Bayesian Neural Networks
1.0.0
Pytorch实现以下大约推断方法:
我们还提供:
该项目用Python 2.7和Pytorch 1.0.1编写。如果有CUDA可用,它将自动使用。这些模型也可以在CPU上运行,因为它们并不大。
我们在玩具数据集上进行了(高斯流程地面真相)以及实际数据(六个UCI数据集),在玩具数据集上进行了均匀的和异质的回归体验。
笔记本/分类/(modelName)_(实验类型).ipynb :包含(实验类型),即使用(modelName),即同型/异源性。异质的笔记本电脑包含给定(模型名称)的玩具和UCI数据集实验。
我们还提供Google Colab笔记本。这意味着您可以在GPU上运行(免费!)。无需修改 - 所有依赖项和数据集都是从笔记本中添加的 - 除了选择运行时 - >更改运行时类型 - >硬件加速器 - > GPU。
train_(modelname)_(数据集).py :trains(模型名称)(数据集)。培训指标和模型权重将保存到指定的目录。
SRC/ :通用实用程序和模型定义。
笔记本/分类:笔记本的延迟,可以进行模型培训,数字旋转不确定性实验的评估和运行。它们还允许进行体重分布块和修剪。它们允许加载预训练的模型进行实验。
(https://arxiv.org/abs/1505.05424)
带回归模型的COLAB笔记本:BBP同型 /异质机
培训MNIST的模型:
