Bayesian Neural Networks
1.0.0
次のおおよその推論方法のためのPytorchの実装:
また、次のコードも提供します。
このプロジェクトは、Python 2.7およびPytorch 1.0.1で書かれています。 CUDAが利用可能な場合、自動的に使用されます。モデルは、過度に大きくないため、CPUで実行することもできます。
(ガウスプロセスグラウンドトゥルース)、および実際のデータ(6つのUCIデータセット)で生成された玩具データセットでホモスティックおよびヘテロスケートの回帰体験を実施しました。
Notebooks/classification/(modelName)_(experimentType).ipynb :(experimentType)、つまりホモスティック/ヘテロスケジックスティックを使用した実験が含まれています。ヘテロスケジックノートブックには、特定の(モデル名)のおもちゃとUCIデータセットの両方の実験が含まれています。
また、Google Colabノートブックも提供しています。これは、GPUで実行できることを意味します(無料で!)。変更は不要です - すべての依存関係とデータセットはノートブック内から追加されます - ランタイムの選択を除き - >ランタイムタイプ - >ハードウェアアクセラレータ - > GPUを変更します。
train_(modelname)_(dataset).py :trains(modelname)on(dataset)。トレーニングメトリックとモデルの重みは、指定されたディレクトリに保存されます。
SRC/ :一般ユーティリティとモデル定義。
ノートブック/分類:モデルのトレーニング、評価、および桁回転の不確実性実験の実行を可能にするノートブックの浸透。また、体重式のプロットと体重の剪定も可能です。それらは、実験のために事前に訓練されたモデルの負荷を可能にします。
