CCNet
1.0.0
紙質鏈接:我們最新的TPAMI版本,具有改進和擴展(較早的ICCV版本)。
Zilong Huang,Xinggang Wang,Yunchao Wei,Lichao Huang,Chang Huang,Humphrey Shi,Wenyu Liu和Thomas S. Huang。
2021/02:CCNET的純Python實現在分支純Python中發布。感謝Serge-Weihao。
2019/08:新版本CCNET在Branch Pytorch-1.1上發布,該Branch Pytorch-1.1支持Pytorch 1.0或更高版本,並分佈式多處理培訓和測試此當前代碼是對CCNET ICCV版本中CityScapes的實驗的實現。我們基於開源Pytorch分段工具箱實現我們的方法。
2018/12:續訂r = 1,2的代碼和釋放訓練的模型。 R = 2的訓練模型在Val設置上實現了79.74%,並在單尺測試的測試集上實現了79.01%。
2018/11:發布代碼。
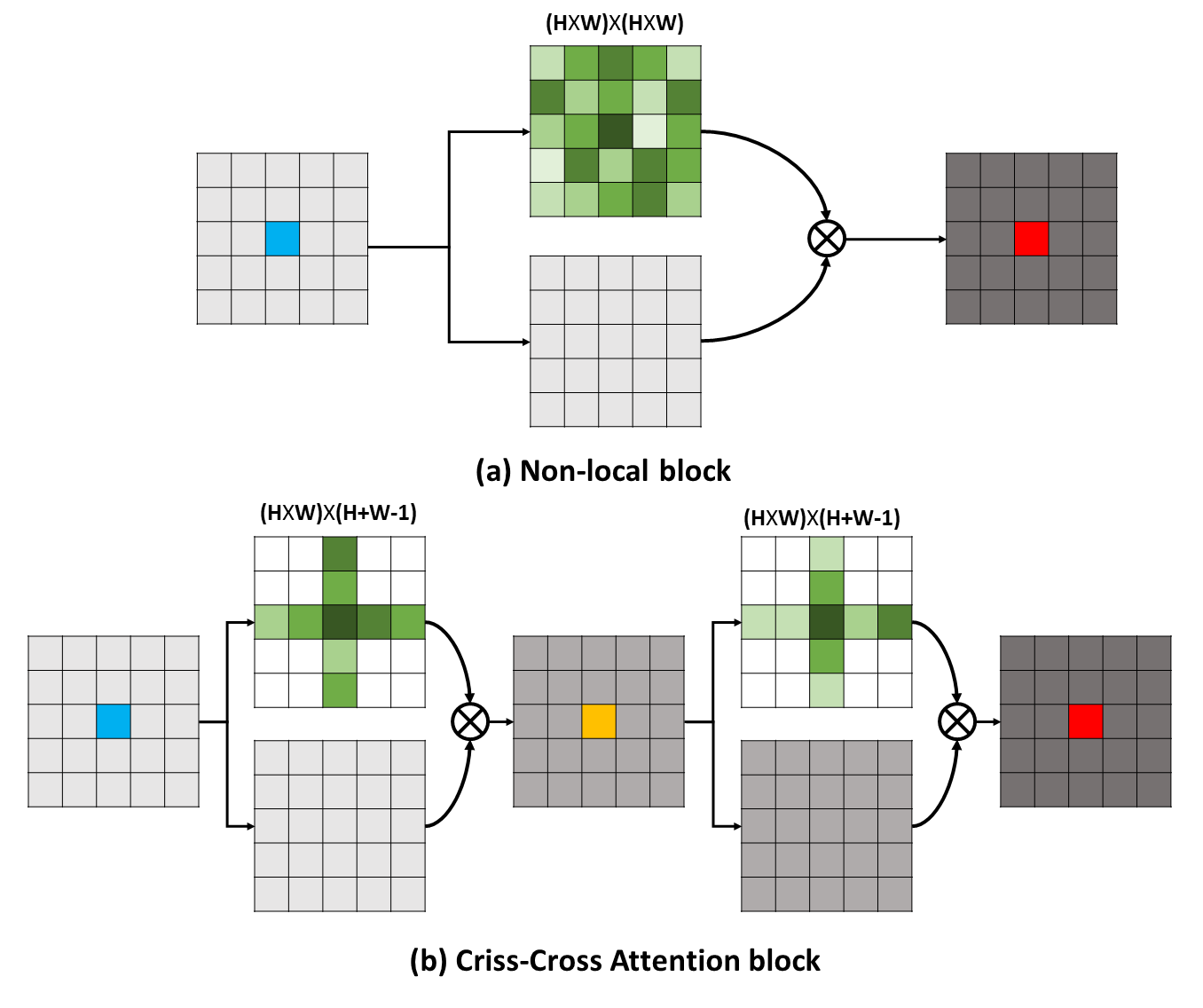 長期依賴性可以捕獲有用的上下文信息,以使視覺理解問題受益。在這項工作中,我們提出了一個縱橫交錯的網絡(CCNET),以通過更有效和有效的方式獲得此類重要信息。具體而言,對於每個像素,我們的CCNet可以通過新型的縱橫交錯的注意模塊收集其周圍像素的上下文信息。通過進行進一步的複發操作,每個像素最終可以從所有像素中捕獲遠程依賴性。總體而言,我們的CCNET具有以下優點:
長期依賴性可以捕獲有用的上下文信息,以使視覺理解問題受益。在這項工作中,我們提出了一個縱橫交錯的網絡(CCNET),以通過更有效和有效的方式獲得此類重要信息。具體而言,對於每個像素,我們的CCNet可以通過新型的縱橫交錯的注意模塊收集其周圍像素的上下文信息。通過進行進一步的複發操作,每個像素最終可以從所有像素中捕獲遠程依賴性。總體而言,我們的CCNET具有以下優點:
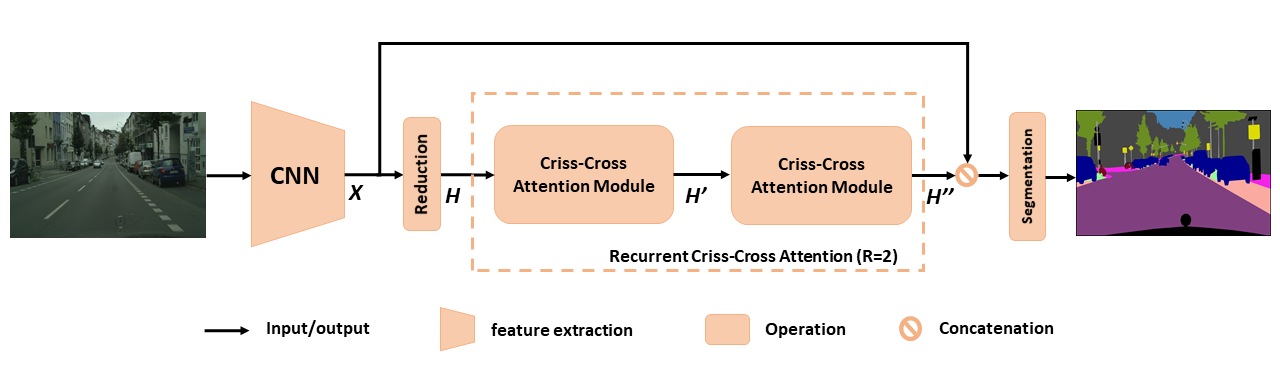 用於語義分割的擬議CCNET概述。提出的複發性縱橫交錯的注意力將輸入特徵映射h和輸出特徵映射h'' ,從所有像素中獲取豐富而密集的上下文信息。復發性縱橫交錯的注意模塊可以分為r = 2循環,其中所有縱橫交錯的注意模塊共享參數。
用於語義分割的擬議CCNET概述。提出的複發性縱橫交錯的注意力將輸入特徵映射h和輸出特徵映射h'' ,從所有像素中獲取豐富而密集的上下文信息。復發性縱橫交錯的注意模塊可以分為r = 2循環,其中所有縱橫交錯的注意模塊共享參數。
 為了更深入地了解我們的RCCA,我們可視化所學的注意力面具,如圖所示。對於每個輸入圖像,我們選擇一個點(綠十字),並分別在第2列和第3列中r = 2時顯示相應的注意圖。在圖中,僅來自目標點的縱橫道路徑的上下文信息才能在r = 1時捕獲。通過再採用一個縱橫交錯的模塊,即r = 2, RCCA最終可以匯總密度和更豐富的上下文信息與r = 1相比。此外,我們觀察到,注意模塊可以捕獲語義相似性和遠程依賴性。
