swin transformer pytorch
ve Positional Bias
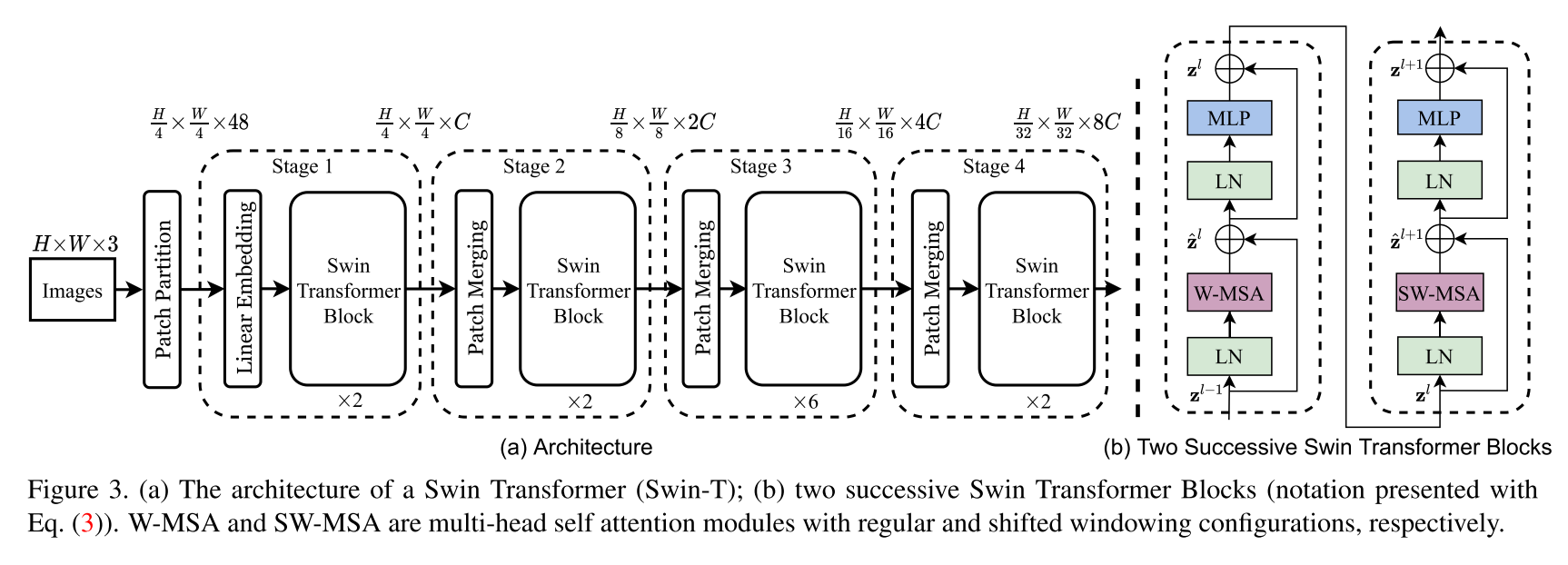
Implementação da arquitetura do transformador SWIN. Este artigo apresenta um novo transformador de visão, chamado Swin Transformer, que serve de maneira capaz como um backbone de uso geral para a visão computacional. Os desafios na adaptação do transformador da linguagem para a visão surgem das diferenças entre os dois domínios, como grandes variações na escala de entidades visuais e a alta resolução de pixels nas imagens em comparação com as palavras no texto. Para abordar essas diferenças, propomos um transformador hierárquico cuja representação é calculada com janelas deslocadas. O esquema de janela deslocado traz maior eficiência, limitando a computação de auto-atendimento a janelas locais sem sobreposição, além de permitir a conexão entre as janelas. Essa arquitetura hierárquica tem a flexibilidade de modelar em várias escalas e possui complexidade computacional linear em relação ao tamanho da imagem. Essas qualidades do transformador de SWIN tornam compatível com uma ampla gama de tarefas de visão, incluindo classificação de imagem (precisão 86.4 TOP-1 no ImageNet-1K) e tarefas densas de previsão, como detecção de objetos (58.7 Box AP e 51.1 Mask AP no Coco-test) e segmentação semântica (53,5 Miou em ADE20. Seu desempenho ultrapassa o estado da arte anterior por uma grande margem de +2,7 AP e +2,6 máscara AP no Coco e +3,2 miou no Ade20K, demonstrando o potencial dos modelos baseados em transformadores como backbones da visão.
Este não é o repositório oficial do transformador Swin. No momento, o código oficial dos autores ainda não está disponível, mas pode ser encontrado posteriormente em: https://github.com/microsoft/swin-transformer.
Todos os créditos vão para os autores Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin e Baining Guo.
$ pip install swin-transformer-pytorchou (se você clonar o repositório)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim : int.layers : 4-Tuple of Ints divisível por 2.heads : 4-tupla de intschannels : int.num_classes : int.head_dim : int.window_size : int.downscaling_factors : 4-Tuple of Ints.relative_pos_embedding : bool.Alguma parte do código é adaptada do repositório Pytorch - VisionTransformer https://github.com/lucidrains/vit-pytorch, que fornece uma implementação muito limpa do VisionTransformer.
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

