swin transformer pytorch
ve Positional Bias
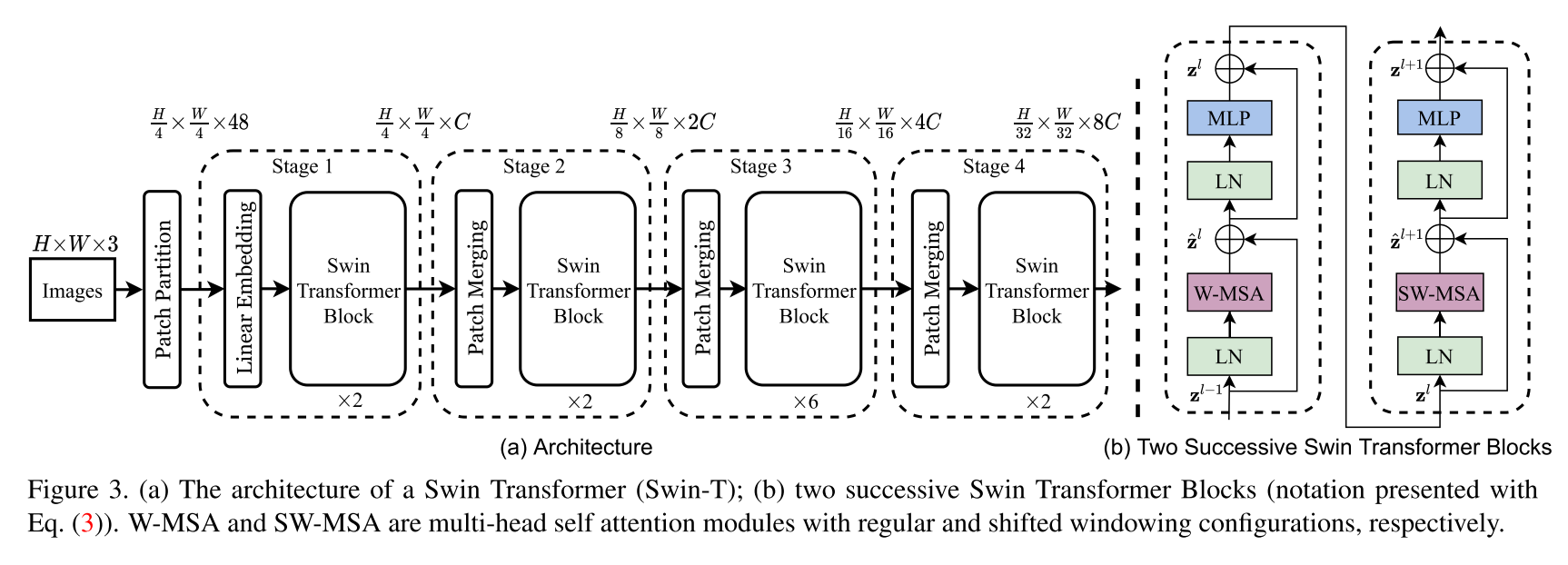
Implementación de la arquitectura del transformador de lanza. Este documento presenta un nuevo transformador de visión, llamado Transformador Swin, que sirve capacitándose como una columna vertebral de uso general para la visión por computadora. Los desafíos en la adaptación del transformador del lenguaje a la visión surgen de las diferencias entre los dos dominios, como las grandes variaciones en la escala de las entidades visuales y la alta resolución de los píxeles en las imágenes en comparación con las palabras en el texto. Para abordar estas diferencias, proponemos un transformador jerárquico cuya representación se calcula con ventanas desplazadas. El esquema de ventanas desplazados trae una mayor eficiencia al limitar el cálculo de autoatención a las ventanas locales no superpuestas al tiempo que permite una conexión de ventana cruzada. Esta arquitectura jerárquica tiene la flexibilidad de modelar a varias escalas y tiene complejidad computacional lineal con respecto al tamaño de la imagen. Estas cualidades del transformador Swin lo hacen compatible con una amplia gama de tareas de visión, incluida la clasificación de imágenes (86.4 Top-1 precisión en ImageNet-1K) y tareas de predicción densa como la detección de objetos (58.7 Box AP y 51.1 enmascaran AP en Coco-DEV) y segmentación semántica (53.5 Miou en ADE20K Val). Su rendimiento supera el estado anterior del arte por un gran margen de +2.7 Box AP y +2.6 Mask AP en Coco, y +3.2 Miou en ADE20K, lo que demuestra el potencial de los modelos basados en transformadores como backbons de visión.
Este no es el repositorio oficial del transformador de giro. En este momento, el código oficial de los autores aún no está disponible, pero se puede encontrar más tarde en: https://github.com/microsoft/swin-transformer.
Todos los créditos van a los autores Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin y Baining Guo.
$ pip install swin-transformer-pytorcho (si clona el repositorio)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim : int.layers : 4-Tuple de INTS Divisible por 2.heads : 4-Tuple de INTSchannels : int.num_classes : int.head_dim : int.window_size : int.downscaling_factors : 4-Tuple de INTS.relative_pos_embedding : bool.Alguna parte del código está adaptada del repositorio de Pytorch - VisionTransformer https://github.com/lucidrains/vit-pytorch, que proporciona una implementación de VisionTransformer muy limpia para comenzar.
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