python train_BayesByBackprop_MNIST.py [--model [MODEL]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]为了解释脚本的论点:
python train_BayesByBackprop_MNIST.py -h最好的结果是通过Laplace先验获得的。
(https://arxiv.org/abs/1506.02557)
反向推理的贝叶斯,其中的平均值和激活方差以封闭形式计算。激活是采样而不是权重。这使得Monte Carlo Elbo估计量表的方差为1/m,其中m是Minibatch尺寸。采样重量量表(M-1)/m。高斯人之间的KL差异也可以以封闭形式计算,从而进一步降低了方差。每个时期的计算速度更快,因此收敛。
培训MNIST的模型:
python train_BayesByBackprop_MNIST.py --model Local_Reparam [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]](https://arxiv.org/abs/1506.02142)
设置了固定的辍学率为0.5。
带回归模型的COLAB笔记本:MC辍学均应异性弹药
培训MNIST的模型:
python train_MCDropout_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]为了解释脚本的论点:
python train_MCDropout_MNIST.py -h(https://www.ics.uci.edu/~welling/publications/papers/stoclangevin_v6.pdf)
为了使其在W上融合到真正的后部,应根据Robbins-Monro条件将学习率退火。实际上,我们使用固定的学习率。
带回归模型的COLAB笔记本:SGLD同型 /异源性
培训MNIST的模型:
python train_SGLD_MNIST.py [--use_preconditioning [USE_PRECONDITIONING]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]为了解释脚本的论点:
python train_SGLD_MNIST.py -h(https://arxiv.org/abs/1512.07666)
带有RMSPROP预处理的SGLD。与香草SGLD相比,应使用更高的学习率。
培训MNIST的模型:
python train_SGLD_MNIST.py --use_preconditioning True [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]多个网络对数据集的子样本进行了培训。
带回归模型的COLAB笔记本:地图集成均应均匀 /异方差