為了更深入地了解我們的RCCA,我們可視化所學的注意力面具,如圖所示。對於每個輸入圖像,我們選擇一個點(綠十字),並分別在第2列和第3列中r = 2時顯示相應的注意圖。在圖中,僅來自目標點的縱橫道路徑的上下文信息才能在r = 1時捕獲。通過再採用一個縱橫交錯的模塊,即r = 2, RCCA最終可以匯總密度和更豐富的上下文信息與r = 1相比。此外,我們觀察到,注意模塊可以捕獲語義相似性和遠程依賴性。
CCNET根據MIT許可發布(有關詳細信息,請參閱許可證文件)。
如果您發現CCNET在研究中有用,請考慮引用:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } }要安裝Pytorch == 0.4.0或0.4.1,請參閱https://github.com/pytorch/pytorch/pytorch#installation。
4 x 12g GPU(例如泰坦XP)
Python 3.6
GCC(GCC)4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py installPLESAE下載CityScapes數據集並將數據集解壓縮到YOUR_CS_PATH中。
請下載MIT ImaTEnet預測的Resnet101-Imagenet.pth,然後將其放入dataset文件夾中。
培訓腳本。
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【建議您還可以打開OHEM標誌,以減少Val和測試集之間的性能差距。
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000評估腳本。
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2全部。
./run_local.sh YOUR_CS_PATH我們在CityScape數據集上分別在CCNET上運行r = 1,2的CCNET,並在下表中報告結果。請注意,驗證/測試集精度差距(1〜2%)存在一些問題。您需要多次運行才能達到一個小差距或打開OHEM標誌。打開OHEM標誌也可以改善閥門的性能。通常,我建議您在訓練步驟中使用OHEM。
我們在精細訓練集中訓練所有模型,並使用單秤進行測試。 r = 2 79.74的訓練有素的模型也可以在帶有單比例測試的城市景觀測試集上達到約79.01 miou(為了節省時間,我們將整個圖像用作輸入)。
| r | MIOU在城市景觀瓦特套件(單尺度) | 關聯 |
|---|---|---|
| 1 | 77.31& 77.91 &76.89 | 77.91 |
| 2 | 79.74 &79.22&78.40 | 79.74 |
| 2+OHEM | 78.67& 80.00 &79.83 | 80.00 |
我們感謝NSFC,ARC DECRA DE190101315,ARC DP200100938,HUST-HORIZON計算機視覺研究中心和IBM-Illinois認知計算機研究中心(C3SR)。
自我注意相關方法:
對像上下文網絡
雙重註意網絡
語義分割工具箱:
pytorch-seventation-toolbox
語義細分式 - 托爾奇
pytorch編碼


