CCNet
1.0.0
Бумажные ссылки: наша последняя версия TPAMI с улучшениями и расширениями ( более ранняя версия ICCV ).
Зилонг Хуанг, Синганг Ванг, Юнчао Вэй, Личао Хуанг, Чанг Хуанг, Хамфри Ши, Вениу Лю и Томас С. Хуанг.
2021/02: Реализация Pure Python CCNET выпускается в чистоте ветви. Спасибо, Серж-Вейхао.
2019/08: новая версия CCNET выпускается на Branch Pytorch-1.1, которая поддерживает Pytorch 1.0 или более поздней версии и распределенное многопроцессорное обучение и тестирование этого текущего кода представляет собой реализацию экспериментов на CityScapes в версии CCNET ICCV. Мы реализуем наш метод на основе инструментов для сегментации с открытым исходным кодом.
2018/12: Обновление обученных моделей кода и выпуска с R = 1,2. Обученная модель с R = 2 достигает 79,74% на SET VAL и 79,01% в испытательном наборе с одним масштабным тестированием.
2018/11: выпущен код.
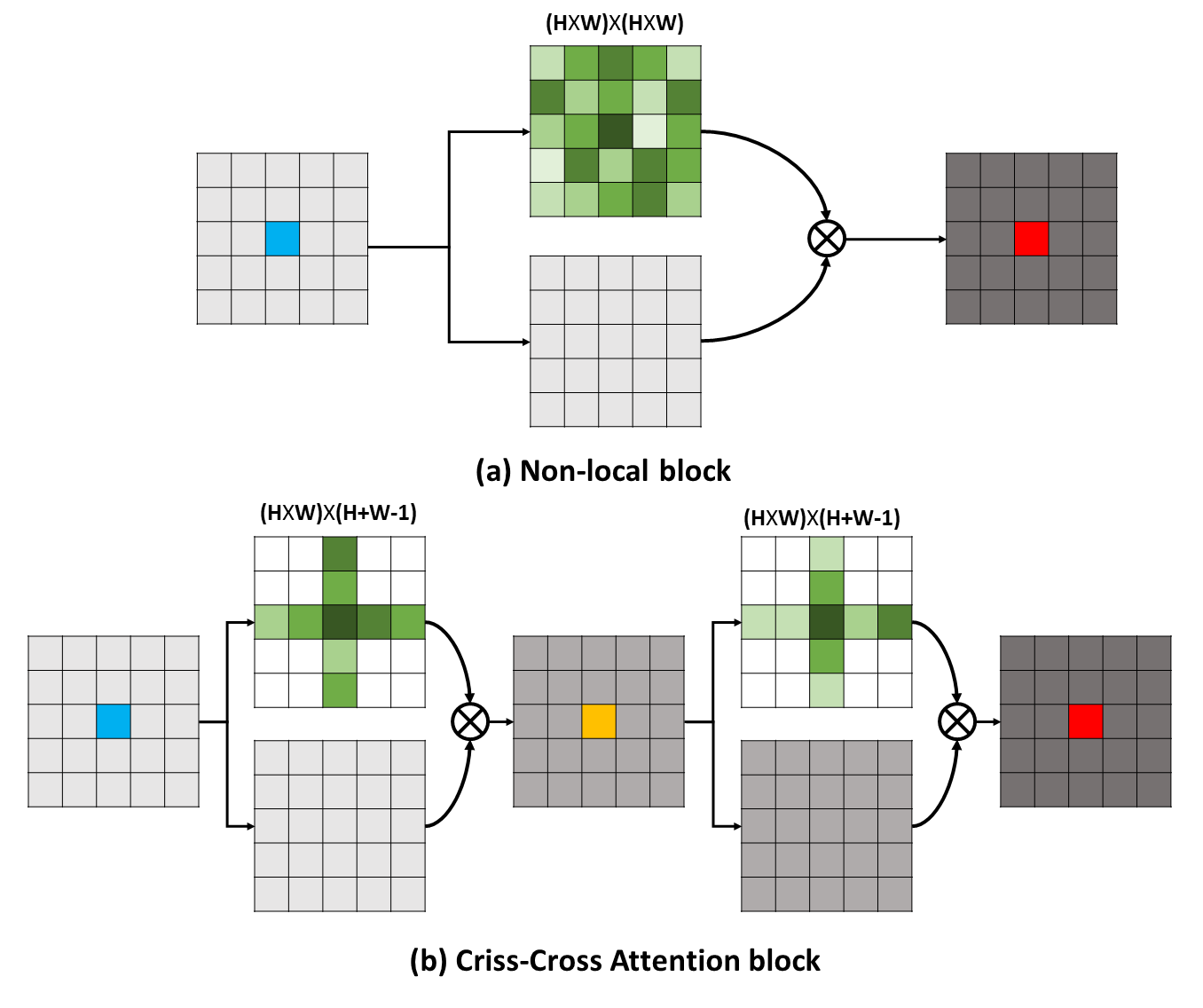 Долгосрочные зависимости могут отражать полезную контекстную информацию в пользу проблем визуального понимания. В этой работе мы предлагаем сеть Criss-Cross (CCNET) для получения такой важной информации с помощью более эффективного и эффективного способа. Конкретно, для каждого пикселя наш CCnet может собирать контекстную информацию о окружающих