swin transformer pytorch
ve Positional Bias
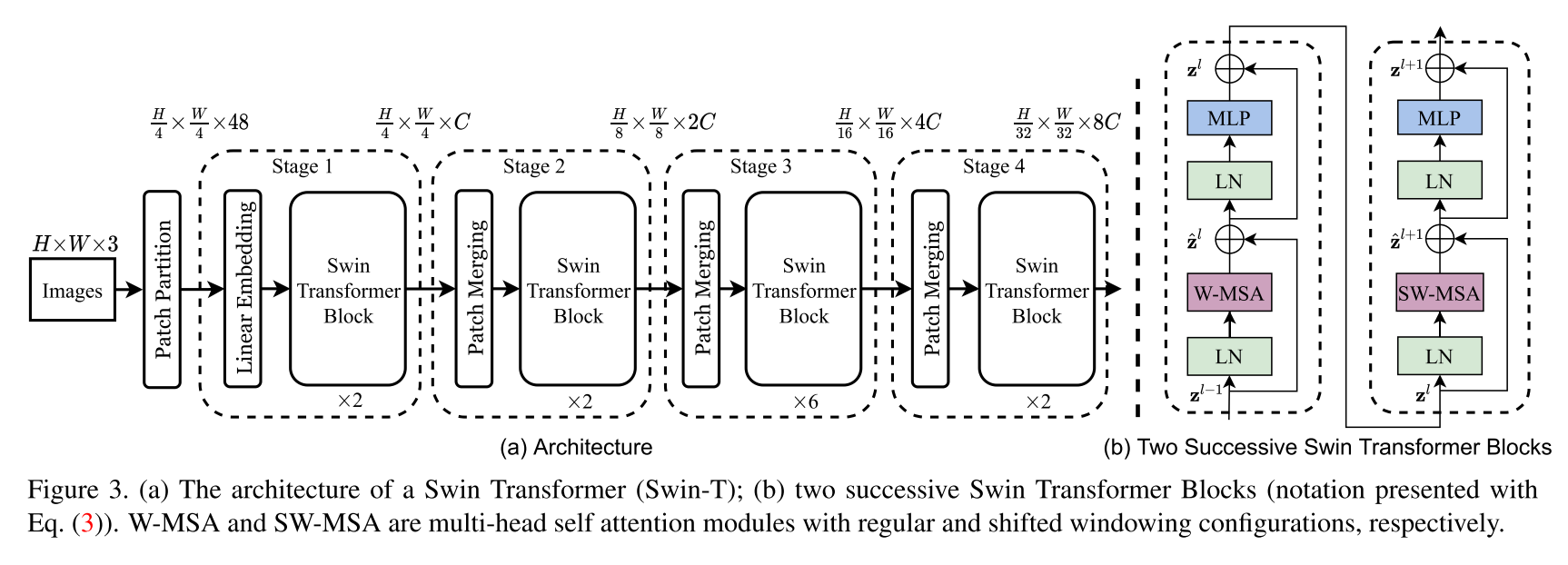
Implementierung der Swin -Transformer -Architektur. Dieses Papier präsentiert einen neuen Vision-Transformator, der Swin Transformator namens Swin Transformator, der in der Lage als allgemeines Rückgrat für Computer Vision dient. Herausforderungen bei der Anpassung des Transformators von Sprache zu Vision ergeben sich aus Unterschieden zwischen den beiden Domänen, wie z. Um diese Unterschiede anzugehen, schlagen wir einen hierarchischen Transformator vor, dessen Darstellung mit veränderten Fenstern berechnet wird. Das verschobene Fensterschema führt zu einer größeren Effizienz, indem die Selbstbekämpfungsberechnung auf nicht überlappende lokale Fenster beschränkt und gleichzeitig eine Cross-Window-Verbindung ermöglicht wird. Diese hierarchische Architektur hat die Flexibilität, auf verschiedenen Maßstäben zu modellieren und in Bezug auf die Bildgröße eine lineare rechnerische Komplexität. Diese Qualitäten des Swin-Transformators machen es mit einer breiten Palette von Sehvermögen kompatibel, einschließlich Bildklassifizierung (86.4 Top-1-Genauigkeit auf ImageNet-1K) und dichten Vorhersageaufgaben wie Objekterkennung (58,7 Box AP und 51.1 Mask AP auf Coco-Test-Dev) und semantischer Segmentierung (53,5 Miou auf Ade20K Val). Seine Leistung übertrifft die vorherige hochmoderne Leistung mit einem großen Rand von +2,7 Box AP und +2,6 Mask AP auf CoCo und +3,2 Miou auf ADE20K, was das Potenzial von transformatorbasierten Modellen als Sehklemme zeigt.
Dies ist nicht das offizielle Repository des Swin -Transformators. Im Moment ist der offizielle Code der Autoren noch nicht verfügbar, kann aber später unter: https://github.com/microsoft/swin-transformer gefunden werden.
Alle Credits gehen an die Autoren Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin und Baining Guo.
$ pip install swin-transformer-pytorchoder (wenn Sie das Repository klonen)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim : int.layers : 4-Tuple of INTs teilbar durch 2.heads : 4-Tuple of INTschannels : int.num_classes : int.head_dim : int.window_size : int.downscaling_factors : 4-Tuple of INTs.relative_pos_embedding : bool.Ein Teil des Codes ist aus dem Pytorch - VisionTransformer Repository https://github.com/lucidrains/vit-pytorch angepasst, das zunächst eine sehr saubere Visiontransformer -Implementierung bietet.
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