(https://arxiv.org/abs/1505.05424)
回帰モデルを備えたコラブノートブック:BBPホモステイスティック /ヘテロスケジック
MNISTでモデルを訓練する:
python train_BayesByBackprop_MNIST.py [--model [MODEL]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]スクリプトの議論の説明については:
python train_BayesByBackprop_MNIST.py -h最良の結果は、ラプラス以前に得られます。
(https://arxiv.org/abs/1506.02557)
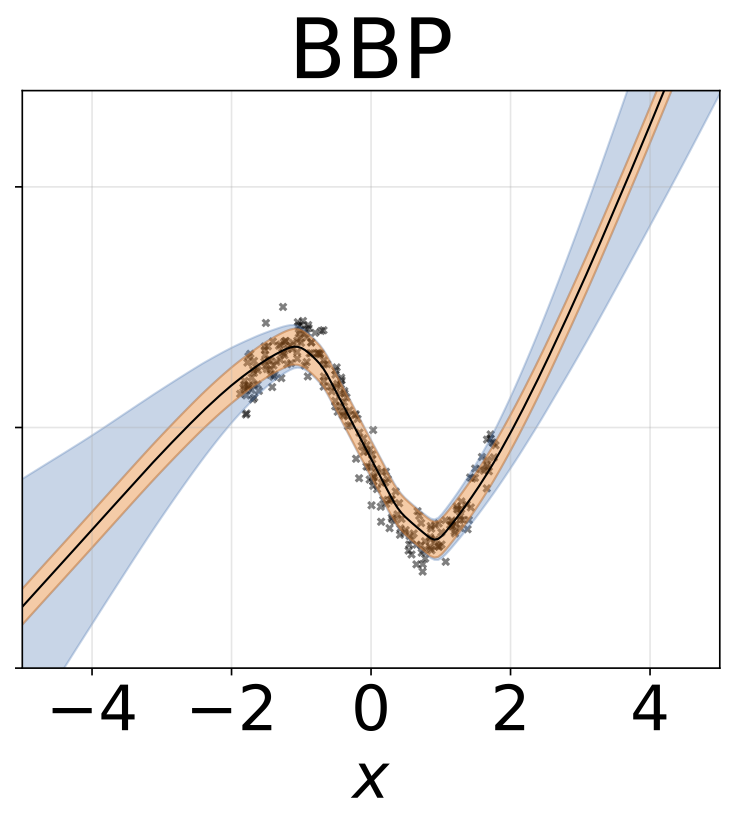
バックプロップの推論によるベイズ。ここで、活性化の平均と分散が閉じた形で計算されます。アクティベーションは重みではなくサンプリングされます。これにより、モンテカルロエルボ推定器スケールの分散が1/m、ここでmはミニバッチサイズです。サンプリングウェイトスケール(M-1)/m。ガウス間のKLの発散は、閉じた形で計算することもでき、分散をさらに減らします。各エポックの計算はより速く、収束も速くなります。
MNISTでモデルを訓練する:
python train_BayesByBackprop_MNIST.py --model Local_Reparam [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--n_samples [N_SAMPLES]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]](https://arxiv.org/abs/1506.02142)
