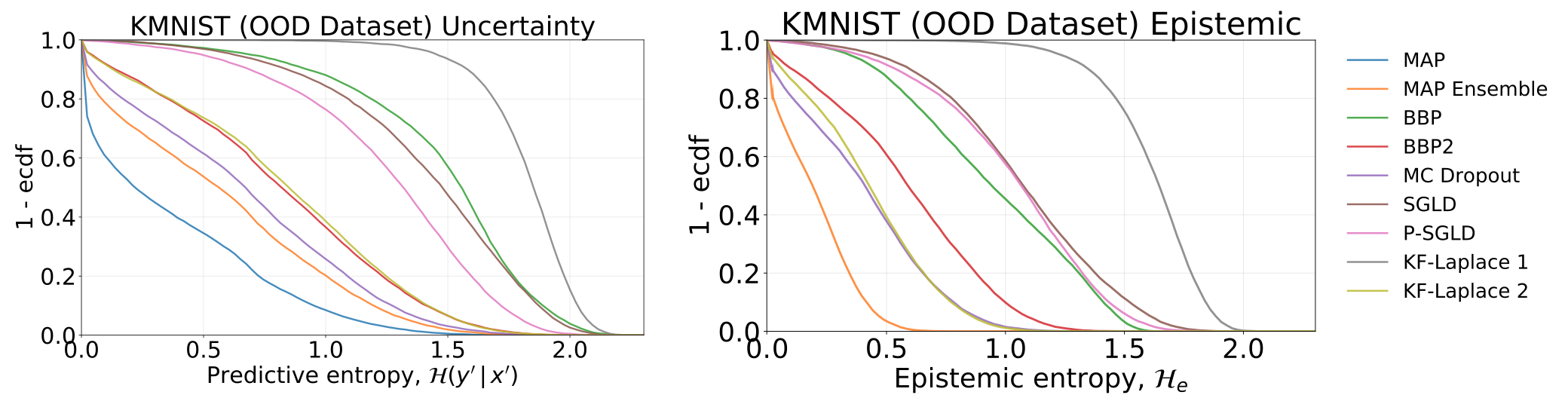
通過測試我們的模型(已在MNIST上接受過培訓的模型)獲得的全部和認知不確定性,在KMNIST數據集上:
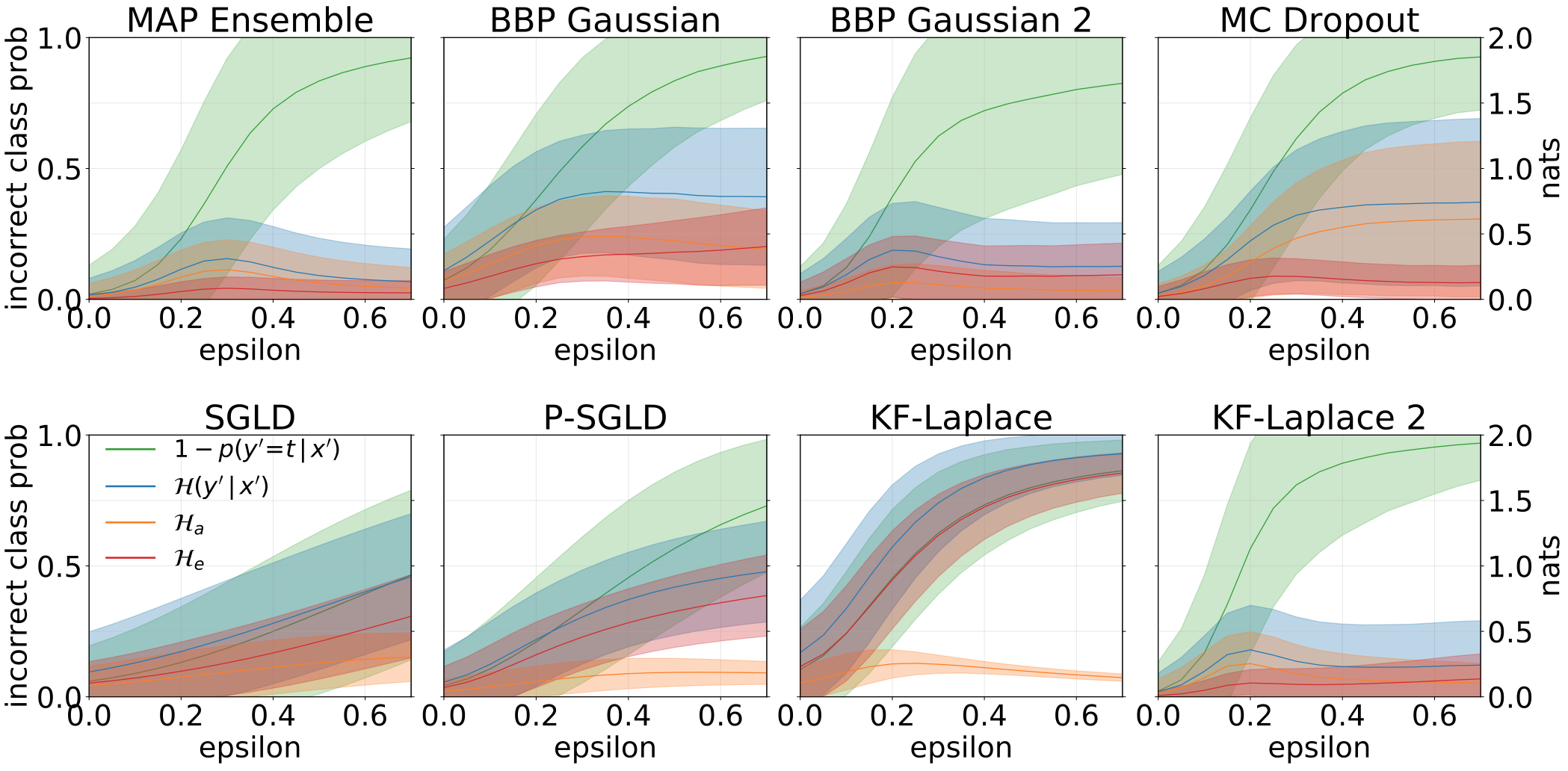
