swin transformer pytorch
ve Positional Bias
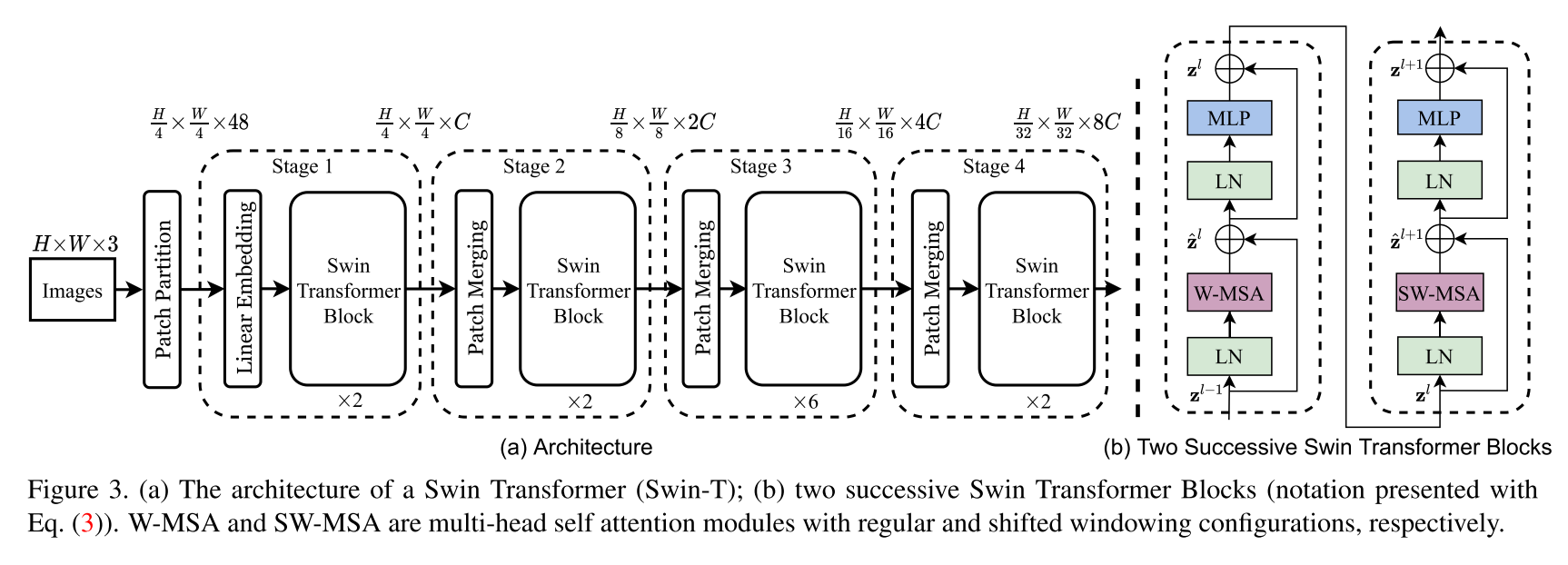
Swin Transformer体系结构的实现。本文提出了一种名为Swin Transformer的New Vision Transformer,它可以作为计算机视觉的通用骨干。与文本中的单词相比,图像中的较大变化和图像中像素的高分辨率的差异很大,从而使变压器从语言转化为视觉的挑战是由两个域之间的差异引起的。为了解决这些差异,我们提出了一个层次变压器,其表示由移动的窗口计算出来。移动的窗户方案通过将自我发挥的计算限制为非重叠的本地窗口,从而带来更高的效率,同时还允许交叉窗口连接。该层次结构具有在各种尺度上建模的灵活性,并且相对于图像大小具有线性计算复杂性。 Swin Transformer的这些质量使其与广泛的视觉任务兼容,包括图像分类(Imagenet-1K上的86.4 TOP-1精度)和密集的预测任务,例如对象检测(58.7 Box AP和51.1 box ap和51.1 box toco test-evev上的蒙版AP)和语义分割(53.5 miou on Ade20k val)。它的性能超过了先前的最新幅度+2.7盒子AP和+2.6 Mask ap在可可上,而ADE20K上的+3.2 MIOU超过了+3.2 MIOU,这表明了基于变压器的模型作为视觉骨架的潜力。
这不是Swin Transformer的官方存储库。目前,作者的官方代码尚不可用,但稍后可以在以下网址找到:https://github.com/microsoft/swin-transformer。
所有学分都归作者Ze Liu,Yutong Lin,Yue Cao,Han Hu,Yixuan Wei,Zheng Zhang,Stephen Lin和Baining Guo。
$ pip install swin-transformer-pytorch或(如果您克隆存储库)
$ pip install -r requirements.txt import torch
from swin_transformer_pytorch import SwinTransformer
net = SwinTransformer (
hidden_dim = 96 ,
layers = ( 2 , 2 , 6 , 2 ),
heads = ( 3 , 6 , 12 , 24 ),
channels = 3 ,
num_classes = 3 ,
head_dim = 32 ,
window_size = 7 ,
downscaling_factors = ( 4 , 2 , 2 , 2 ),
relative_pos_embedding = True
)
dummy_x = torch . randn ( 1 , 3 , 224 , 224 )
logits = net ( dummy_x ) # (1,3)
print ( net )
print ( logits )hidden_dim :int。layers :INT的4核算可除以2。heads :4核心INTSchannels :int。num_classes :int。head_dim :int。window_size :int。downscaling_factors :4核心。relative_pos_embedding :bool。该代码的某些部分改编自Pytorch -VisionTransFormer存储库https://github.com/lucidrains/vit-pytorch,它提供了一个非常干净的VisionTransFormer实现。
@misc { liu2021swin ,
title = { Swin Transformer: Hierarchical Vision Transformer using Shifted Windows } ,
author = { Ze Liu and Yutong Lin and Yue Cao and Han Hu and Yixuan Wei and Zheng Zhang and Stephen Lin and Baining Guo } ,
year = { 2021 } ,
eprint = { 2103.14030 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