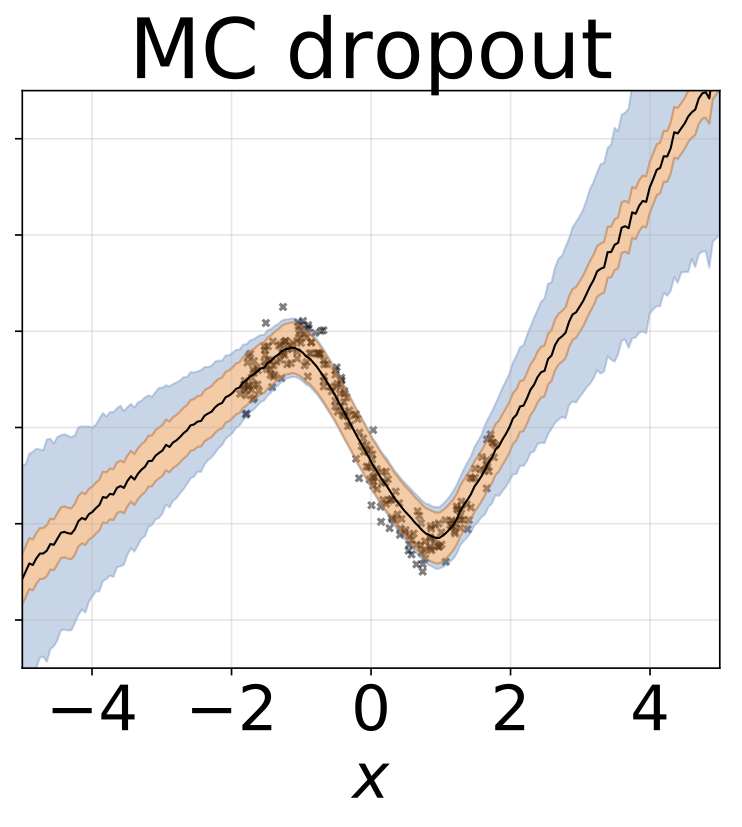
0.5の固定ドロップアウトレートが設定されています。
回帰モデルを備えたコラブノートブック:MCドロップアウトホモステイスティックヘテロスケスト
MNISTでモデルを訓練する:
python train_MCDropout_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]スクリプトの議論の説明については:
python train_MCDropout_MNIST.py -h(https://www.ics.uci.edu/~welling/publications/papers/stoclangevin_v6.pdf)
wの真の事後に収束するには、学習率をロビンズ・モンロの条件に従ってアニールする必要があります。実際には、固定学習率を使用しています。
回帰モデルを備えたコラブノートブック:SGLD HOMOSCEDASTIC / HETEROSCEDASTIC
MNISTでモデルを訓練する:
python train_SGLD_MNIST.py [--use_preconditioning [USE_PRECONDITIONING]] [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]スクリプトの議論の説明については:
python train_SGLD_MNIST.py -h(https://arxiv.org/abs/1512.07666)
RMSPROP前処理を備えたSGLD。バニラSGLDよりも高等教育率を使用する必要があります。
MNISTでモデルを訓練する:
