CCNet
1.0.0
Liens papier: notre version TPAMI la plus récente avec des améliorations et des extensions ( version ICCV antérieure ).
Par Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Chang Huang, Humphrey Shi, Wenyu Liu et Thomas S. Huang.
2021/02: L'implémentation pure python de CCNET est publiée dans la branche Pure-Python. Merci Serge-Weihao.
2019/08: La nouvelle version CCNET est publiée sur Branch Pytorch-1.1 qui prend en charge Pytorch 1.0 ou version ultérieure et distribué la formation multiprocesseur et le test Ce code actuel est une implémentation des expériences sur les paysages urbains de la version CCNET ICCV. Nous implémentons notre méthode basée sur la boîte à outils Open Source Pytorch Segmentation.
2018/12: renouveler le code et libérer des modèles formés avec r = 1,2. Le modèle formé avec R = 2 atteint 79,74% sur le jeu de VAL et 79,01% sur les tests avec des tests à échelle unique.
2018/11: code publié.
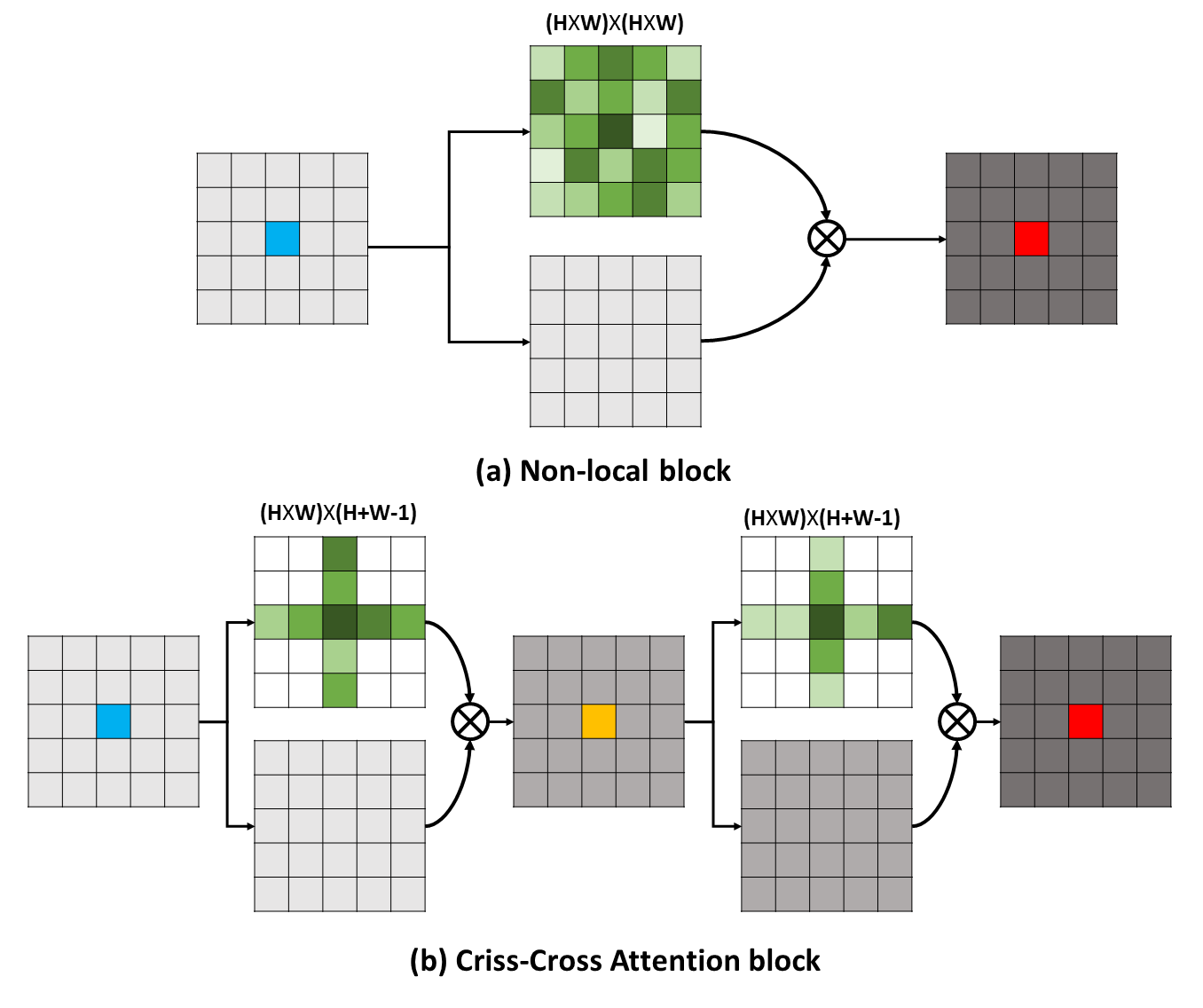 Les dépendances à longue portée peuvent capturer des informations contextuelles utiles au profit des problèmes de compréhension visuelle. Dans ce travail, nous proposons un réseau croisé (CCNET) pour obtenir des informations aussi importantes à travers une manière plus efficace et efficace. Concrètement, pour chaque pixel, notre CCNET peut récolter les informations contextuelles de ses pixels environnants sur la trajectoire entrecroisée à travers un nouveau module d'attention croisé. En prenant une nouvelle opération récurrente, chaque pixel peut enfin capturer les dépendances à longue portée de tous les pixels. Dans l'ensemble, notre CCNET est avec les mérites suivantes:
Les dépendances à longue portée peuvent capturer des informations contextuelles utiles au profit des problèmes de compréhension visuelle. Dans ce travail, nous proposons un réseau croisé (CCNET) pour obtenir des informations aussi importantes à travers une manière plus efficace et efficace. Concrètement, pour chaque pixel, notre CCNET peut récolter les informations contextuelles de ses pixels environnants sur la trajectoire entrecroisée à travers un nouveau module d'attention croisé. En prenant une nouvelle opération récurrente, chaque pixel peut enfin capturer les dépendances à longue portée de tous les pixels. Dans l'ensemble, notre CCNET est avec les mérites suivantes:
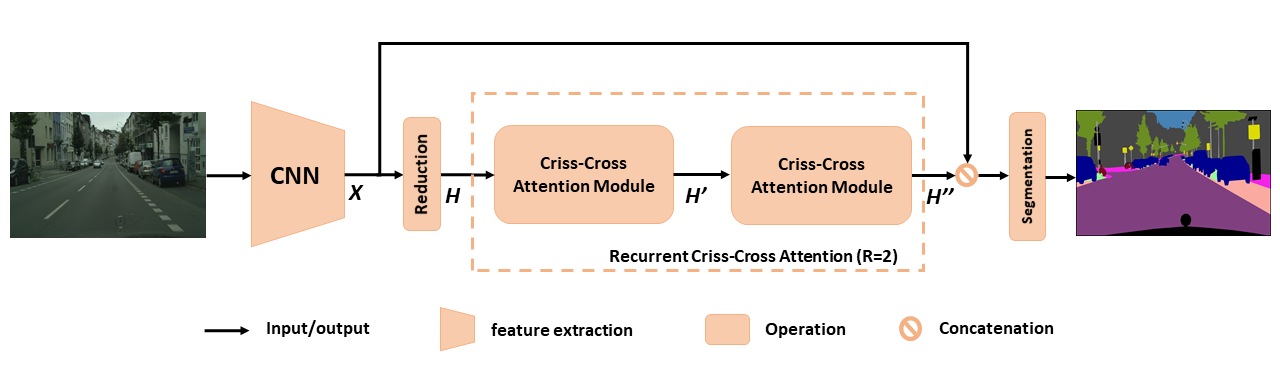 Aperçu du CCNET proposé pour la segmentation sémantique. L'attention récurrente de croits récurrente proposée prend en tant que cartes de fonctionnalités d'entrée h et cartes de fonctionnalités de sortie h '' qui obtiennent des informations contextuelles riches et denses de tous les pixels. Le module d'attention récurrent entre les craisses peut être déroulé en R = 2 boucles, dans lesquelles tous les modules d'attention entrecroisés partagent des paramètres.
Aperçu du CCNET proposé pour la segmentation sémantique. L'attention récurrente de croits récurrente proposée prend en tant que cartes de fonctionnalités d'entrée h et cartes de fonctionnalités de sortie h '' qui obtiennent des informations contextuelles riches et denses de tous les pixels. Le module d'attention récurrent entre les craisses peut être déroulé en R = 2 boucles, dans lesquelles tous les modules d'attention entrecroisés partagent des paramètres.
