swin transformer pytorch
ve Positional Bias
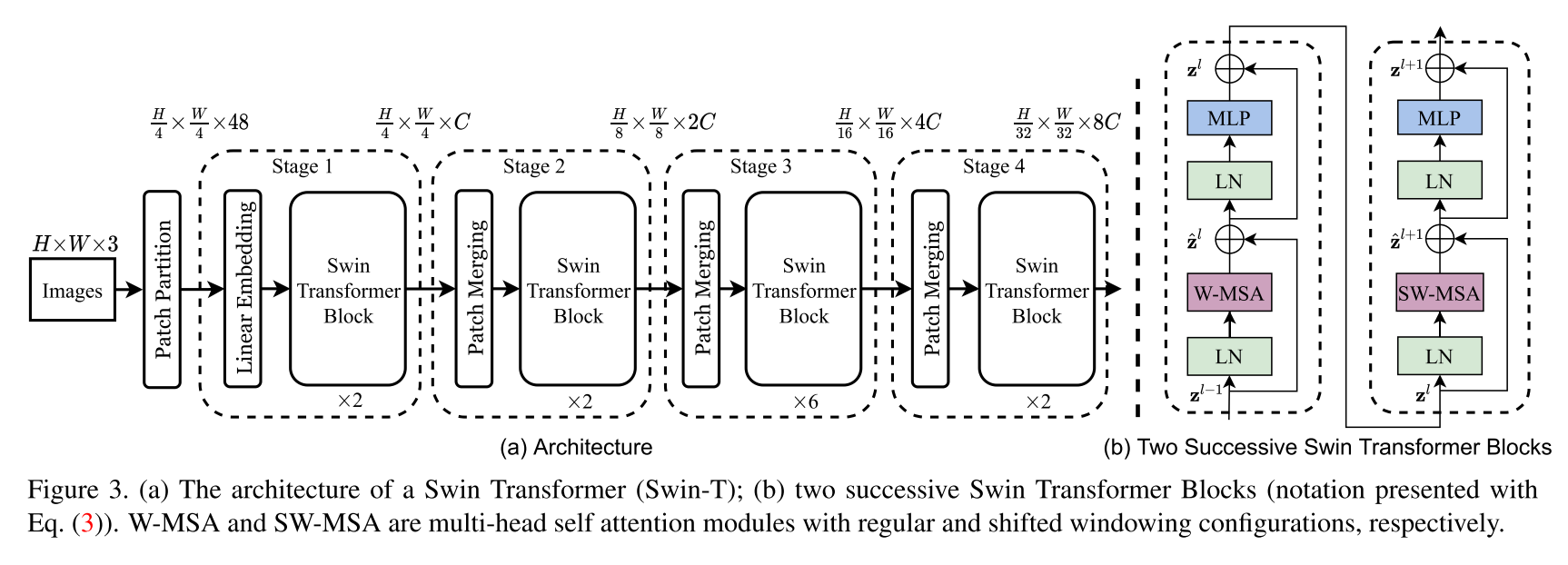
Swin Transformer體系結構的實現。本文提出了一種名為Swin Transformer的New Vision Transformer,它可以作為計算機視覺的通用骨幹。與文本中的單詞相比,圖像中的較大變化和圖像中像素的高分辨率的差異很大,從而使變壓器從語言轉化為視覺的挑戰是由兩個域之間的差異引起的。為了解決這些差異,我們提出了一個層次變壓器,其表示由移動的窗口計算出來。移動的窗戶方案通過將自我發揮的計算限制為非重疊的本地窗口,從而帶來更高的效率,同時還允許交叉窗口連接。該層次結構具有在各種尺度上建模的靈活性,並且相對於圖像大小具有線性計算複雜性。 Swin Transformer的這些質量使其與廣泛的視覺任務兼容,包括圖像分類(Imagenet-1K上的86.4 TOP-1精度)和密集的預測任務,例如對象檢測(58.7 Box AP和51.1 box ap和51.1 box toco test-evev上的蒙版AP)和語義分割(53.5 miou on Ade20k val)。它的性能超過了先前的最新幅度+2.7盒子AP和+2.6 Mask ap在可可上,而ADE20K上的+3.2 MIOU超過了+3.2 MIOU,這表明了基於變壓器的模型作為視覺骨架的潛力。
這不是Swin Transformer的官方存儲庫。目前,作者的官方代碼尚不可用,但稍後可以在以下網址找到:https://github.com/microsoft/swin-transformer。
所有學分都歸作者Ze Liu,Yutong Lin,Yue Cao,Han Hu,Yixuan Wei,Zheng Zhang,Stephen Lin和Baining Guo。
$ pip install swin-transformer-pytorch或(如果您克隆存儲庫)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim :int。layers :INT的4核算可除以2。heads :4核心INTSchannels :int。num_classes :int。head_dim :int。window_size :int。downscaling_factors :4核心。relative_pos_embedding :bool。該代碼的某些部分改編自Pytorch -VisionTransFormer存儲庫https://github.com/lucidrains/vit-pytorch,它提供了一個非常乾淨的VisionTransFormer實現。
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