python train_SGLD_MNIST.py --use_preconditioning True [--prior_sig [PRIOR_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]データセットのサブサンプルで複数のネットワークがトレーニングされています。
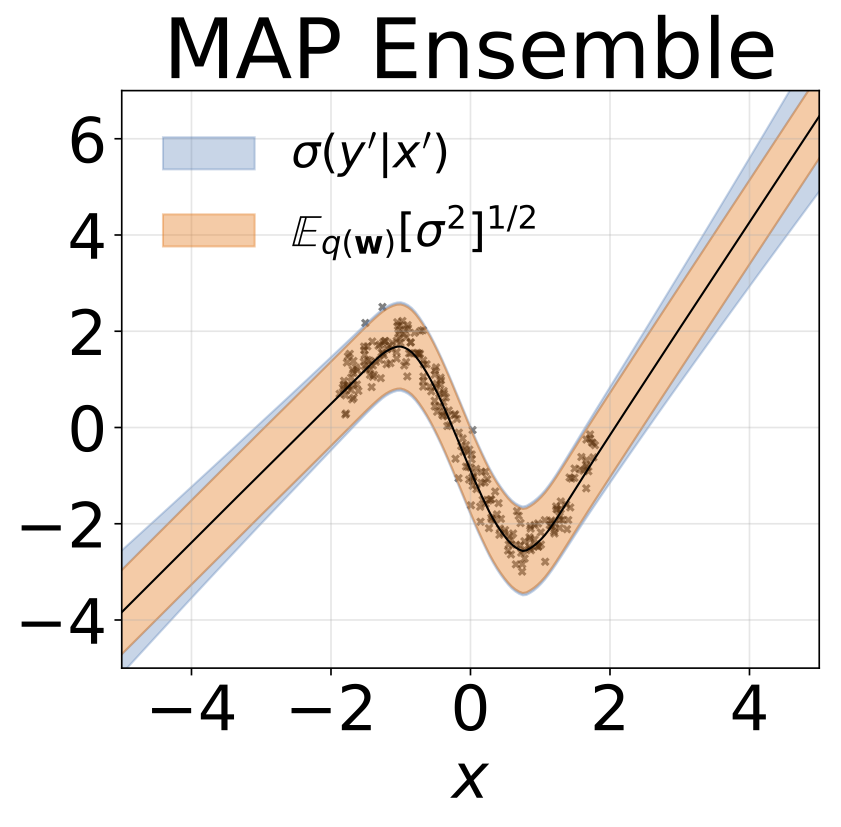
回帰モデルを備えたコラブノートブック:マップアンサンブルホモスティック /ヘテロスケジック
ミニストでアンサンブルを訓練する:
python train_Bootrap_Ensemble_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--subsample [SUBSAMPLE]] [--n_nets [N_NETS]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]スクリプトの議論の説明については:
python train_Bootrap_Ensemble_MNIST.py -h(https://openreview.net/pdf?id=skdvd2xaz)
マップネットワークをトレーニングしてから、後部のモードの周りの曲率への2次テイラーシリーズのaproxiamtionを計算します。ブロック斜めのヘシアン近似が使用されます。ここでは、層内依存関係のみが考慮されます。ヘシアンは、単一のデータポイントのヘシアン要因の期待のクロネッカー産物としてさらに近似されています。ヘシアンに近似するにはしばらく時間がかかります。幸いなことに、それは一度だけ行う必要があります。
Mnistのマップネットワークをトレーニングし、ヘシアンに近似します。