 Pour mieux comprendre notre RCCA, nous visualisons les masques d'attention appris comme indiqué sur la figure. Pour chaque image d'entrée, nous sélectionnons un point (croix verte) et montrons ses cartes d'attention correspondantes lorsque R = 1 et R = 2 dans les colonnes 2 et 3 respectivement. Sur la figure, seules les informations contextuelles du chemin CRISS-CROSS du point cible sont capturées lorsque R = 1 . En adoptant un autre module CRISS-CROSS, c'est-à-dire R = 2, le RCCA peut enfin agréger les informations contextuelles plus denses et plus riches par rapport à celle de R = 1 . En outre, nous observons que le module d'attention pourrait capturer la similitude sémantique et les dépendances à longue portée.
Pour mieux comprendre notre RCCA, nous visualisons les masques d'attention appris comme indiqué sur la figure. Pour chaque image d'entrée, nous sélectionnons un point (croix verte) et montrons ses cartes d'attention correspondantes lorsque R = 1 et R = 2 dans les colonnes 2 et 3 respectivement. Sur la figure, seules les informations contextuelles du chemin CRISS-CROSS du point cible sont capturées lorsque R = 1 . En adoptant un autre module CRISS-CROSS, c'est-à-dire R = 2, le RCCA peut enfin agréger les informations contextuelles plus denses et plus riches par rapport à celle de R = 1 . En outre, nous observons que le module d'attention pourrait capturer la similitude sémantique et les dépendances à longue portée.
CCNET est publié sous la licence MIT (reportez-vous au fichier de licence pour plus de détails).
Si vous trouvez CCNET utile dans vos recherches, veuillez envisager de citer:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } Pour installer pytorch == 0.4.0 ou 0.4.1, veuillez vous référer à https://github.com/pytorch/pytorch#installation.
4 gpus x 12g ( par exemple Titan XP)
Python 3.6
GCC (GCC) 4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install Plesae Téléchargez les paysages municipaux et déziptez l'ensemble de données dans YOUR_CS_PATH .
Veuillez télécharger le MIT ImageNet Resnet101- dataset .
Script de formation.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【 Recommander 】 Vous pouvez également ouvrir le drapeau Ohem pour réduire l'écart de performance entre VAL et l'ensemble de test.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000Script d'évaluation.
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2Tout en un.
./run_local.sh YOUR_CS_PATHNous exécutons CCNET avec R = 1,2 trois fois sur un ensemble de données CityScape séparément et rapportons les résultats dans le tableau suivant. Veuillez noter qu'il existe des problèmes concernant l'écart de précision de la validation / test de la validation (1 ~ 2%). Vous devez s'exécuter plusieurs fois pour atteindre un petit écart ou activer le drapeau ohem. L'activation du drapeau ohem peut également améliorer les performances de l'ensemble VAL. En général, je vous recommande d'utiliser Ohem en étape de formation.
Nous formons tous les modèles sur l'ensemble de formation fin et utilisons l'échelle unique pour les tests. Le modèle formé avec R = 2 79,74 peut également atteindre environ 79,01 miou sur un ensemble de tests de paysage urbain avec des tests à une seule échelle (pour gagner du temps, nous utilisons l'image entière comme entrée).
| R | miou sur le jeu de Val Cityscape (une seule échelle) | Lien |
|---|---|---|
| 1 | 77.31 et 77.91 et 76.89 | 77.91 |
| 2 | 79,74 et 79,22 et 78,40 | 79.74 |
| 2 + ohem | 78,67 et 80,00 et 79,83 | 80.00 |
Nous remercions NSFC, ARC DECRA DE190101315, ARC DP200100938, Hust-Horizon Computer Vision ResearchCenter et IBM-Illinois Center for Cognitive ComputingSystems Research (C3SR).
Méthodes liées à l'auto-attention:
Réseau de contexte d'objet
Réseau à double attention
Boîtes à outils de segmentation sémantique:
pytorch-segmentation-toolbox
segment-segmentation-pytorch
Codant pour le pytorch


