swin transformer pytorch
ve Positional Bias
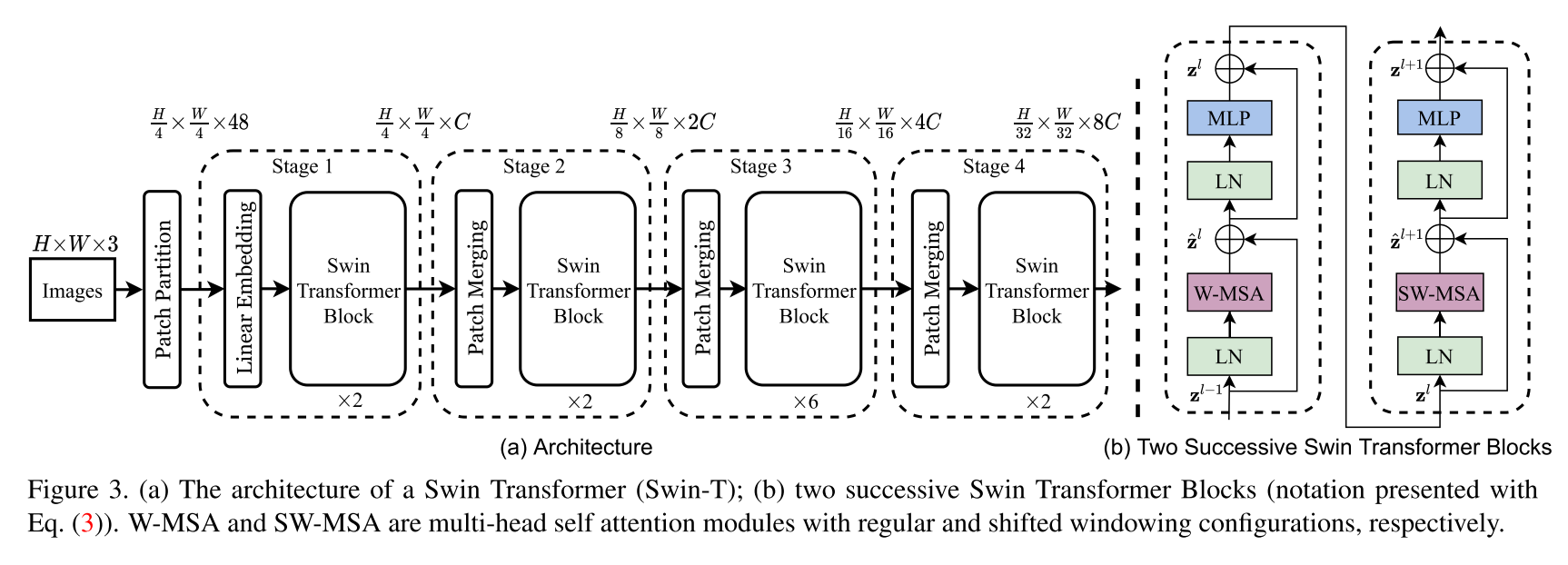
Mise en œuvre de l'architecture Swin Transformer. Cet article présente un nouveau transformateur de vision, appelé Swin Transformer, qui sert de manière capable de squelette à usage général pour la vision par ordinateur. Les défis dans l'adaptation du transformateur du langage à la vision découlent des différences entre les deux domaines, tels que de grandes variations de l'échelle des entités visuelles et la haute résolution des pixels dans les images par rapport aux mots du texte. Pour répondre à ces différences, nous proposons un transformateur hiérarchique dont la représentation est calculée avec des fenêtres décalées. Le schéma de fenêtres décalé apporte une plus grande efficacité en limitant le calcul d'auto-attention aux fenêtres locales non chevauchantes tout en permettant une connexion croisée. Cette architecture hiérarchique a la flexibilité de modéliser à différentes échelles et a une complexité de calcul linéaire par rapport à la taille de l'image. Ces qualités de Swin Transformer le rendent compatible avec une large gamme de tâches de vision, y compris la classification des images (86,4 Top-1 précision sur ImageNet-1k) et des tâches de prédiction denses telles que la détection d'objets (58,7 Box AP et 51.1 Mask AP sur Coco Test-DEV) et segmentation sémantique (53,5 miou sur l'EDE20K Val). Ses performances dépasse l'état de l'état précédent par une grande marge de +2,7 boîte AP et +2,6 masque AP sur CoCo, et +3,2 Miou sur ADE20K, démontrant le potentiel des modèles basés sur les transformateurs comme squelette de vision.
Ce n'est pas le référentiel officiel du transformateur SWIN. À l'heure actuelle, le code officiel des auteurs n'est pas encore disponible, mais peut être trouvé plus tard à: https://github.com/microsoft/swin-transformateur.
Tous les crédits vont aux auteurs Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin et Baining Guo.
$ pip install swin-transformer-pytorchou (si vous clonez le référentiel)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim : int.layers : 4-Tuple of INTS Divisible par 2.heads : 4-tupiles d'INTSchannels : Int.num_classes : int.head_dim : int.window_size : int.downscaling_factors : 4-Tuple of INTS.relative_pos_embedding : bool.Une partie du code est adaptée du référentiel Pytorch - VisionTransformateur https://github.com/lucidrains/vit-pytorch, qui fournit une implémentation VisionTransformateur très propre pour commencer.
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