python train_KFLaplace_MNIST.py [--weight_decay [WEIGHT_DECAY]] [--hessian_diag_sig [HESSIAN_DIAG_SIG]] [--epochs [EPOCHS]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]スクリプトの議論の説明については:
python train_KFLaplace_MNIST.py -h無防備で阻害されていないヘシアンの要因を保存することに注意してください。これにより、ヘシアンを再計算する必要がないため、推論時に事前に計算的に安価な変更が可能になります。推論では、近似されたヘシアン因子を反転させ、マトリックス正規分布からサンプリングする必要があります。これは、ノートブック/kfac_laplace_mnist.ipynbに示されています
(https://arxiv.org/abs/1402.4102)
このアルゴリズムのスケール適応バージョンを実装します。ここでは、バーンイン中にハイパーパラメーターを自動的に見つけるように提案します。ネットワークの重みにガウスの事前に、ガウスの精度よりもガンマが過剰に配置します。
sg-hmc-sa burn in and samplerを実行し、指定されたファイルでウェイトを節約します。
python train_SGHMC_MNIST.py [--epochs [EPOCHS]] [--sample_freq [SAMPLE_FREQ]] [--burn_in [BURN_IN]] [--lr [LR]] [--models_dir [MODELS_DIR]] [--results_dir [RESULTS_DIR]]スクリプトの議論の説明については:
python train_SGHMC_MNIST.py -hマップ推論は、パラメーター値のポイント推定を提供します。回転した数字などの配布入力が提供された場合、これらのモデルは自信を持って間違った予測を行うようにします。
