CCNet
1.0.0
Enlaces en papel: nuestra versión TPAMI más reciente con mejoras y extensiones ( versión ICCV anterior ).
Por Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Chang Huang, Humphrey Shi, Wenyu Liu y Thomas S. Huang.
2021/02: La implementación de Python Pure de CCNET se lanza en la rama Pure-Python. Gracias Serge-Weihao.
2019/08: La nueva versión CCNET se lanza en Branch Pytorch-1.1 que admite Pytorch 1.0 o posterior y distribuye el entrenamiento de multiprocesamiento y la prueba de este código actual es una implementación de los experimentos en paisajes urbanos en la versión CCNET ICCV. Implementamos nuestro método basado en la caja de herramientas de segmentación de Pytorch de código abierto.
2018/12: renovar el código y liberar modelos capacitados con r = 1,2. El modelo entrenado con R = 2 logra 79.74% en Val Set y 79.01% en el conjunto de pruebas con pruebas de escala única.
2018/11: Código publicado.
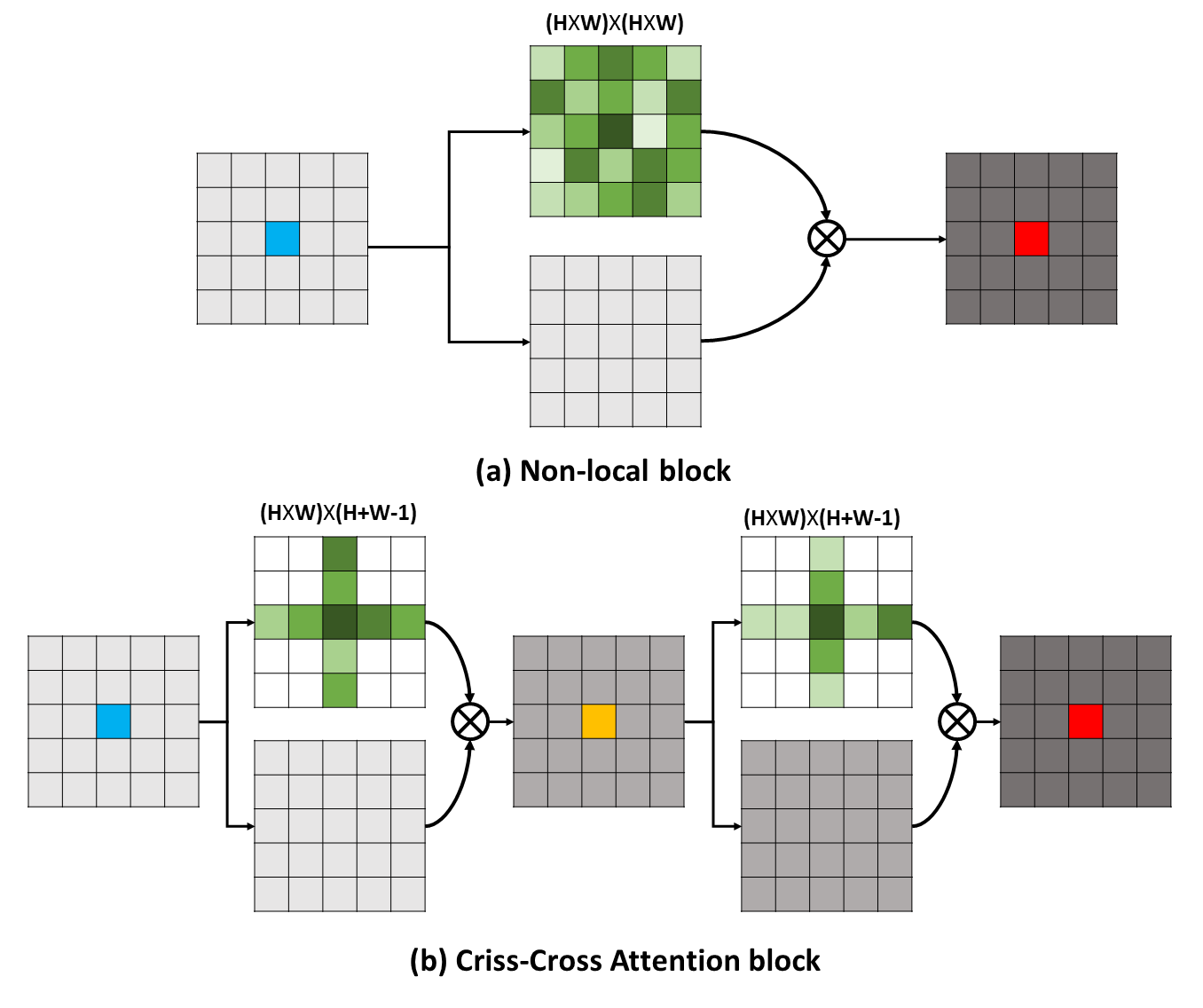 Las dependencias de largo alcance pueden capturar información contextual útil para beneficiar los problemas de comprensión visual. En este trabajo, proponemos una red entrecruzada (CCNET) para obtener información tan importante de una manera más efectiva y eficiente. Concretamente, para cada píxel, nuestro CCNET puede cosechar la información contextual de sus píxeles circundantes en el camino entrecruzado a través de un nuevo módulo de atención entrecruzada. Al tomar una operación recurrente adicional, cada píxel finalmente puede capturar las dependencias de largo alcance de todos los píxeles. En general, nuestro CCNET es con los siguientes méritos:
Las dependencias de largo alcance pueden capturar información contextual útil para beneficiar los problemas de comprensión visual. En este trabajo, proponemos una red entrecruzada (CCNET) para obtener información tan importante de una manera más efectiva y eficiente. Concretamente, para cada píxel, nuestro CCNET puede cosechar la información contextual de sus píxeles circundantes en el camino entrecruzado a través de un nuevo módulo de atención entrecruzada. Al tomar una operación recurrente adicional, cada píxel finalmente puede capturar las dependencias de largo alcance de todos los píxeles. En general, nuestro CCNET es con los siguientes méritos:
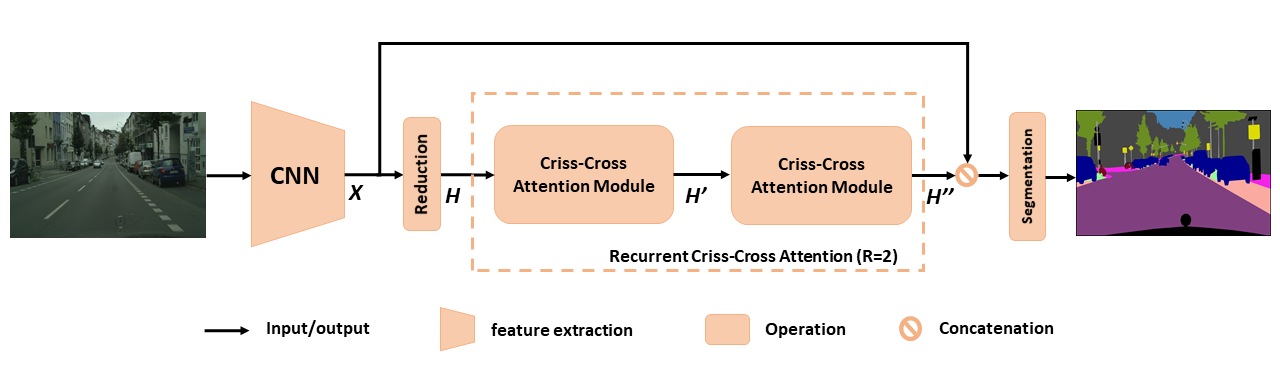 Descripción general del CCNET propuesto para la segmentación semántica. La atención recurrente de cruce recurrente se toma como mapas de características de entrada H y mapas de características de salida H '' que obtienen información contextual rica y densa de todos los píxeles. El módulo de atención recurrente de crujido se puede desenrollar en r = 2 bucles, en los cuales todos los módulos de atención entrecruzados comparten parámetros.
Descripción general del CCNET propuesto para la segmentación semántica. La atención recurrente de cruce recurrente se toma como mapas de características de entrada H y mapas de características de salida H '' que obtienen información contextual rica y densa de todos los píxeles. El módulo de atención recurrente de crujido se puede desenrollar en r = 2 bucles, en los cuales todos los módulos de atención entrecruzados comparten parámetros.