培训MNIST的合奏:
python train_Bootrap_Ensemble_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--subsample [SUBSAMPLE]] [--n_nets [N_NETS]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]为了解释脚本的论点:
python train_Bootrap_Ensemble_MNIST.py -h(https://openreview.net/pdf?id=skdvd2xaz)
训练一个地图网络,然后将二阶Taylor系列aproxiamtion计算为围绕后部模式的曲率。使用块对角线黑森近似值,其中仅考虑了内部依赖性。黑森将进一步近似为单个数据点的Hessian因素的期望的Kronecker产品。近似Hessian可能需要一段时间。幸运的是,它只需要完成一次。
培训MNIST和大约Hessian的地图网络:
python train_KFLaplace_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--hessian_diag_sig [HESSIAN_DIAG_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]为了解释脚本的论点:
python train_KFLaplace_MNIST.py -h请注意,我们节省了未量化和未经启动的Hessian因素。这将允许在推理时间对先前的计算廉价更改,因为不需要重新计算Hessian。推论将需要反转近似的Hessian因子并从基质正态分布中取样。这在笔记本/kfac_laplace_mnist.ipynb中显示
(https://arxiv.org/abs/1402.4102)
我们实现了该算法的尺度适应版本,在此提议在燃烧期间自动找到超参数。我们在高斯的精确度上放置了高斯先前的网络权重和伽马超级优势。
运行SG-HMC-SA燃烧和采样器,从而在指定文件中节省了权重。
python train_SGHMC_MNIST.py [--epochs [EPOCHS]] [--sample_freq [SAMPLE_FREQ]] [--burn_in [BURN_IN]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]为了解释脚本的论点:
python train_SGHMC_MNIST.py -hMAP推断提供了参数值的点估计值。当提供超出分布输入(例如旋转数字)时,这些模型将以高度置信度进行错误的预测。
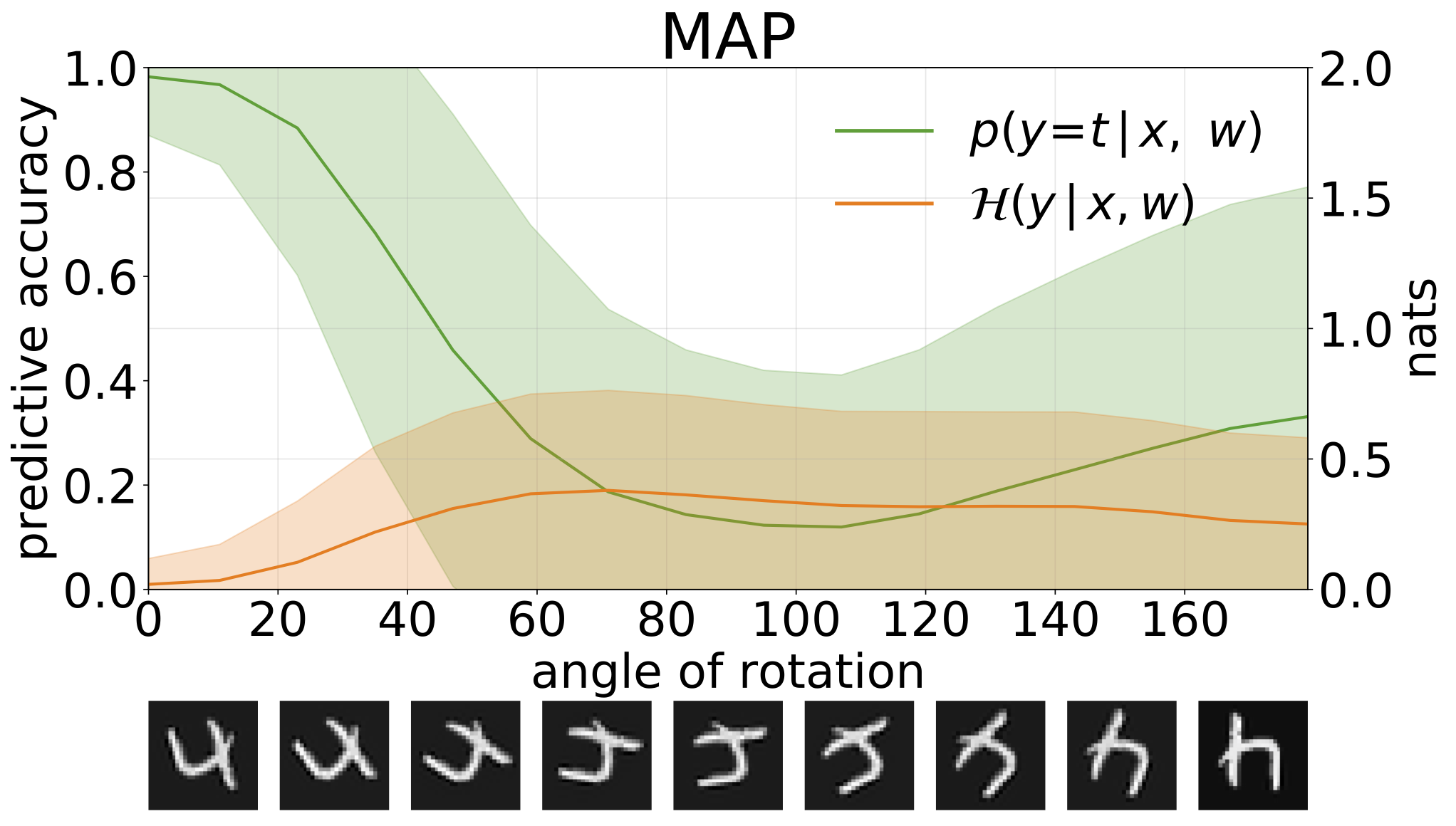
我们可以通过预测性熵来衡量模型预测的不确定性。我们可以分解此术语,以区分两种类型的不确定性。可以将数据中噪声或息肉不确定性引起的不确定性量化为模型预测的预期熵。模型的不确定性或认知不确定性可以测量为总熵和核熵之间的差异。