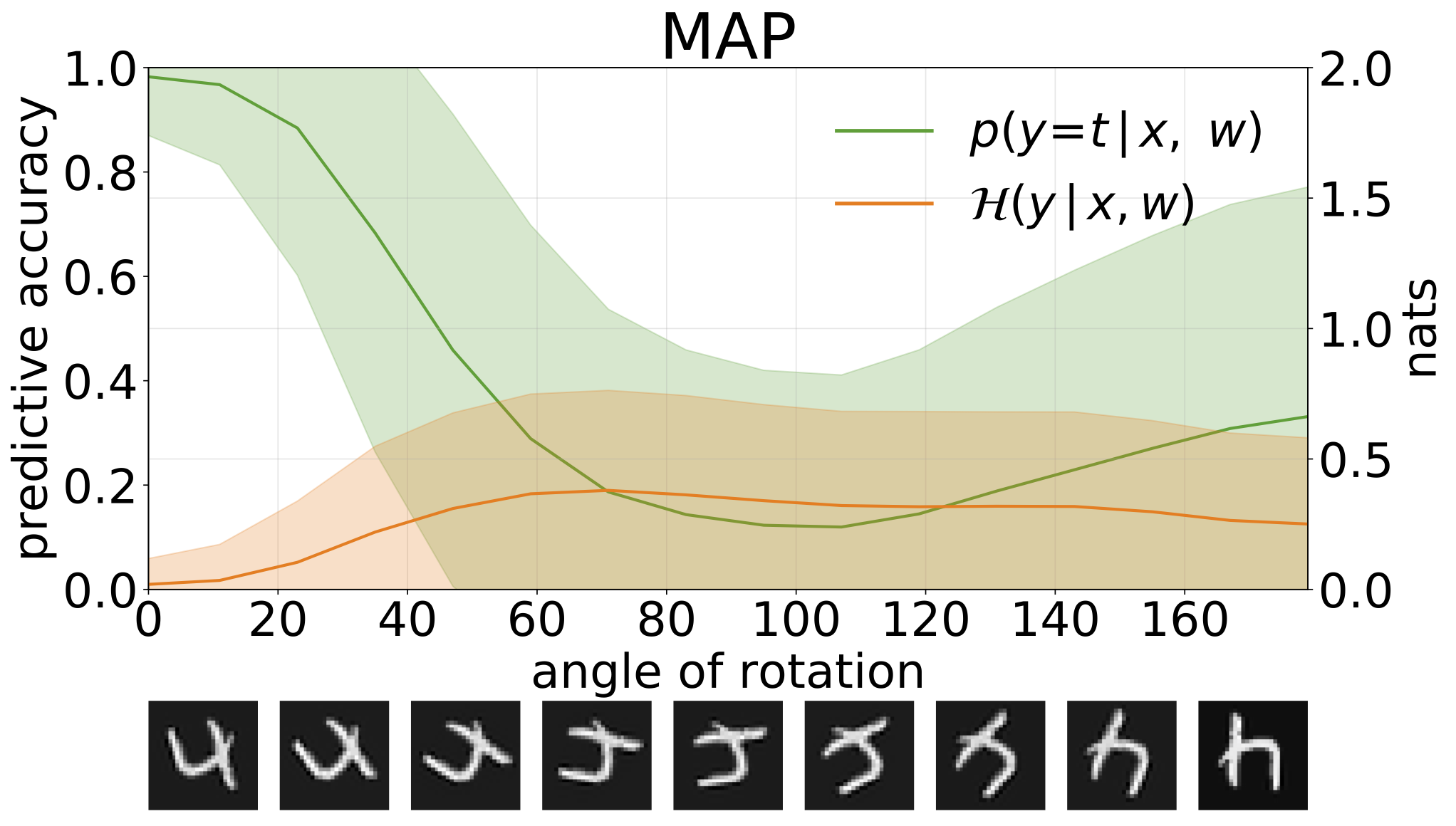
予測エントロピーを介して、モデルの予測の不確実性を測定できます。 2種類の不確実性を区別するために、この用語を分解できます。データのノイズによって引き起こされる不確実性、またはアレアトリックの不確実性は、モデル予測の予想エントロピーとして定量化できます。モデルの不確実性または認識論的不確実性は、総エントロピーとaleatoricエントロピーの違いとして測定できます。
おもちゃのホモス酸化回帰タスク。データは、RBFカーネル(l = 1、σn= 0.3)のGPによって生成されます。 200 Reluユニットの1つの隠れレイヤーを持つ単一の出力FCネットワークを使用して、回帰平均μ(x)を予測します。固定logσは個別に学習されます。
前のセクションと同じシナリオが入力からログσ(x)が予測されます。
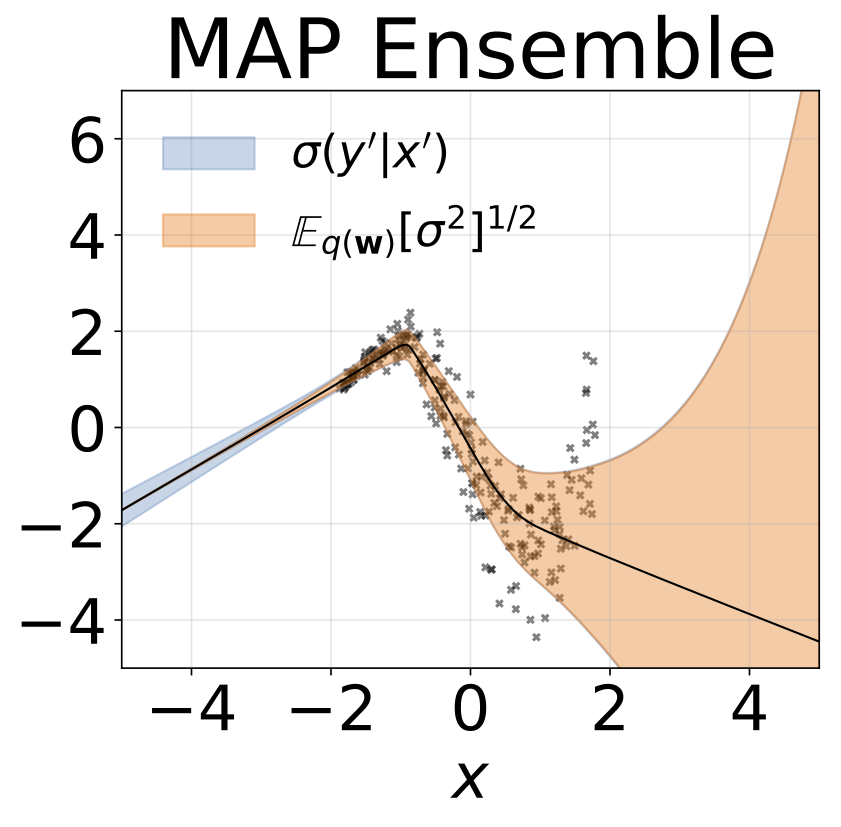
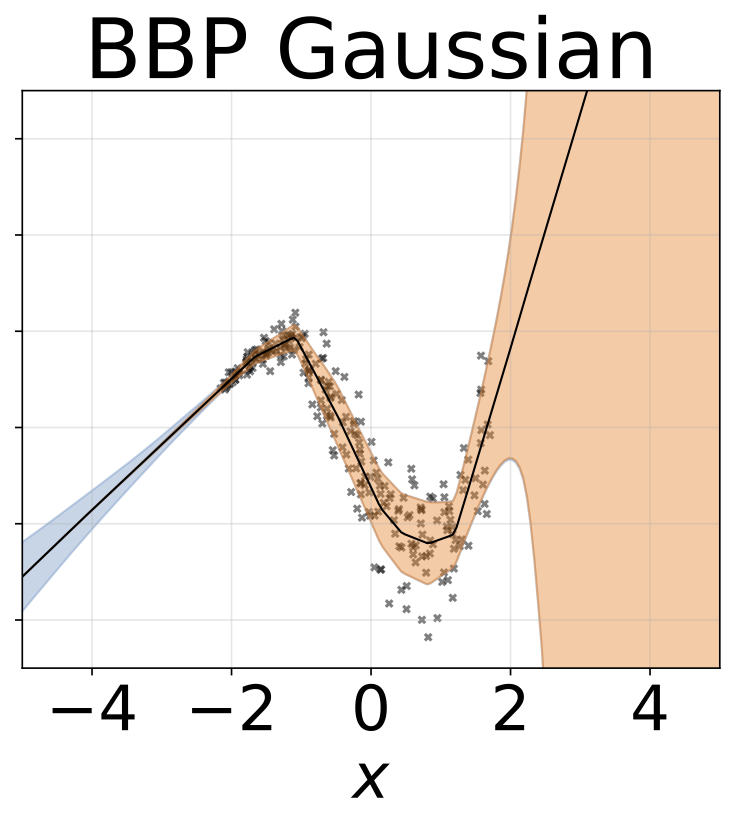
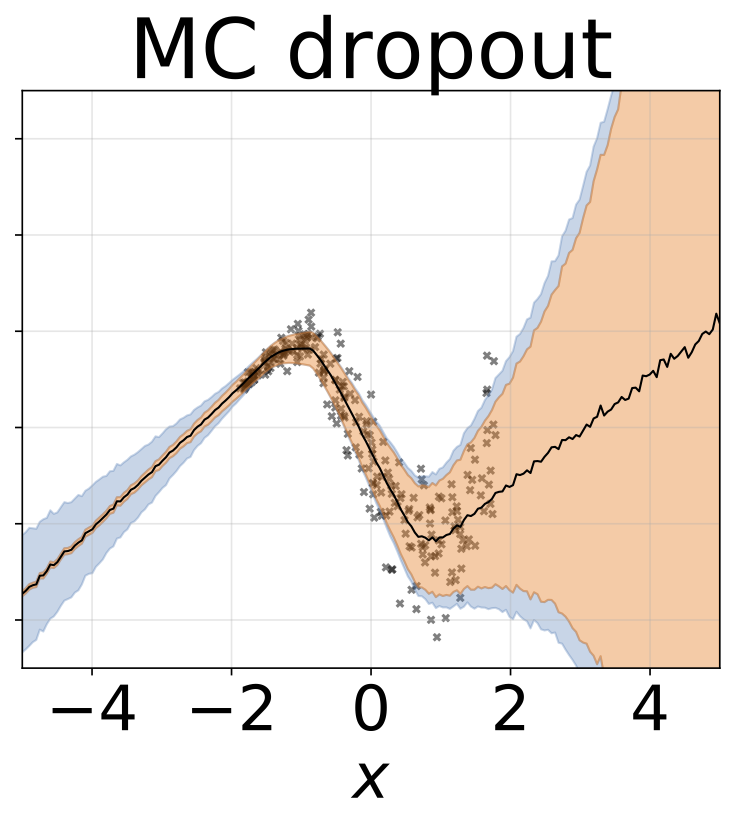
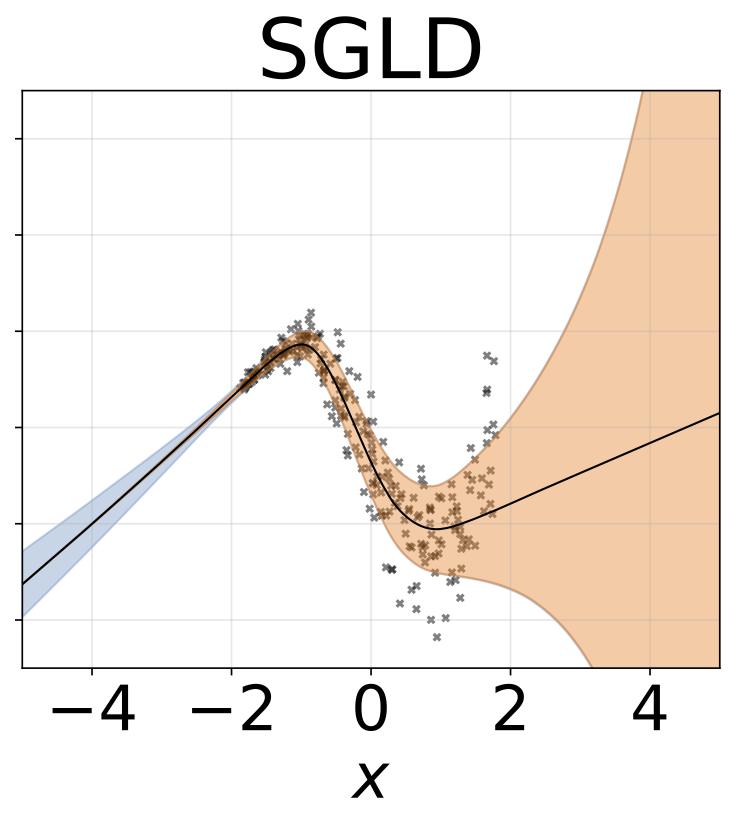
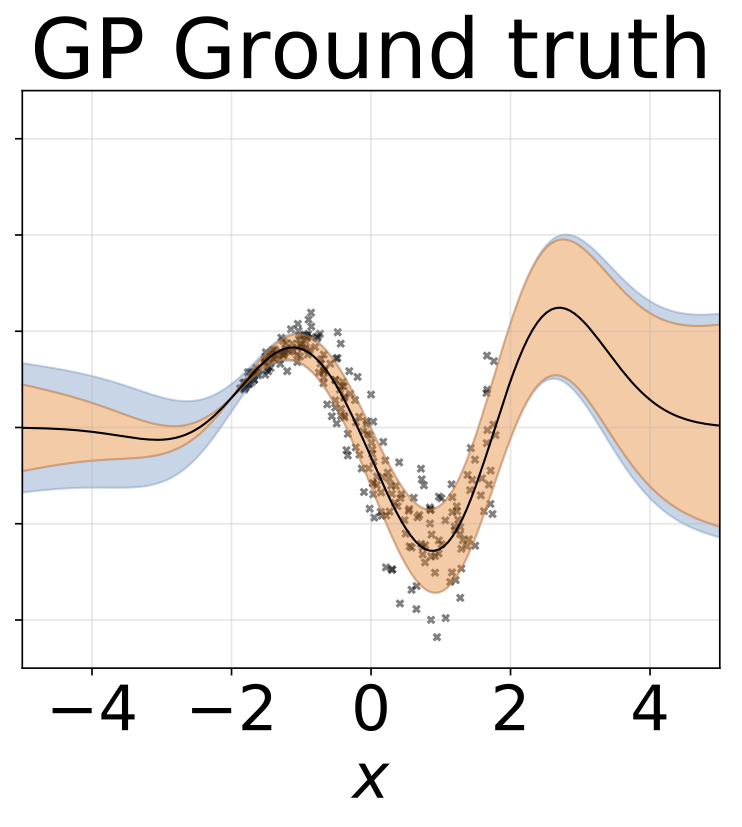
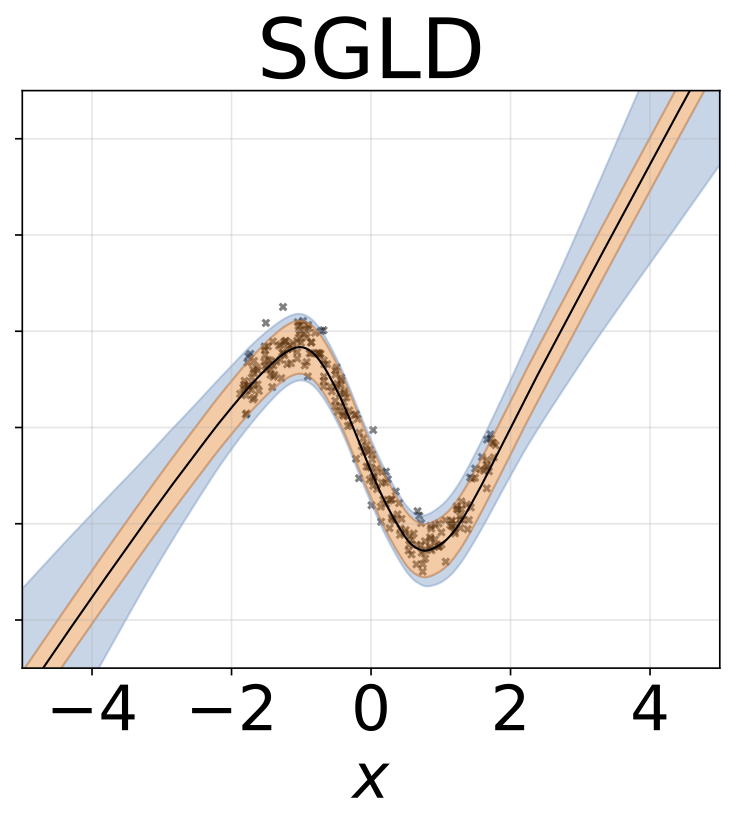
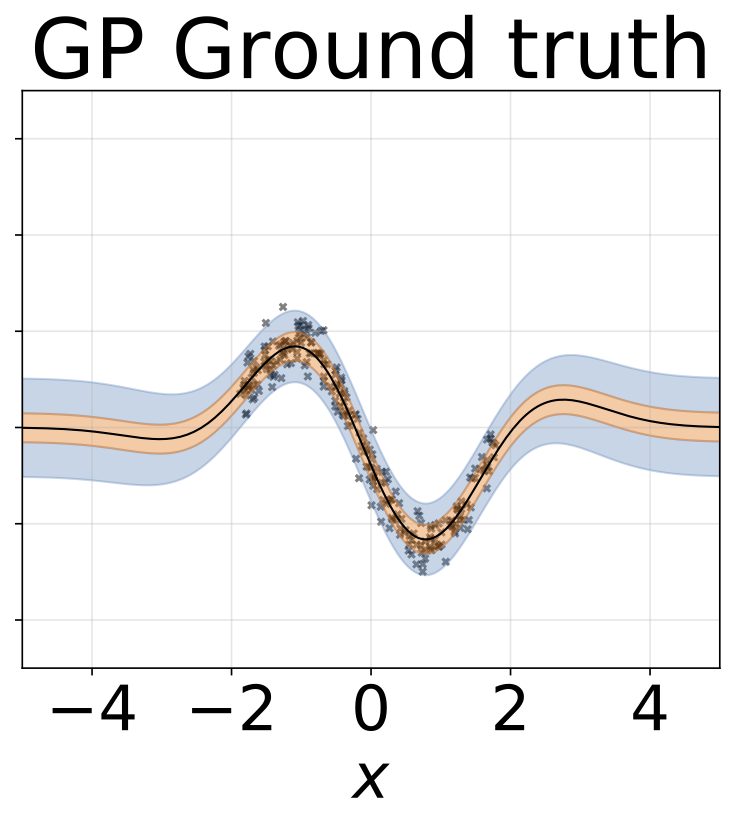
おもちゃの不均一な回帰タスク。データは、RBFカーネル(l =1σn= 0.3・| x + 2 |)のGPによって生成されます。 200レリューユニットを備えた2ヘッドネットワークを使用して、回帰平均μ(x)およびログスタンダード偏差ログσ(x)を予測します。
