swin transformer pytorch
ve Positional Bias
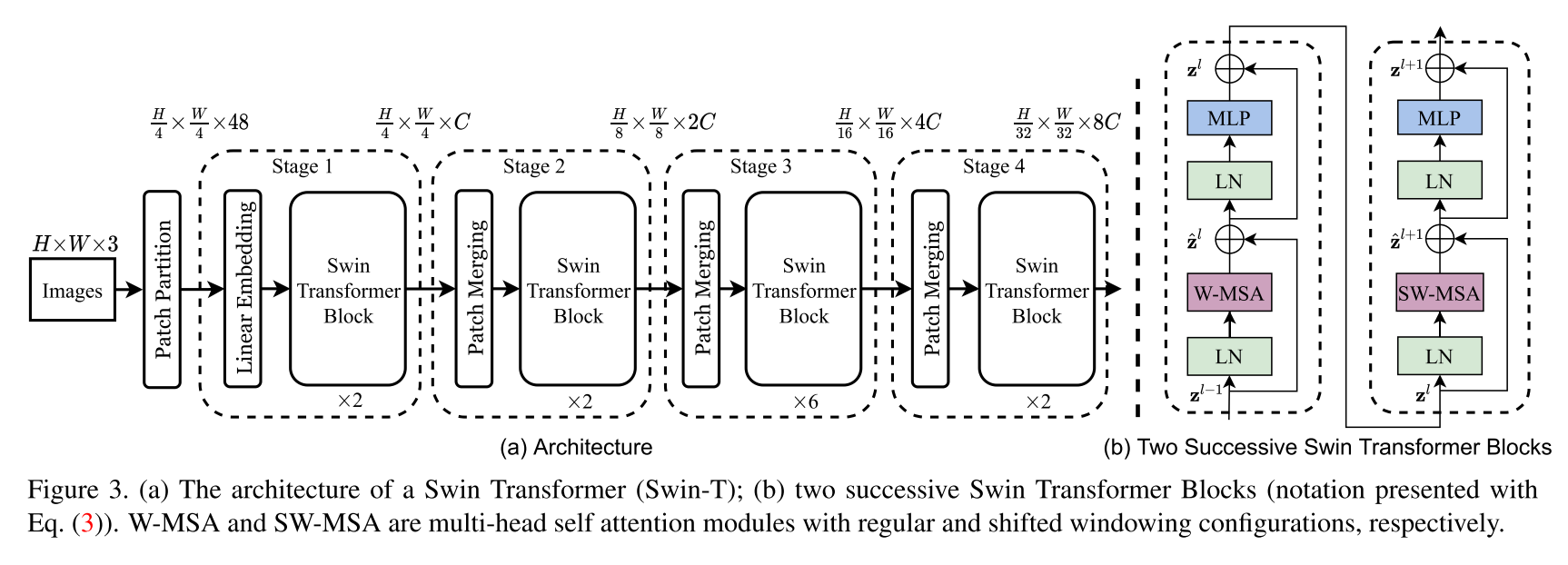
Implementasi Arsitektur Transformator Swin. Makalah ini menyajikan transformator visi baru, yang disebut Swin Transformer, yang mampu berfungsi sebagai tulang punggung tujuan umum untuk visi komputer. Tantangan dalam mengadaptasi transformator dari bahasa ke visi muncul dari perbedaan antara kedua domain, seperti variasi besar dalam skala entitas visual dan resolusi tinggi piksel dalam gambar dibandingkan dengan kata -kata dalam teks. Untuk mengatasi perbedaan -perbedaan ini, kami mengusulkan transformator hierarkis yang perwakilannya dihitung dengan jendela bergeser. Skema windowing yang bergeser membawa efisiensi yang lebih besar dengan membatasi perhitungan swadaya pada jendela lokal yang tidak tumpang tindih sementara juga memungkinkan untuk koneksi silang. Arsitektur hierarkis ini memiliki fleksibilitas untuk memodelkan pada berbagai skala dan memiliki kompleksitas komputasi linier sehubungan dengan ukuran gambar. Kualitas transformator Swin ini membuatnya kompatibel dengan berbagai tugas penglihatan, termasuk klasifikasi gambar (86,4 akurasi top-1 pada imagenet-1k) dan tugas prediksi padat seperti deteksi objek (58,7 kotak AP dan 51,1 topeng AP pada coco test-dev) dan segmentasi semantik (53,5 miou katup ade20kk coco). Kinerja melampaui canggih sebelumnya dengan margin besar +2.7 kotak AP dan +2.6 mask AP pada Coco, dan +3.2 MIOU pada ADE20K, menunjukkan potensi model berbasis transformator sebagai tulang punggung visi.
Ini bukan repositori resmi dari Swin Transformer. Saat ini kode resmi penulis belum tersedia tetapi dapat ditemukan nanti di: https://github.com/microsoft/swin-transformer.
Semua kredit pergi ke penulis Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin dan Baining Guo.
$ pip install swin-transformer-pytorchatau (jika Anda mengkloning repositori)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim : int.layers : 4-tuple dari INTS dapat dibagi dengan 2.heads : 4-tuple of intschannels : Int.num_classes : int.head_dim : int.window_size : int.downscaling_factors : 4-tuple of ints.relative_pos_embedding : bool.Beberapa bagian dari kode diadaptasi dari repositori Pytorch - VisionTransformer https://github.com/lucidrains/vit-pytorch, yang menyediakan implementasi visionransformer yang sangat bersih untuk memulai.
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