 Para obtener una comprensión más profunda de nuestro RCCA, visualizamos las máscaras de atención aprendidas como se muestra en la figura. Para cada imagen de entrada, seleccionamos un punto (cruz verde) y mostramos sus mapas de atención correspondientes cuando R = 1 y R = 2 en las columnas 2 y 3 respectivamente. En la figura, solo la información contextual de la ruta entrecruzada del punto objetivo es capturar cuando r = 1 . Al adoptar un módulo más cruzado, es decir, r = 2, el RCCA finalmente puede agregar información contextual más densa y más rica en comparación con la de R = 1 . Además, observamos que el módulo de atención podría capturar la similitud semántica y las dependencias de largo alcance.
Para obtener una comprensión más profunda de nuestro RCCA, visualizamos las máscaras de atención aprendidas como se muestra en la figura. Para cada imagen de entrada, seleccionamos un punto (cruz verde) y mostramos sus mapas de atención correspondientes cuando R = 1 y R = 2 en las columnas 2 y 3 respectivamente. En la figura, solo la información contextual de la ruta entrecruzada del punto objetivo es capturar cuando r = 1 . Al adoptar un módulo más cruzado, es decir, r = 2, el RCCA finalmente puede agregar información contextual más densa y más rica en comparación con la de R = 1 . Además, observamos que el módulo de atención podría capturar la similitud semántica y las dependencias de largo alcance.
CCNET se publica bajo la licencia MIT (consulte el archivo de licencia para obtener más detalles).
Si encuentra útil CCNET en su investigación, considere citar:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } Para instalar pytorch == 0.4.0 o 0.4.1, consulte https://github.com/pytorch/pytorch#installation.
4 x 12G GPU ( por ejemplo, Titan XP)
Python 3.6
GCC (GCC) 4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install Por favor, descargue el conjunto de datos Cityscapes y descompite el conjunto de datos en YOUR_CS_PATH .
Descargue el MIT ImageNet Pretrado Resnet101-iMagenet.pth, y póngalo en la carpeta dataset .
Script de entrenamiento.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【 Recomendar 】 También puede abrir la bandera de Ohem para reducir la brecha de rendimiento entre Val y el conjunto de pruebas.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000Script de evaluación.
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2Todo en uno.
./run_local.sh YOUR_CS_PATHEjecutamos CCNET con r = 1,2 tres veces en el conjunto de datos del paisaje urbano por separado e informamos los resultados en la siguiente tabla. Tenga en cuenta que existen algunos problemas sobre la brecha de precisión del conjunto de validación/prueba (1 ~ 2%). Debe ejecutar varias veces para lograr una pequeña brecha o encender la bandera de Ohem. Encender la bandera de Ohem también puede mejorar el rendimiento en el conjunto de valores. En general, le recomiendo que use Ohem en el paso de entrenamiento.
Entrenamos todos los modelos en un conjunto de entrenamiento fino y usamos la escala única para las pruebas. El modelo entrenado con R = 2 79.74 también puede lograr alrededor de 79.01 Miou en el conjunto de pruebas de paisaje urbano con pruebas de escala única (para ahorrar tiempo, usamos la imagen completa como entrada).
| Riñonal | Miu en Cityscape Val Set (escala única) | Enlace |
|---|---|---|
| 1 | 77.31 y 77.91 y 76.89 | 77.91 |
| 2 | 79.74 y 79.22 y 78.40 | 79.74 |
| 2+ohem | 78.67 y 80.00 y 79.83 | 80.00 |
Agradecemos a NSFC, ARC DECRA DE190101315, ARC DP200100938, Investigador de visión por computadora Hust-Horizon e IBM-Illinois Center para Investigación de sistemas de computadoras cognitivas (C3SR).
Métodos relacionados con la autoatición:
Red de contexto de objetos
Red de doble atención
Cajas de herramientas de segmentación semántica:
Pytorch-Segmation-Toolbox
segmentación semántica-pytorch
Codificación de pytorch