10-foild Cross Balidationを使用して、6つのUCIデータセット(ハウジング、コンクリート、エネルギー効率、発電所、赤ワイン、ヨットデータセット)でヘテロシュタスティック回帰を実行しました。これらの実験はすべて、ヘテロ脱型ノートブックに含まれています。結果は、ハイパーパラメーターの選択に大きく依存していることに注意してください。以下のプロットは、列車の対数尤度とRMS(半透明色)とテスト(固体色)を示しています。円とエラーバーは、それぞれ10倍のクロス検証平均と標準偏差に対応しています。
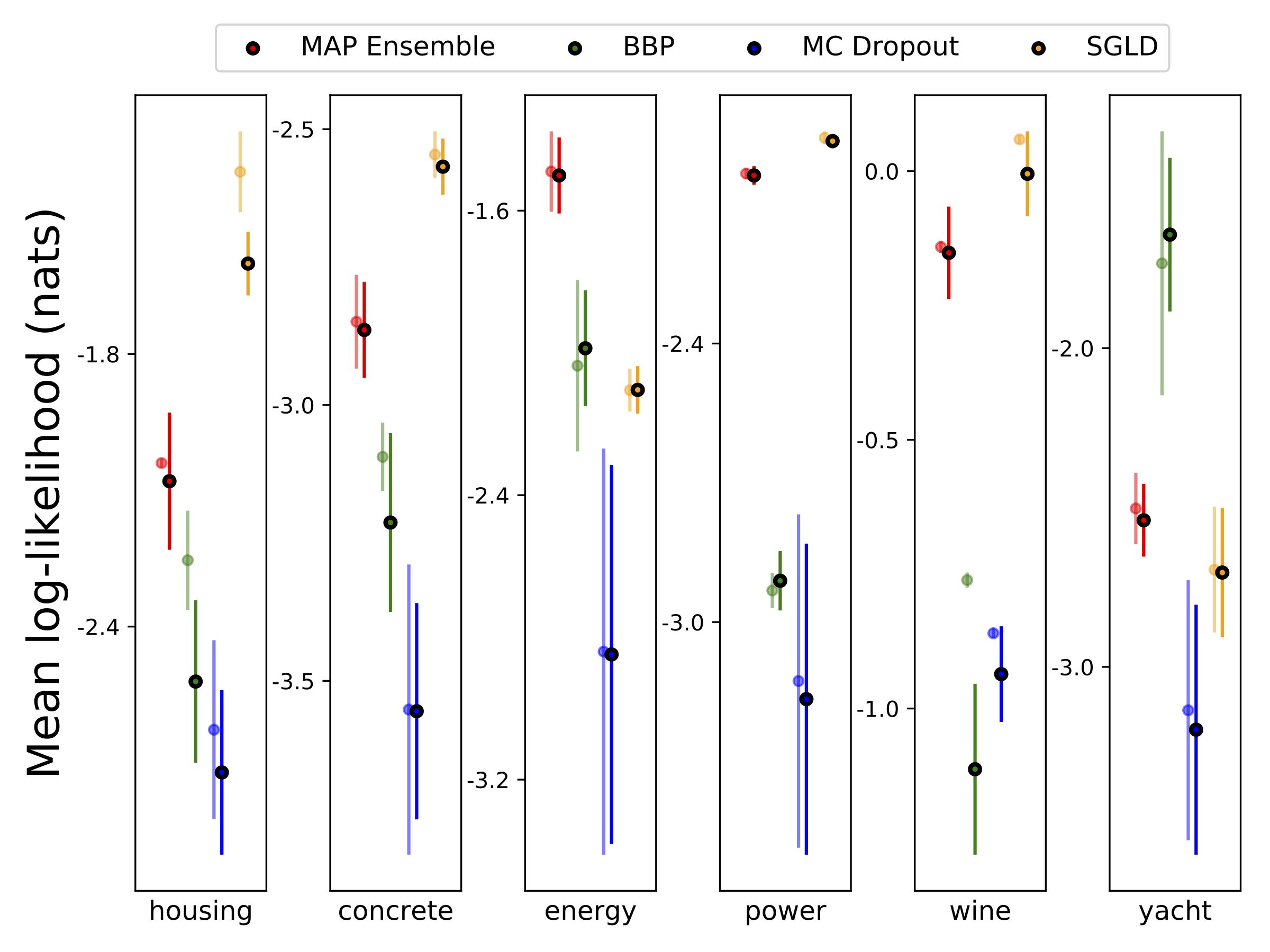
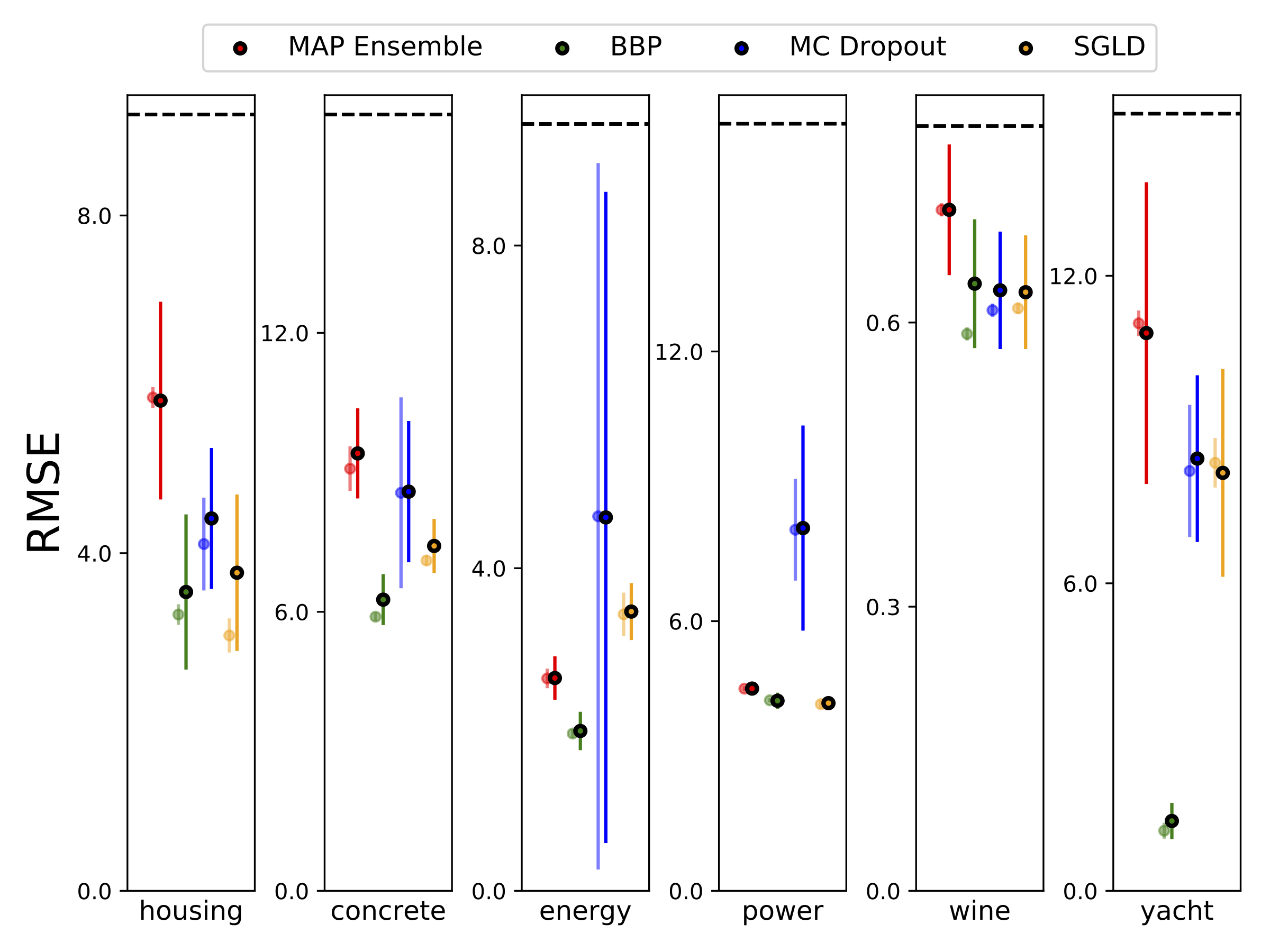
Wは、MAPを除くすべてのモデルの重みの100個のサンプルで疎外され、1セットの重みのみが使用されます。
| Mnistテスト | 地図 | マップアンサンブル | BBPガウス | BBP GMM | BBPラプラス | BBP Local Reparam | MCドロップアウト | SGLD | PSGLD |
|---|---|---|---|---|---|---|---|---|---|
| log like | -572.9 | -496.54 | -1100.29 | -1008.28 | -892.85 | -1086.43 | -435.458 | -828.29 | -661.25 |
| エラー % | 1.58 | 1.53 | 2.60 | 2.38 | 2.28 | 2.61 | 1.37 | 1.76 | 1.76 |
