swin transformer pytorch
ve Positional Bias
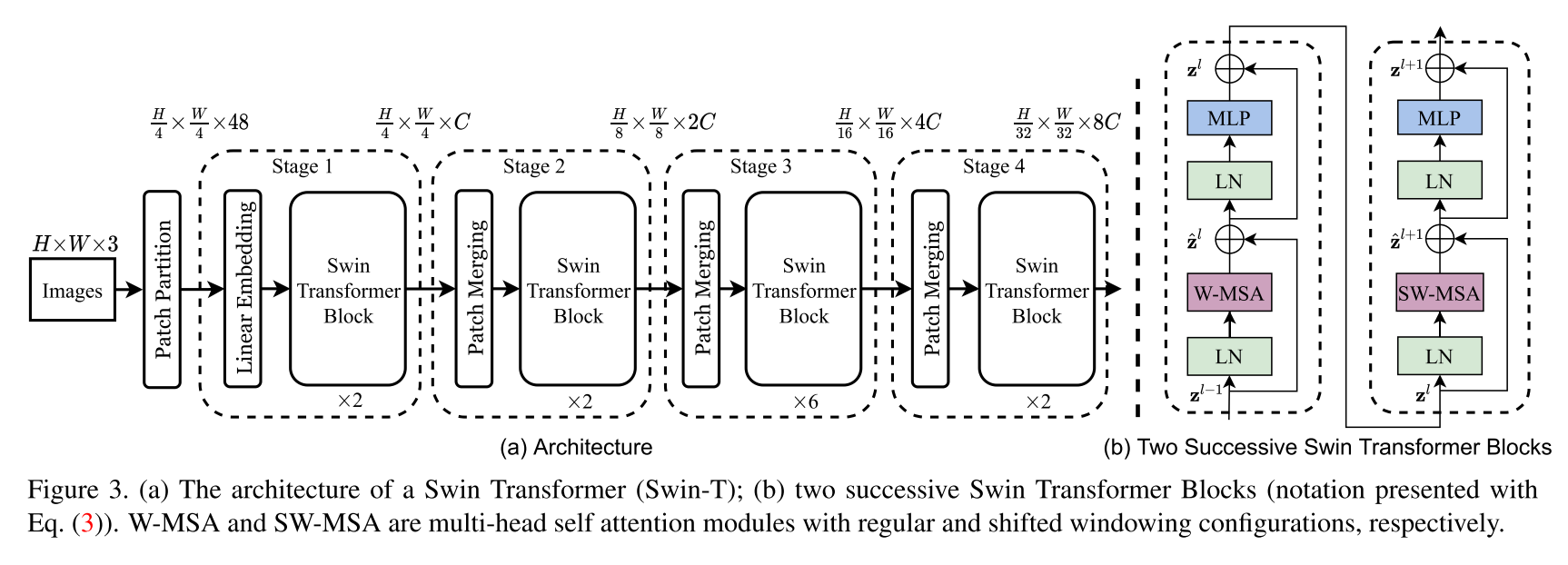
Swin Transformer Architectureの実装。このホワイトペーパーでは、Swin Transformerと呼ばれる新しいビジョントランスを紹介します。これは、コンピュータービジョンの汎用バックボーンとして機能する可能性があります。トランスを言語からビジョンに適応させる際の課題は、視覚エンティティのスケールの大きなバリエーションや、テキストの単語と比較して画像のピクセルの高解像度など、2つのドメイン間の違いから生じます。これらの違いに対処するために、表現がシフトされたウィンドウで計算される階層変圧器を提案します。シフトされたウィンドウスキームは、自己関節計算を重複しないローカルウィンドウに制限すると同時に、クロスウィンドウ接続を可能にすることにより、より大きな効率をもたらします。この階層アーキテクチャは、さまざまなスケールでモデル化する柔軟性があり、画像サイズに関して線形計算の複雑さを持っています。 Swin Transformerのこれらの品質により、画像分類(Imagenet-1Kの86.4 Top-1精度)や、オブジェクト検出(CoCO Test-DEVの58.7ボックスAPおよび51.1マスクAP)およびセマンティックセグメンテーション(Ade20K Valの53.5 MIOU)などの密な予測タスクを含む幅広いビジョンタスクと互換性があります。そのパフォーマンスは、ココの+2.7ボックスAPと+2.6マスクAPの大きなマージン、およびADE20Kの+3.2 MIOUで以前の最先端を上回り、変圧器ベースのモデルがビジョンバックボーンとしての可能性を示しています。
これは、SWINトランスの公式リポジトリではありません。現時点では、著者の公式コードはまだ利用できませんが、後でhttps://github.com/microsoft/swin-transformerにあります。
すべてのクレジットは、著者のゼリウ、ユトン・リン、ユエ・カオ、ハン・フー、Yixuan Wei、Zheng Zhang、Stephen Lin、およびBaining Guoに送られます。
$ pip install swin-transformer-pytorchまたは(リポジトリをクローンする場合)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim :int。layers :2で分割可能な4タプル。heads :4タプルのINTchannels :int。num_classes :int。head_dim :int。window_size :int。downscaling_factors :4-tuple of ints。relative_pos_embedding :bool。コードの一部は、Pytorch -Vision Transformerリポジトリhttps://github.com/lucidrains/vit-pytorchから採用されています。
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

