swin transformer pytorch
ve Positional Bias
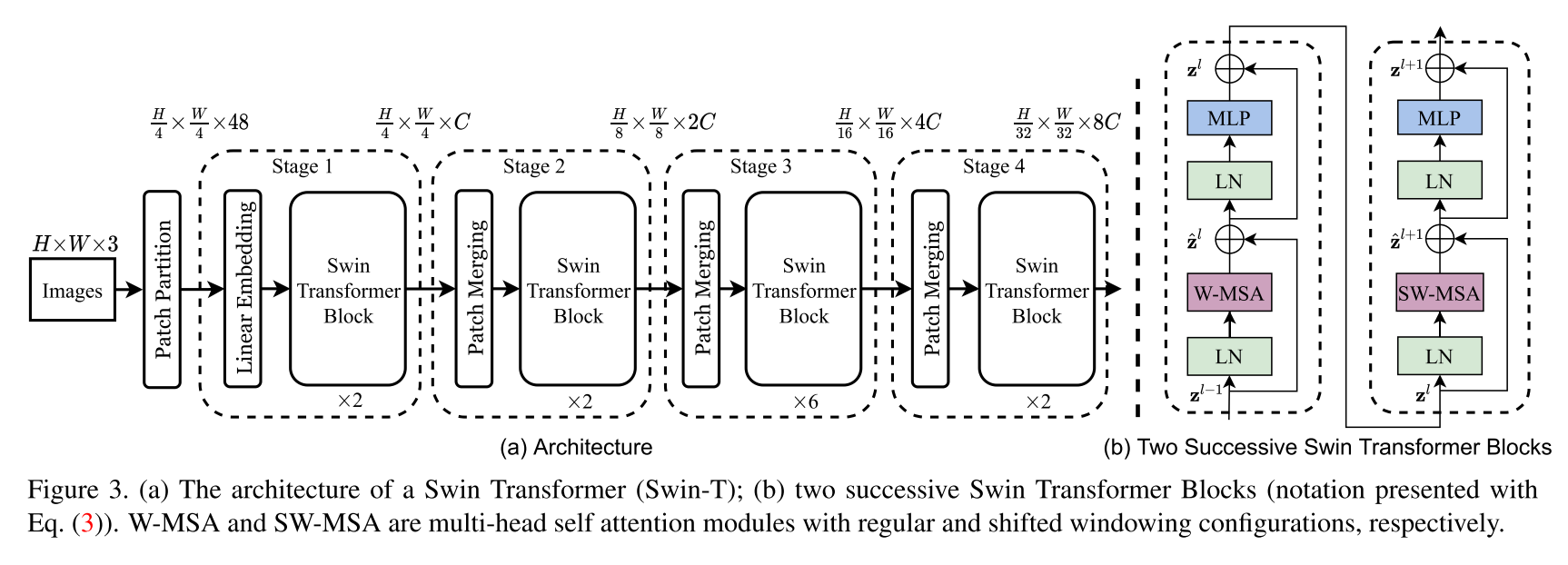
Реализация архитектуры трансформатора SUN. В этом документе представлен новый трансформатор зрения, называемый Swin Transformer, который способен служить общим видом на компьютерное зрение. Проблемы в адаптации трансформатора от языка к зрения возникают из -за различий между двумя областями, такими как большие вариации в масштабе визуальных сущностей и высокое разрешение пикселей на изображениях по сравнению со словами в тексте. Чтобы решить эти различия, мы предлагаем иерархический трансформатор, представление которого вычисляется с помощью смещенных окон. Схема смещенной окна обеспечивает большую эффективность, ограничивая вычисление самостоятельного присмотра в непересекающиеся локальные окна, а также позволяет подключить к секунду. Эта иерархическая архитектура обладает гибкостью для моделирования в различных масштабах и имеет линейную вычислительную сложность в отношении размера изображения. Эти качества трансформатора SUN делают его совместимым с широким диапазоном задач зрения, включая классификацию изображений (86,4 Топорта-1 точность на ImageNet-1K) и задачи плотного прогнозирования, такие как обнаружение объекта (58,7 ящика AP и 51.1 Mask AP на кокосовом тестовом деве) и семантическая сегментация (53,5 MIO на AD20K Val). Его производительность превосходит предыдущий современный Art с большим отрывом +2,7 AP и AP +2,6 AP +2,6 на COCO и +3,2 MIO на ADE20K, демонстрируя потенциал моделей на основе трансформаторов в качестве основополагающих видов.
Это не официальный репозиторий Suin Transformer. В настоящее время официальный код авторов еще не доступен, но его можно найти позже по адресу: https://github.com/microsoft/swin-transformer.
Все титры обращаются к авторам Зе Лю, Ютунг Лин, Юэ Цао, Хан Ху, Иксуану Вэй, Чжэн Чжан, Стивен Лин и Бинг Гу.
$ pip install swin-transformer-pytorchили (если вы клонируете репозиторий)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim : int.layers : 4-й тупе INT, делится на 2.heads : 4-й тупе INTchannels : инт.num_classes : int.head_dim : int.window_size : int.downscaling_factors : 4-й-тускли INT.relative_pos_embedding : bool.Некоторая часть кода адаптирована из репозитория Pytorch - VisionTransformer https://github.com/lucidrains/vit-pytorch, которая обеспечивает очень чистую реализацию Vision Transformer для начала.
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