пикселях на пути Criss Cross через новый модуль внимания CRISS-Cross. Принимая дальнейшую рецидивирующую работу, каждый пиксель может, наконец, захватить долгосрочные зависимости от всех пикселей. В целом, наш CCNet со следующими достоинствами:
Долгосрочные зависимости могут отражать полезную контекстную информацию в пользу проблем визуального понимания. В этой работе мы предлагаем сеть Criss-Cross (CCNET) для получения такой важной информации с помощью более эффективного и эффективного способа. Конкретно, для каждого пикселя наш CCnet может собирать контекстную информацию о окружающих пикселях на пути Criss Cross через новый модуль внимания CRISS-Cross. Принимая дальнейшую рецидивирующую работу, каждый пиксель может, наконец, захватить долгосрочные зависимости от всех пикселей. В целом, наш CCNet со следующими достоинствами:
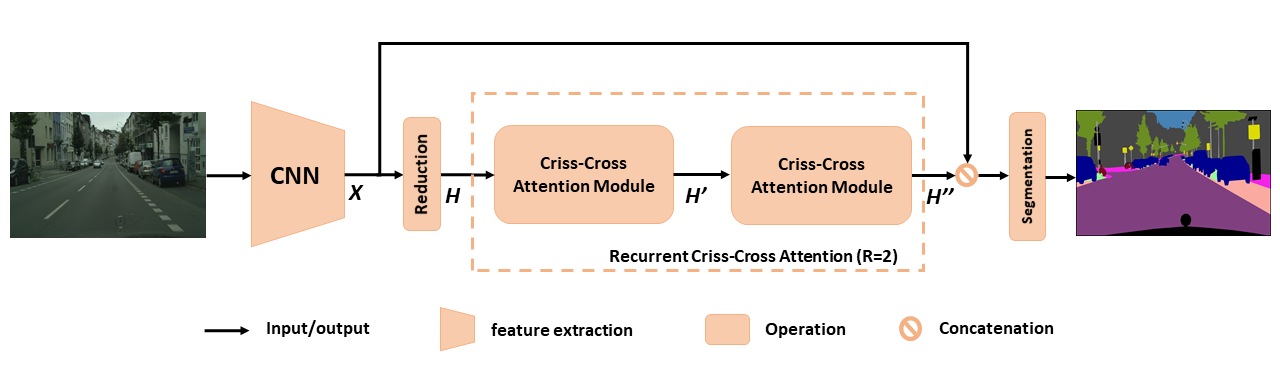 Обзор предложенного CCNET для семантической сегментации. Предлагаемое повторяющееся внимание CRISS-Cross принимает в качестве входных карт H и карты функций вывода H ', которые получают богатую и плотную контекстную информацию от всех пикселей. Рецидивирующий модуль внимания CRISS Cross может быть развернут в r = 2 петли, в которых все модули внимания CRISS-Cross совместно используют параметры.