玩具同性恋回归任务。数据由带有RBF内核的GP生成(L = 1,σN= 0.3)。我们使用一个单输出FC网络,该网络具有200个Relu单元的一个隐藏层,以预测回归平均值μ(x)。固定的logσ分别学习。
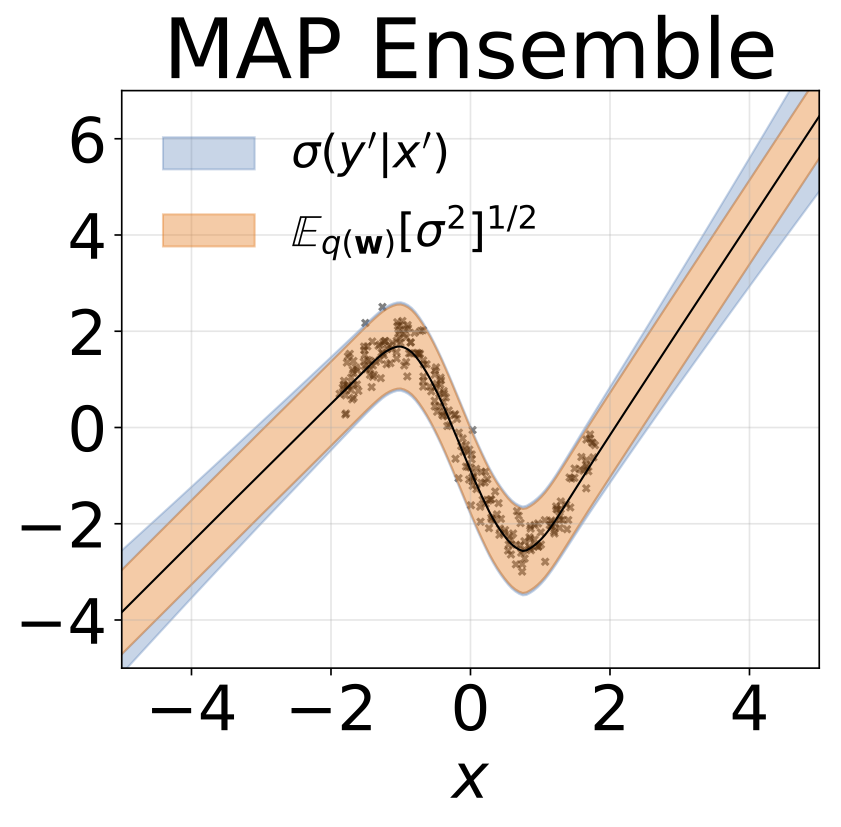
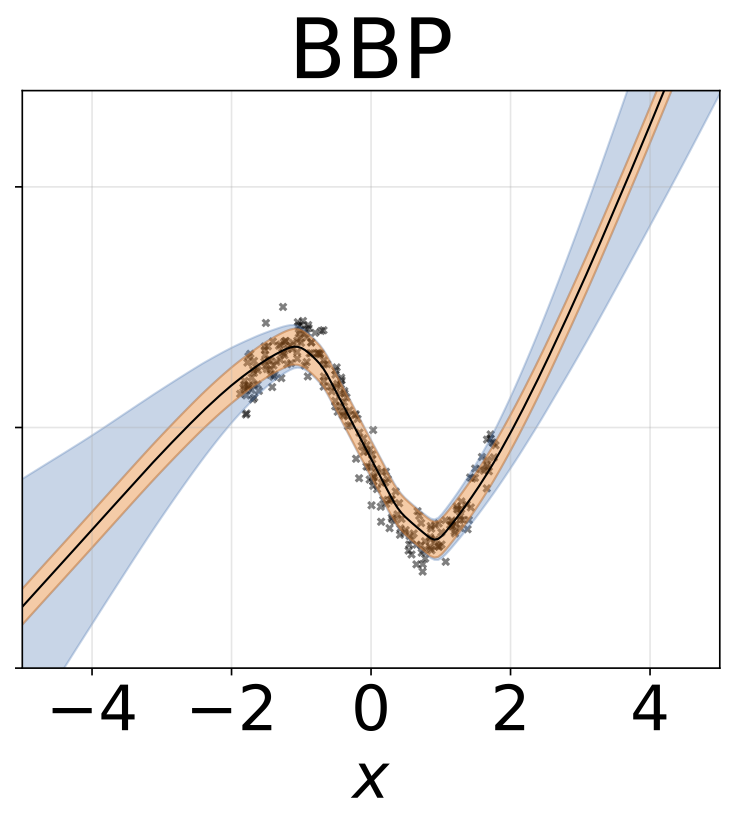
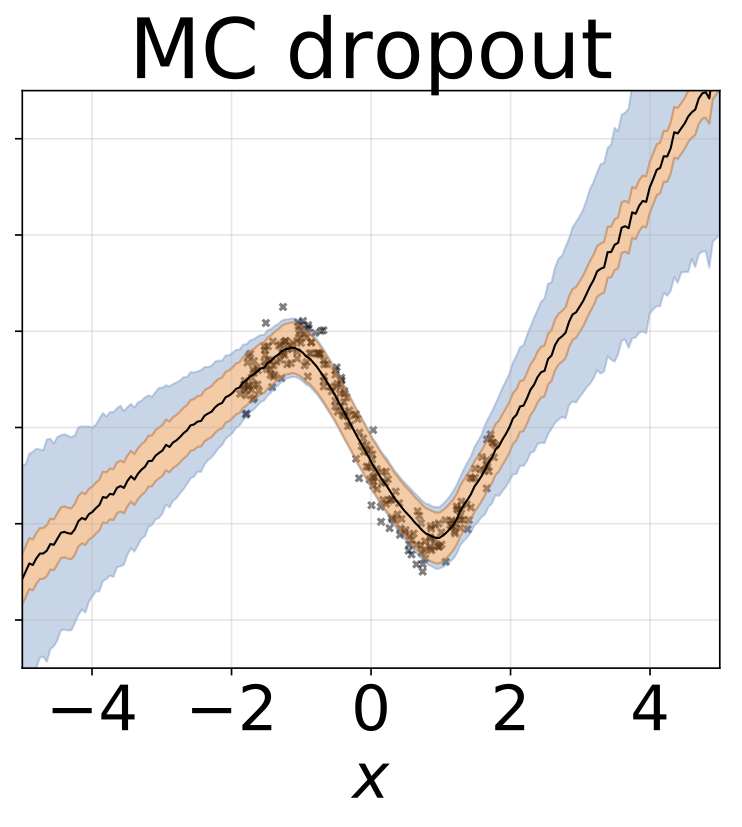
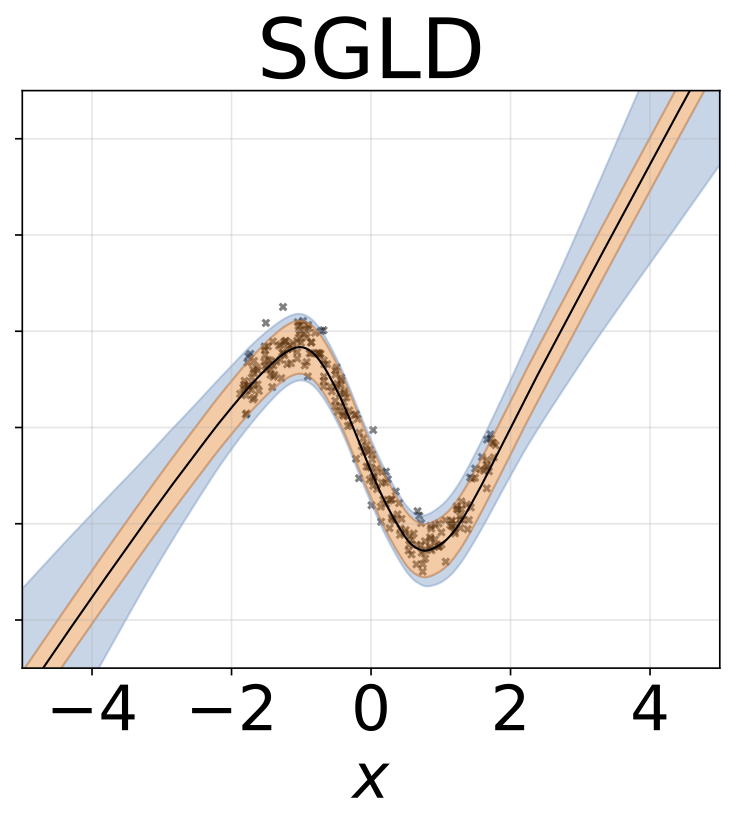
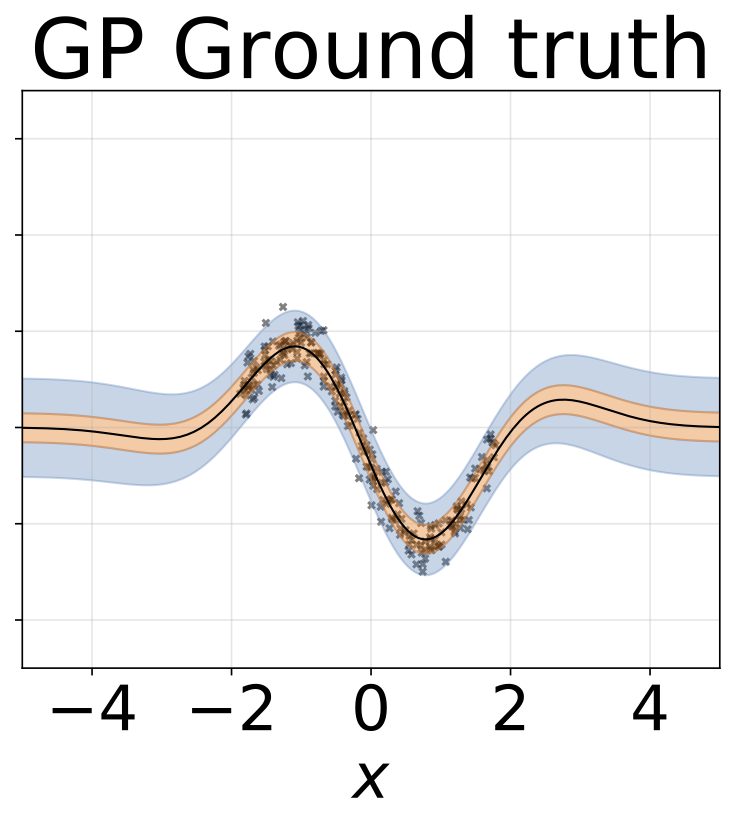
与上一节相同的方案,但从输入预测logσ(x)。
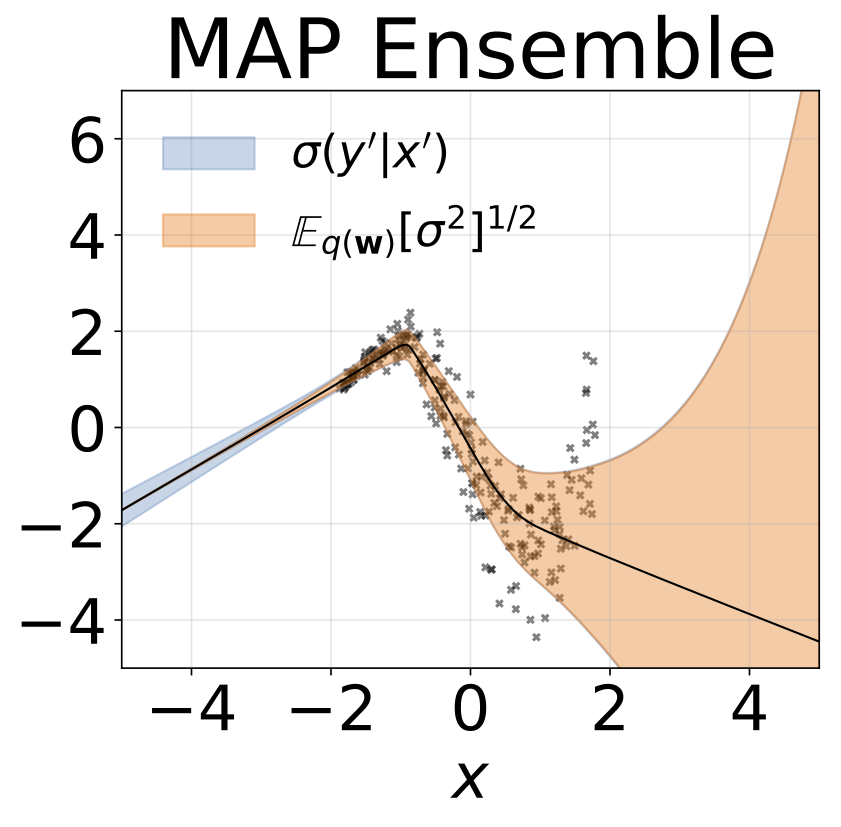
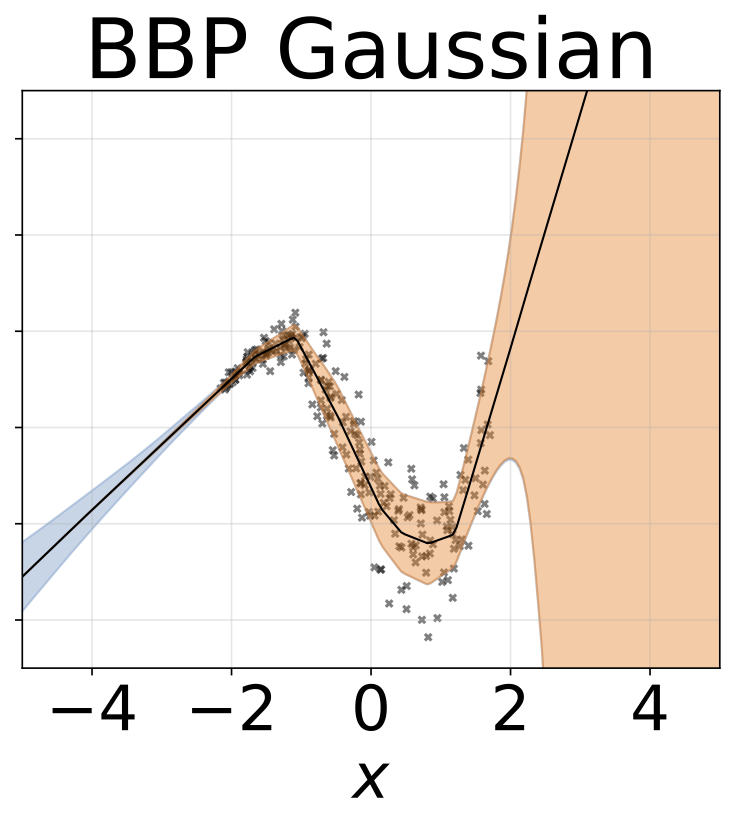
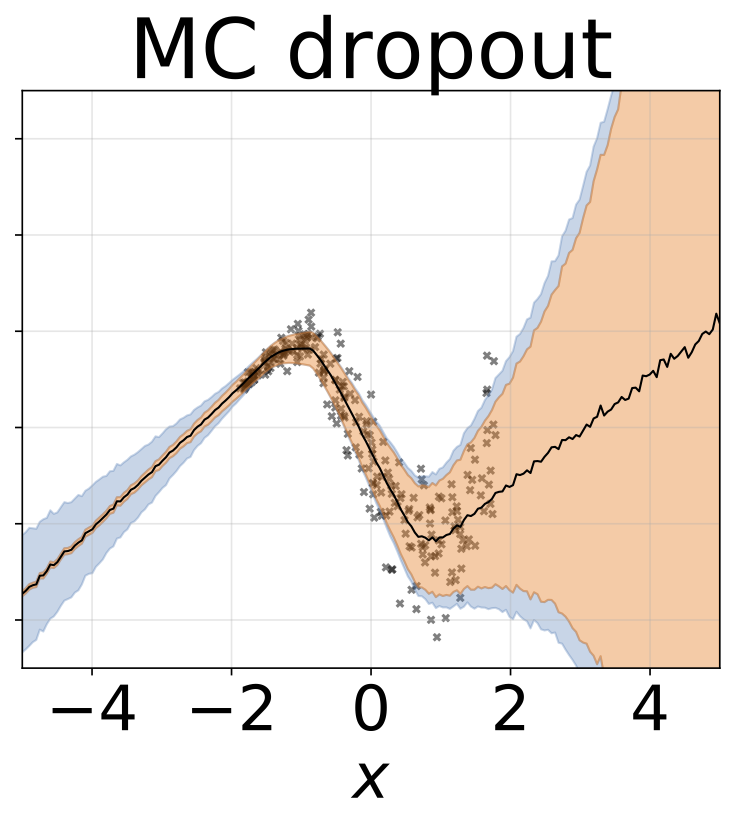
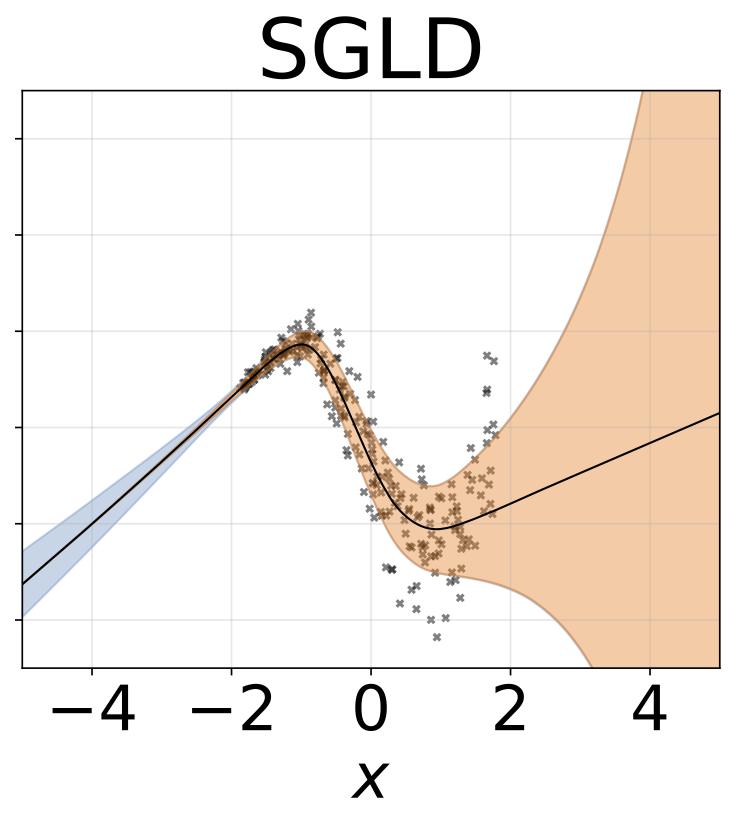
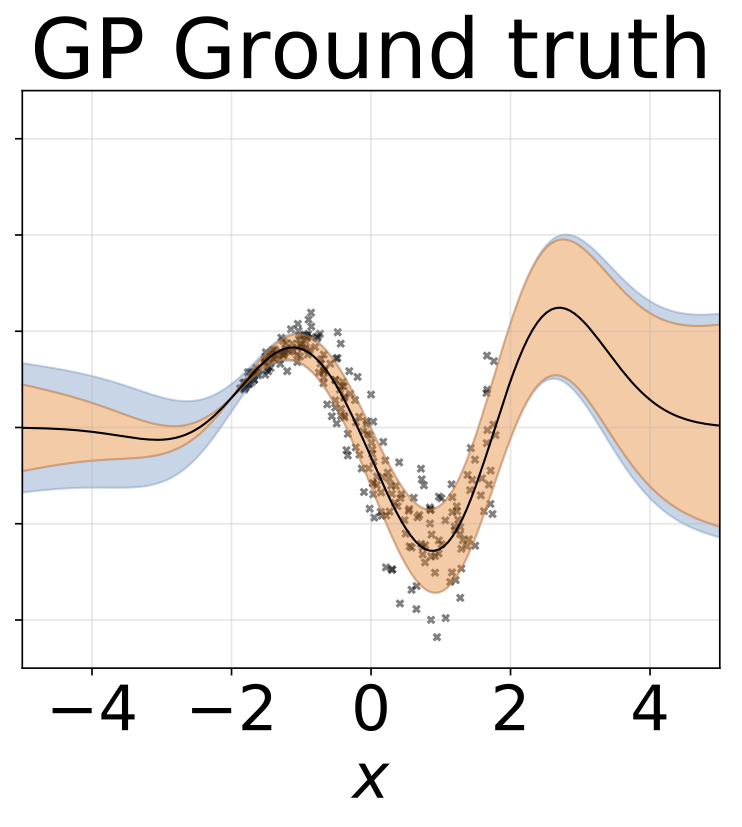
玩具异质的回归任务。数据由带有RBF内核的GP生成(L =1σN= 0.3·| x + 2 |)。我们使用具有200个relu单元的两头网络来预测回归平均值μ(x)和对数标准偏差logσ(x)。