検討中の方法のMNISTテスト結果。エステンジブハイパーパラメーターのチューニングは実行されていません。 100 MCサンプルで事後予測分布を近似します。 2つの1200ユニットのReluレイヤーを備えたFCネットワークを使用します。指定されていない場合、事前はstd = 0.1のガウスです。 P-SGLDはRMSPROP Preconditioningを使用します。
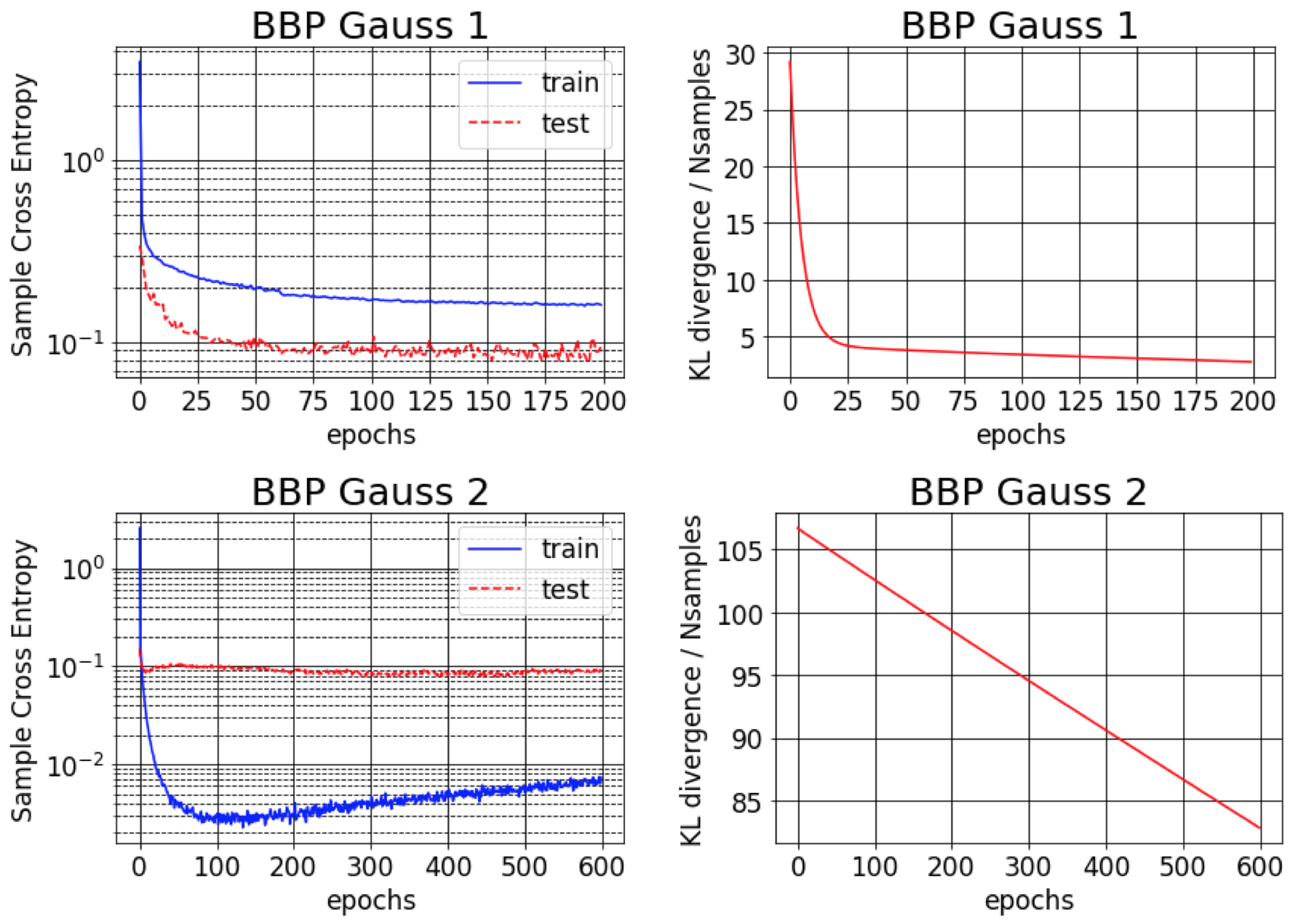
バックプロップによるベイズの元の論文は、MNISTの約1%のエラーを報告しています。この結果は、おおよその後部分散が非常に小さいように初期化されている場合にのみ達成可能であることがわかります(BBP Gauss 2)。このシナリオでは、重量を介した分布はデルタに似ており、良い予測パフォーマンスを提供しますが、不確実性の推定値が悪いと考えています。ただし、以前の(BBPガウス1)に一致するように分散を初期化する場合、上記の結果を取得します。これらの両方のハイパーパラメーター構成スキームのトレーニング曲線を以下に示します。
回転でMNISTテストセットを増強することにより、OODサンプルを作成するときに得られる合計、aleatoric、および認識論的不確実性:
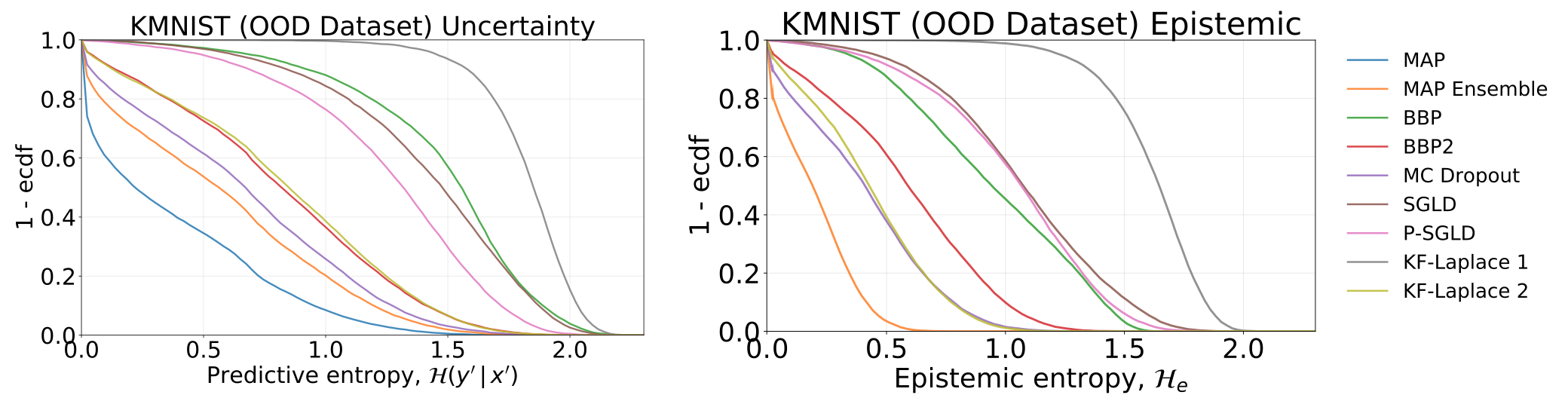
MNISTで訓練されているモデルをテストすることで得られた合計および認識論的不確実性 - KMNISTデータセットで:
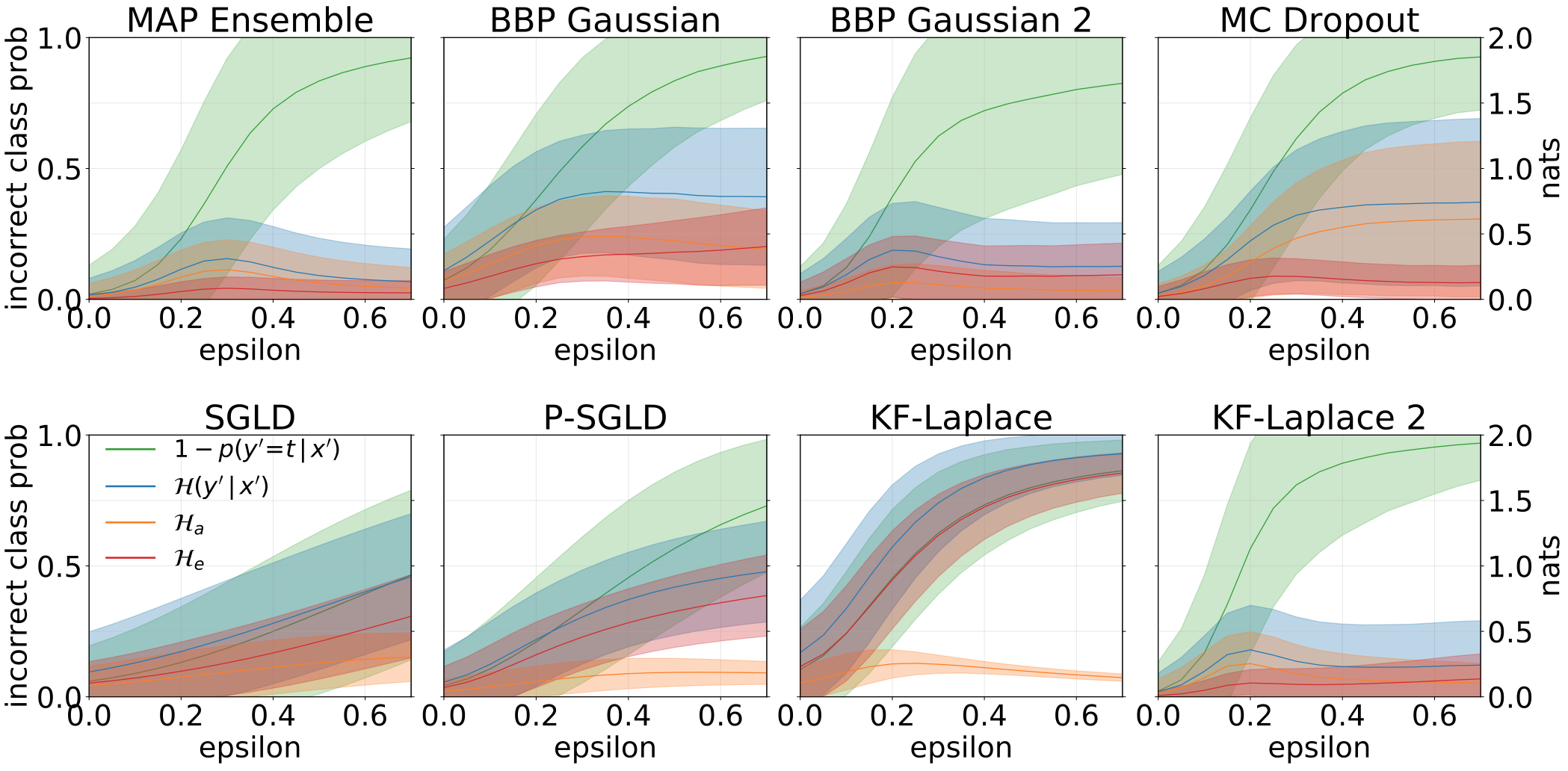
モデルに敵対サンプル(FGSM)を供給するときに得られた、総、aleatoric、および認識論の不確実性。
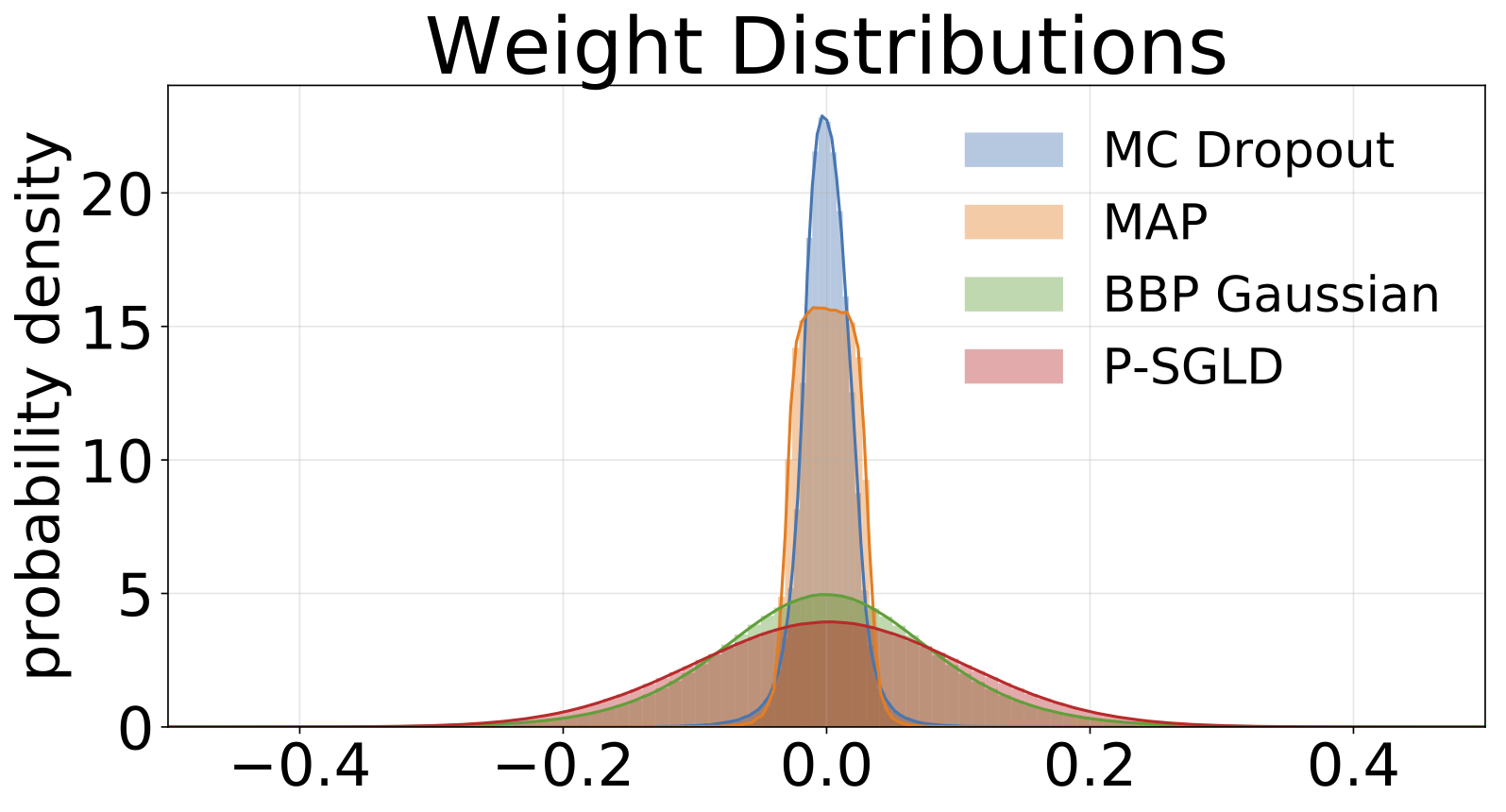
Mnistで訓練された各モデルからサンプリングされた重みのヒストグラム。各モデルに対してWの10サンプルを描画します。
#todo