用對抗樣品(FGSM)餵養我們的模型時,獲得了總,質地和認知的不確定性。
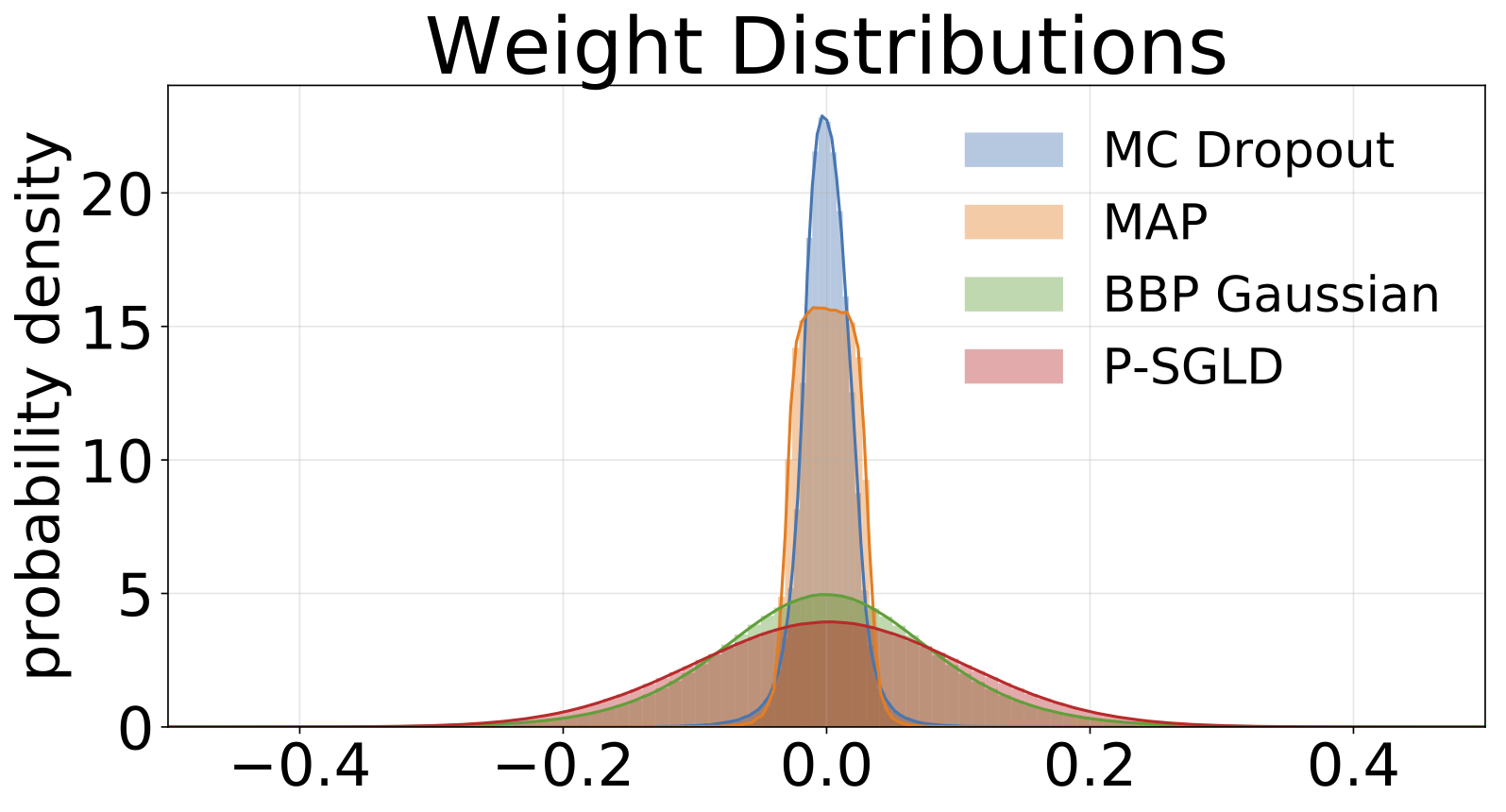
從MNIST訓練的每個模型中採樣的權重直方圖。我們為每個模型繪製10個W的樣本。
#todo