我们使用10-Foild Cross验证,对六个UCI数据集(外壳,混凝土,能源效率,发电厂,红酒和游艇数据集进行了异质分析回归。所有这些实验都包含在异性弹性笔记本中。请注意,结果在很大程度上取决于高参数的选择。下面的图显示了火车上的对数可能性和RMSE(半透明的颜色)和测试(纯色)。圆形和误差条分别对应于10倍的交叉验证平均值和标准偏差。
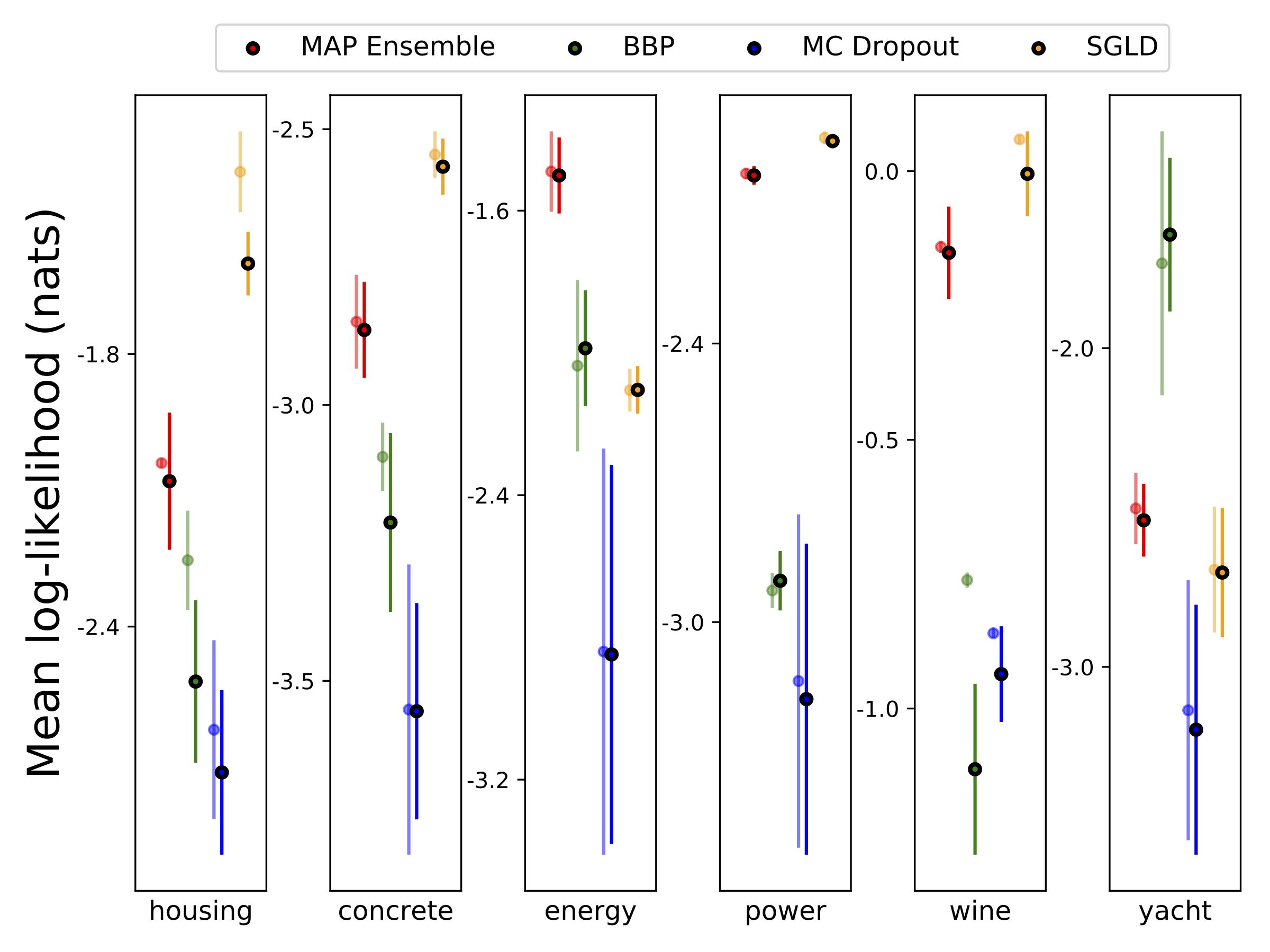
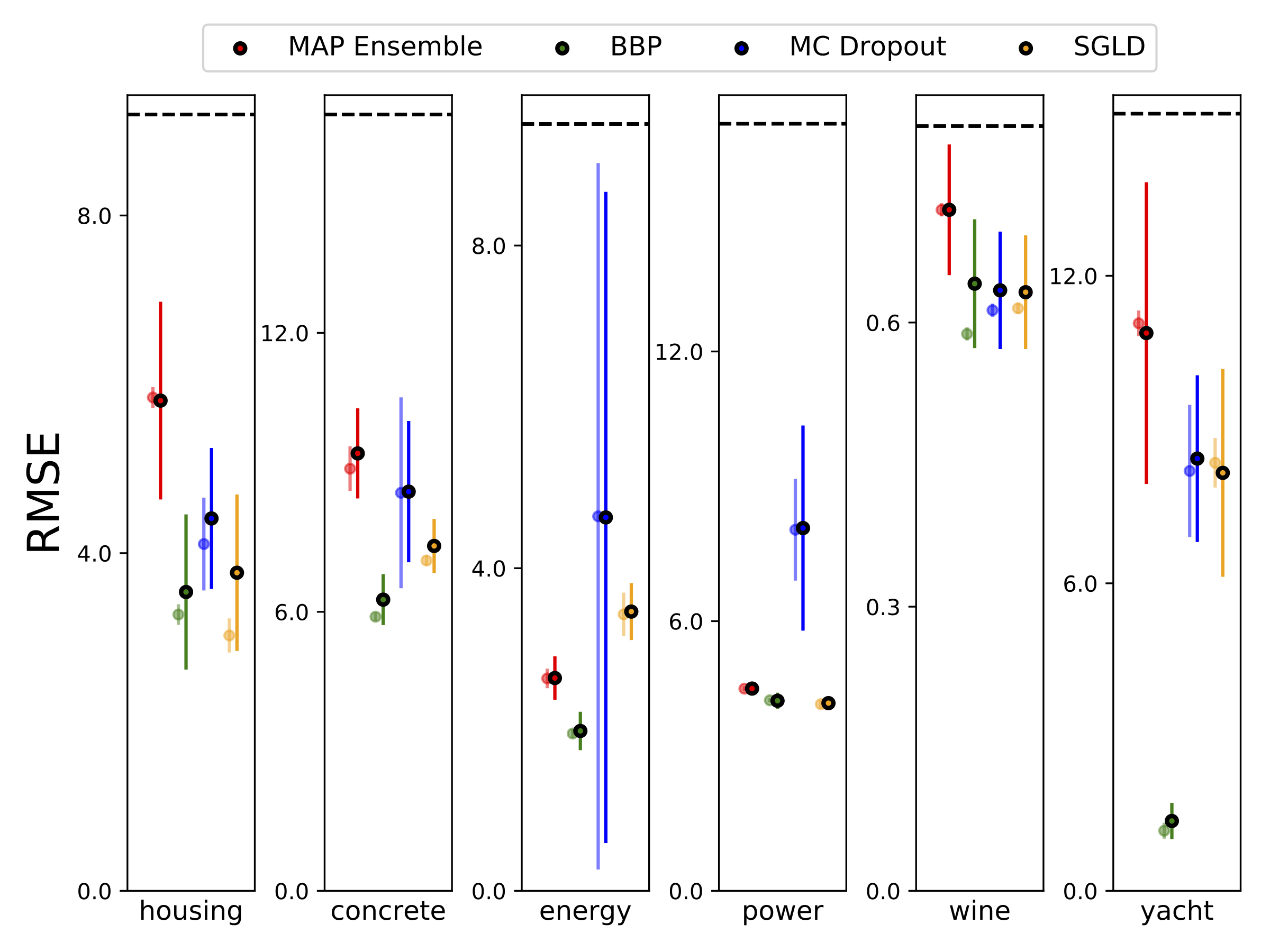
除了地图外,所有模型的权重边缘化,其中仅使用一组权重。
| MNIST测试 | 地图 | 地图合奏 | BBP高斯 | BBP GMM | BBP拉普拉斯 | BBP本地Reparam | MC辍学 | sgld | PSGLD |
|---|---|---|---|---|---|---|---|---|---|
| log喜欢 | -572.9 | -496.54 | -1100.29 | -1008.28 | -892.85 | -1086.43 | -435.458 | -828.29 | -661.25 |
| 错误 % | 1.58 | 1.53 | 2.60 | 2.38 | 2.28 | 2.61 | 1.37 | 1.76 | 1.76 |