Обзор предложенного CCNET для семантической сегментации. Предлагаемое повторяющееся внимание CRISS-Cross принимает в качестве входных карт H и карты функций вывода H ', которые получают богатую и плотную контекстную информацию от всех пикселей. Рецидивирующий модуль внимания CRISS Cross может быть развернут в r = 2 петли, в которых все модули внимания CRISS-Cross совместно используют параметры.
 Чтобы получить более глубокое понимание нашей RCCA, мы визуализируем ученые маски внимания, как показано на рисунке. Для каждого входного изображения мы выбираем одну точку (зеленый крест) и показываем его соответствующие карты внимания, когда r = 1 и r = 2 в столбцах 2 и 3 соответственно. На рисунке только контекстная информация из пути кроссовой точки, когда r = 1 . Приняв еще один модуль Criss Cross, то есть R = 2 , RCCA может, наконец, собирать более плотную и более богатую контекстную информацию по сравнению с информацией r = 1 . Кроме того, мы наблюдаем, что модуль внимания может отражать семантическое сходство и зависимости дальнего действия.
Чтобы получить более глубокое понимание нашей RCCA, мы визуализируем ученые маски внимания, как показано на рисунке. Для каждого входного изображения мы выбираем одну точку (зеленый крест) и показываем его соответствующие карты внимания, когда r = 1 и r = 2 в столбцах 2 и 3 соответственно. На рисунке только контекстная информация из пути кроссовой точки, когда r = 1 . Приняв еще один модуль Criss Cross, то есть R = 2 , RCCA может, наконец, собирать более плотную и более богатую контекстную информацию по сравнению с информацией r = 1 . Кроме того, мы наблюдаем, что модуль внимания может отражать семантическое сходство и зависимости дальнего действия.
CCNET выпускается по лицензии MIT (для получения подробной информации см. Файл лицензии).
Если вы найдете CCNet полезным в своем исследовании, пожалуйста, рассмотрите возможность цитирования:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } Чтобы установить Pytorch == 0,4,0 или 0,4,1, пожалуйста, см.
4 x 12g графические процессоры ( например, Titan XP)
Python 3.6
GCC (GCC) 4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install PLESAE Скачать набор данных CityScapes и разобщить набор данных в YOUR_CS_PATH .
Пожалуйста, загрузите MIT ImageNet Pretrended Resnet101-Imagenet.pth и поместите его в папку dataset .
Учебный сценарий.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【 Рекомендую 】 Вы также можете открыть флаг Ohem, чтобы уменьшить разрыв в производительности между Val и тестовым набором.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000Оценка сценария.
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2Все в одном.
./run_local.sh YOUR_CS_PATHМы запускаем CCNET с R = 1,2 три раза на наборе данных CityScape отдельно и сообщаем результаты в следующей таблице. Обратите внимание, что существуют некоторые проблемы в отношении разрыва точности набора проверки/тестирования (1 ~ 2%). Вам нужно запустить несколько раз, чтобы достичь небольшого зазора или включить флаг Охема. Включение флага в Ом также может улучшить производительность на наборе Val. В общем, я рекомендую вам использовать Ohem на шаге обучения.
Мы тренируем все модели на тонком обучении и используем единую шкалу для тестирования. Обученная модель с R = 2 79,74 также может достичь около 79,01 MIO на тестовом наборе CityScape с одноклассным тестированием (для времени сохранения мы используем все изображение в качестве входного материала).
| Ведущий | Miou on CityScape val set (одиночная масштаба) | Связь |
|---|---|---|
| 1 | 77,31 и 77,91 и 76,89 | 77,91 |
| 2 | 79,74 и 79,22 и 78,40 | 79,74 |
| 2+ohem | 78,67 и 80,00 и 79,83 | 80.00 |
Мы благодарим NSFC, Arc Decra DE190101315, ARC DP200100938, Hust-Horizon Computer Vision ResearchCenter и IBM-Illinois Center для исследования когнитивных вычислений (C3SR).
Методы, связанные с самого присмотра:
Объектная контекстная сеть
Сеть двойного внимания
Семантические наборы инструментов сегментации:
Pytorch-Segmation-Toolbox
Семантическая сегментация-питор
Пит-кодирование