MNIST测试结果正在考虑的方法。尚未执行Estangive Hyparameter Tunning。我们用100个MC样品近似后验预测分布。我们使用具有两个1200个单元旋转层的FC网络。如果未指定,则先验是std = 0.1的高斯。 P-SGLD使用RMSPROP预处理。
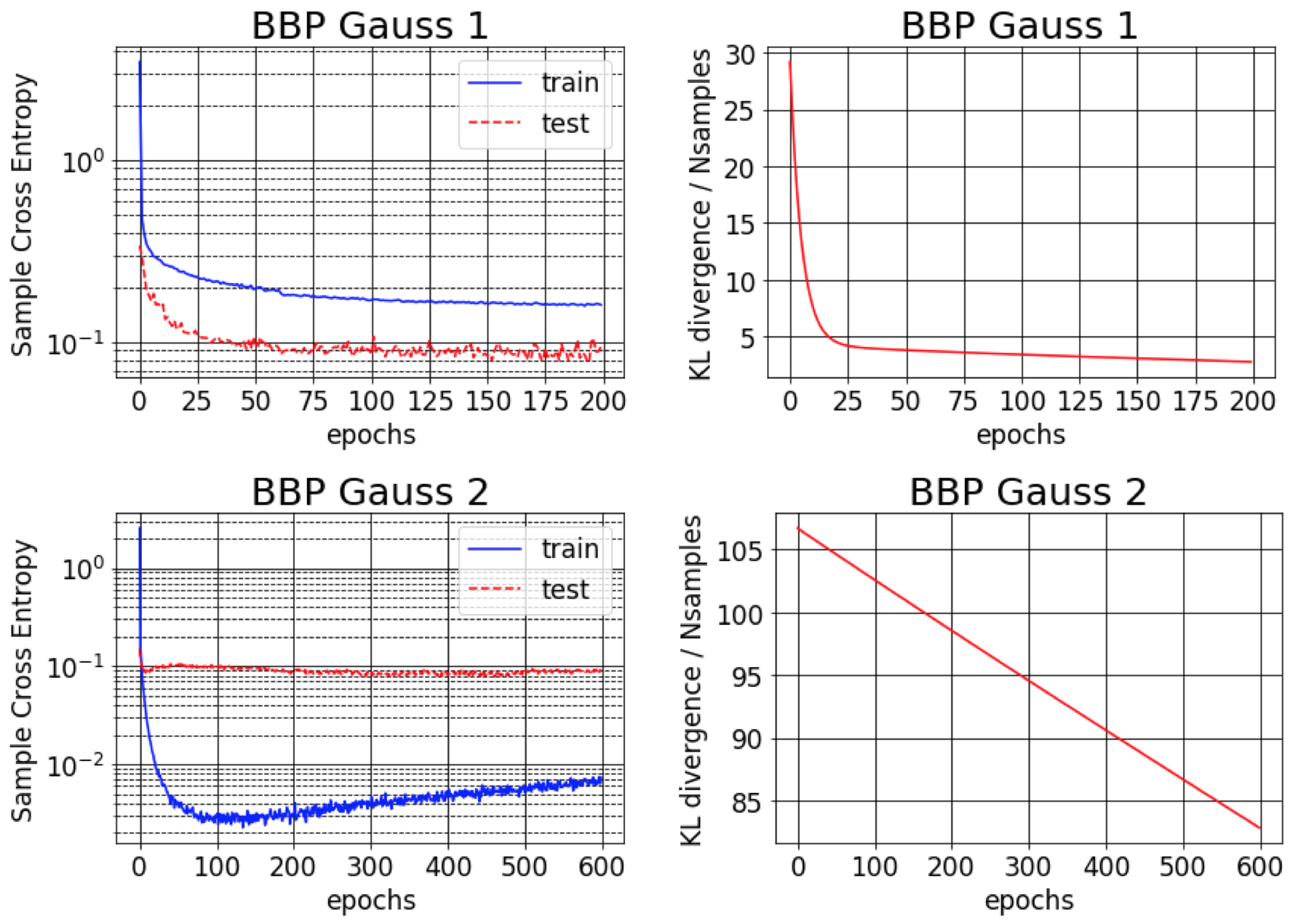
Backprop的贝叶斯原始纸报告报告了MNIST的1%错误。我们发现,只有在初始化的后差为小(BBP Gauss 2)时,才可以实现此结果。在这种情况下,权重的分布类似于三角洲,提供了良好的预测性能,但不确定性估计不确定。但是,当初始化差异以匹配先验的方差(BBP高斯1)时,我们获得了上述结果。这两种高参数配置方案的训练曲线如下:
通过增加旋转的MNIST测试集创建OOD样品时,获得的总,质和认知的不确定性是:
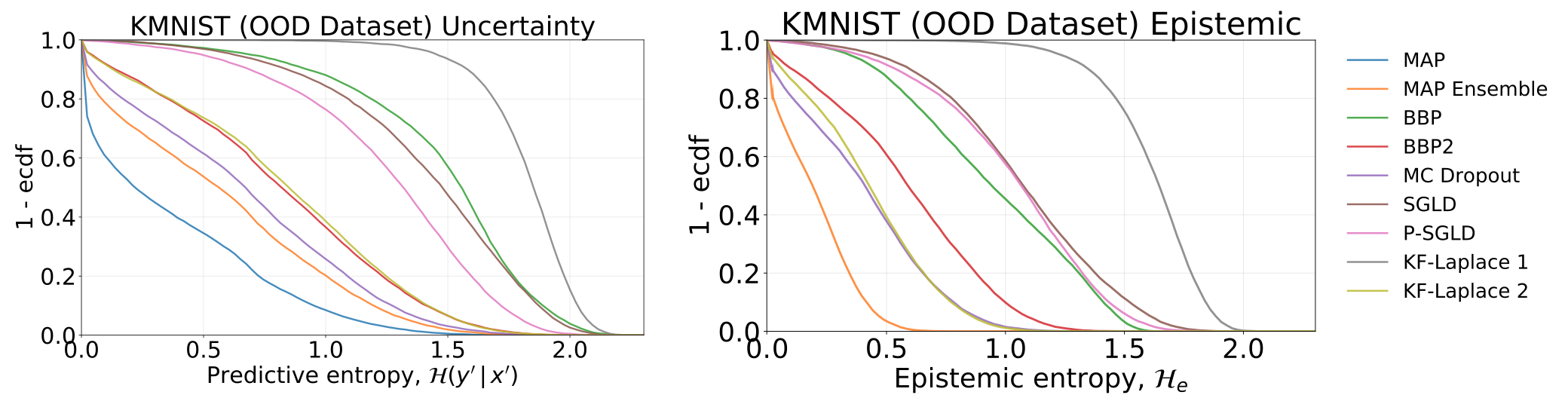
通过测试我们的模型(已在MNIST上接受过培训的模型)获得的全部和认知不确定性,在KMNIST数据集上:
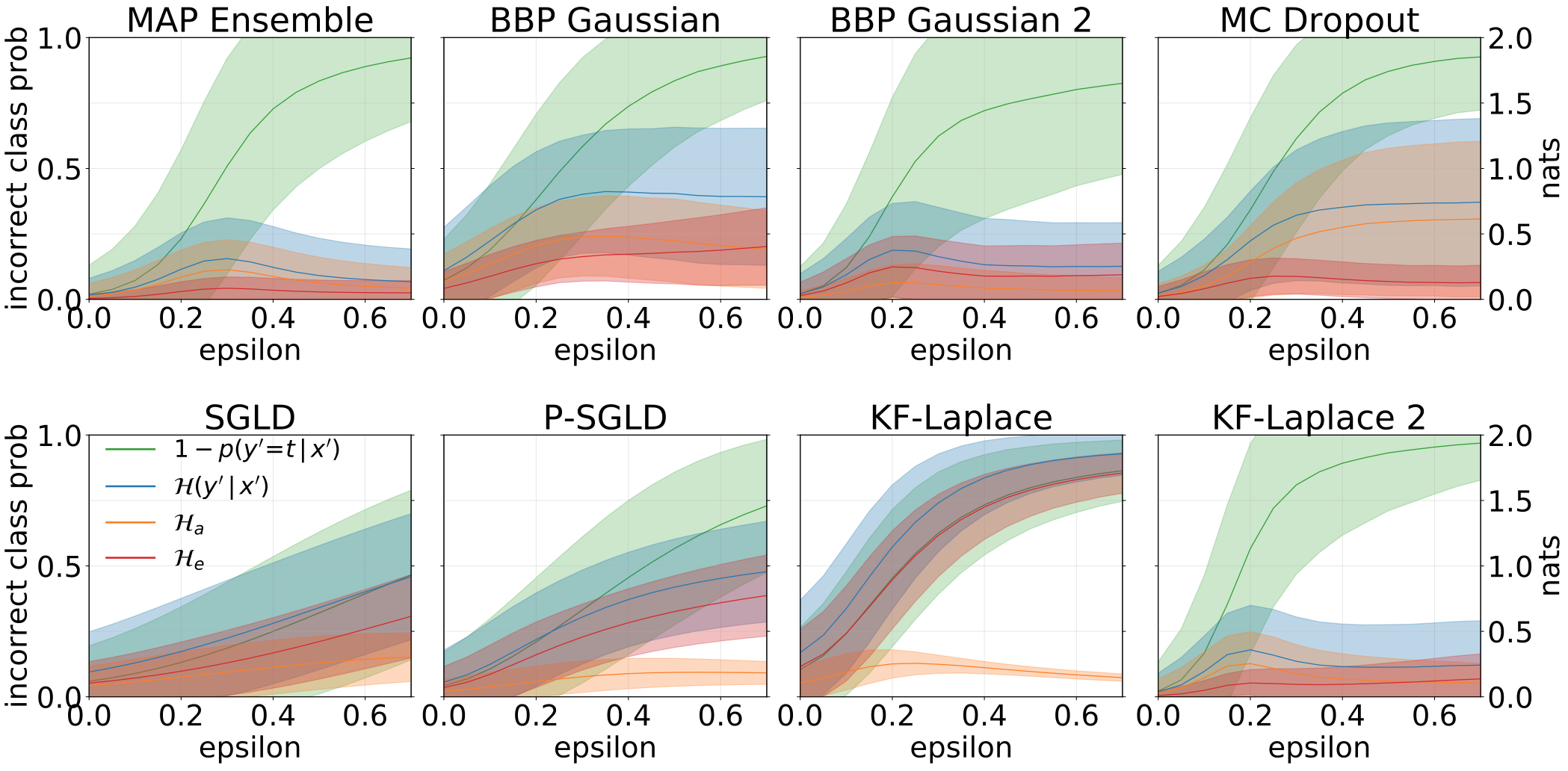
用对抗样品(FGSM)喂养我们的模型时,获得了总,质地和认知的不确定性。
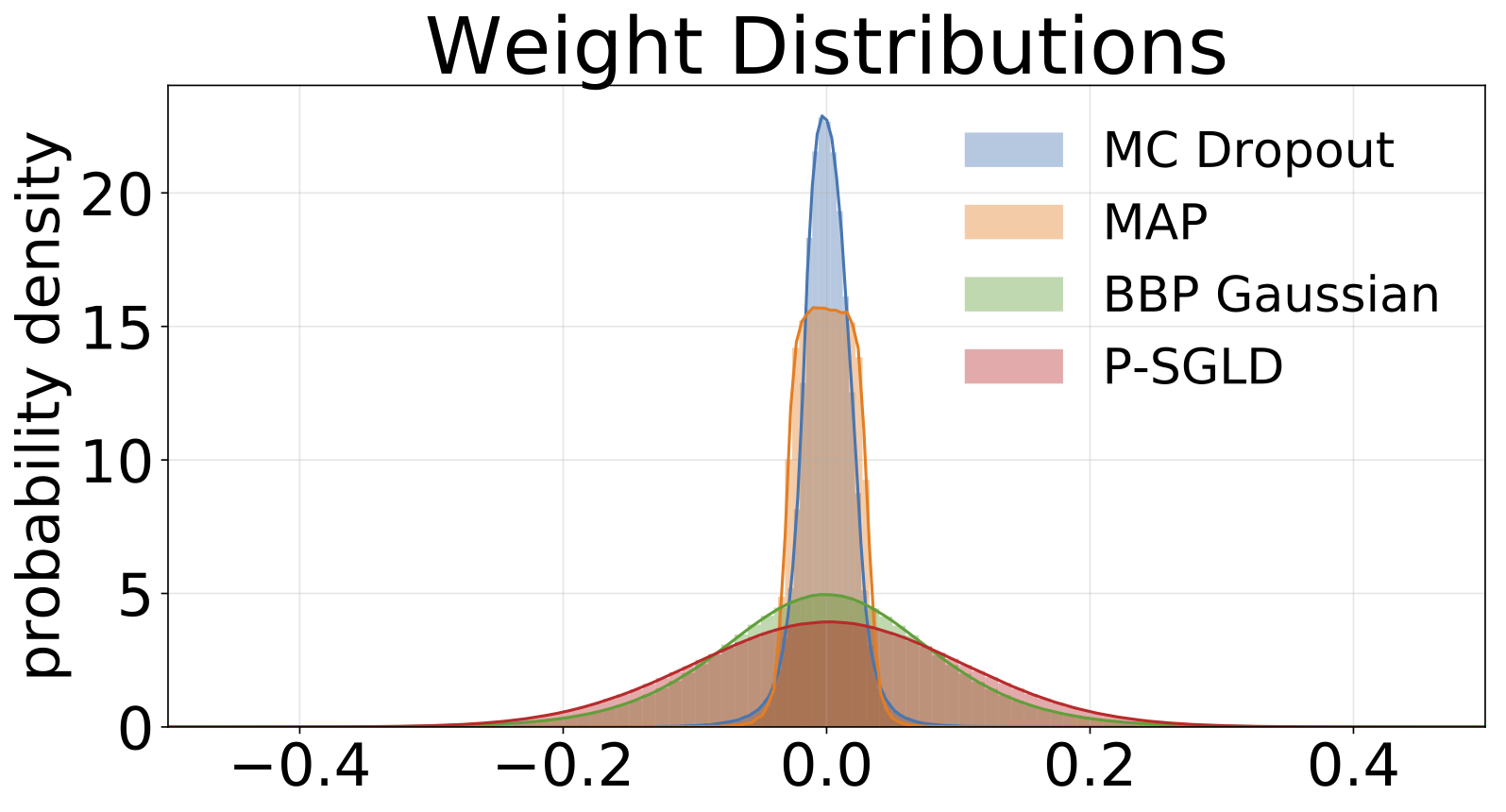
从MNIST训练的每个模型中采样的权重直方图。我们为每个模型绘制10个W的样本。
#todo


