CCNet
1.0.0
Papierlinks: Unsere neueste TPAMI -Version mit Verbesserungen und Erweiterungen ( frühere ICCV -Version ).
Von Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Chang Huang, Humphrey Shi, Wenyu Liu und Thomas S. Huang.
2021/02: Die Python-Implementierung von CCNET wird im Zweig Pure-Python veröffentlicht. Danke Serge-Weihao.
2019/08: Die neue Version CCNET wird in Branch Pytorch-1.1 veröffentlicht, das Pytorch 1.0 oder später unterstützt und das Multiprozessing-Training und das Testen dieses aktuellen Codes eine Implementierung der Experimente mit Stadtcapes in der CCNET ICCV-Version ist. Wir implementieren unsere Methode basierend auf Open Source Pytorch -Segmentierungs -Toolbox.
2018/12: erneuern Sie den Code und veröffentlichen Sie geschulte Modelle mit R = 1,2. Das geschulte Modell mit R = 2 erreicht 79,74% am Val -Set und 79,01% beim Testsatz mit einzelnen Maßstäben.
2018/11: Code veröffentlicht.
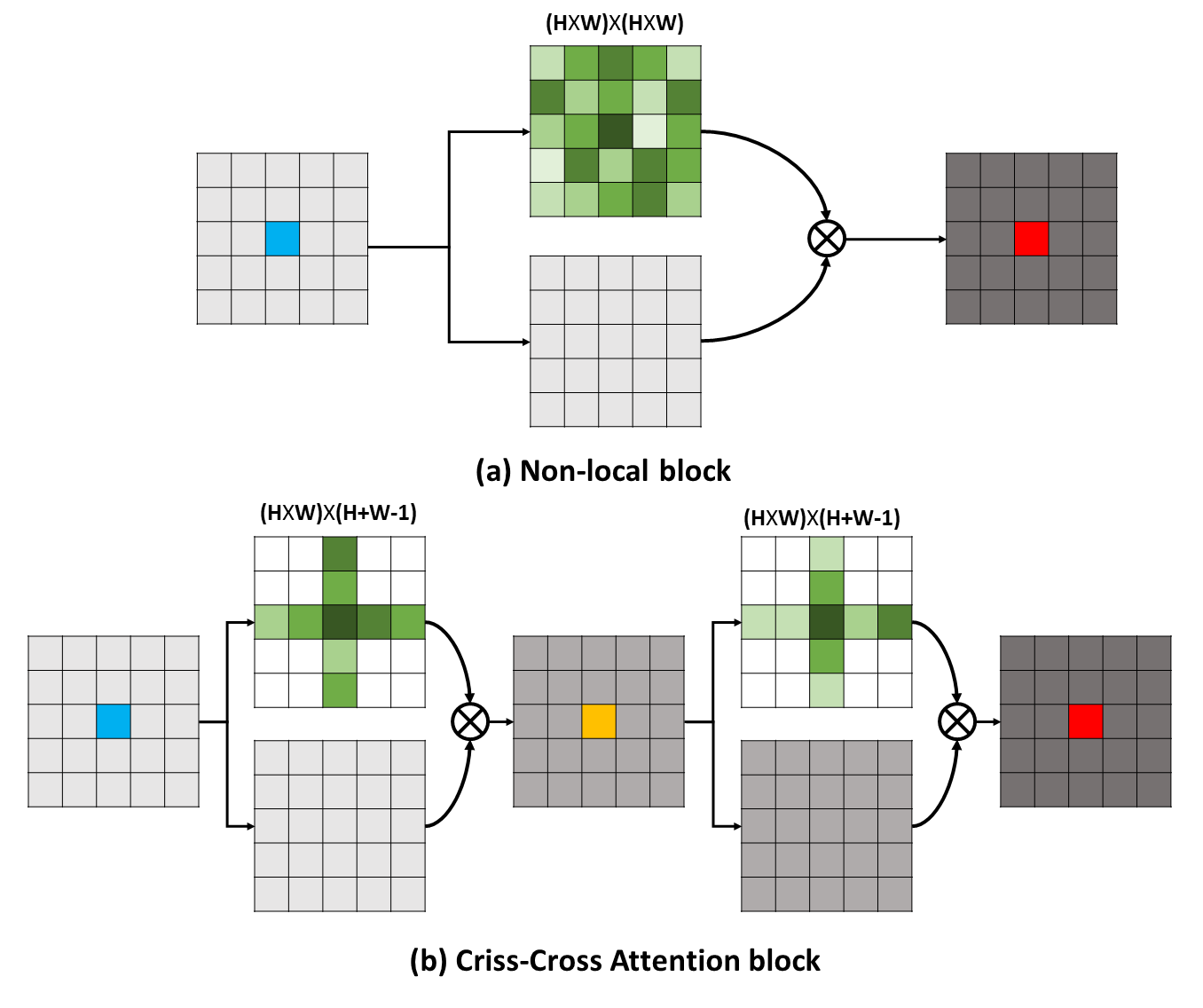 Langstreckenabhängigkeiten können nützliche kontextbezogene Informationen erfassen, um das visuelle Verständnisprobleme zugute. In dieser Arbeit schlagen wir ein Cross-Cross-Netzwerk (CCNET) vor, um solche wichtigen Informationen auf effektivere und effizientere Weise zu erhalten. Für jedes Pixel kann unser CCNET konkret die Kontextinformationen seiner umgebenden Pixel auf dem Kreuzspfad durch ein neuartiges Aufmerksamkeitsmodul auf dem kreuzenden Kreuz ernten. Durch den weiteren wiederkehrenden Betrieb kann jedes Pixel die Langstreckenabhängigkeiten von allen Pixeln schließlich erfassen. Insgesamt ist unser CCNET mit den folgenden Verdiensten:
Langstreckenabhängigkeiten können nützliche kontextbezogene Informationen erfassen, um das visuelle Verständnisprobleme zugute. In dieser Arbeit schlagen wir ein Cross-Cross-Netzwerk (CCNET) vor, um solche wichtigen Informationen auf effektivere und effizientere Weise zu erhalten. Für jedes Pixel kann unser CCNET konkret die Kontextinformationen seiner umgebenden Pixel auf dem Kreuzspfad durch ein neuartiges Aufmerksamkeitsmodul auf dem kreuzenden Kreuz ernten. Durch den weiteren wiederkehrenden Betrieb kann jedes Pixel die Langstreckenabhängigkeiten von allen Pixeln schließlich erfassen. Insgesamt ist unser CCNET mit den folgenden Verdiensten:
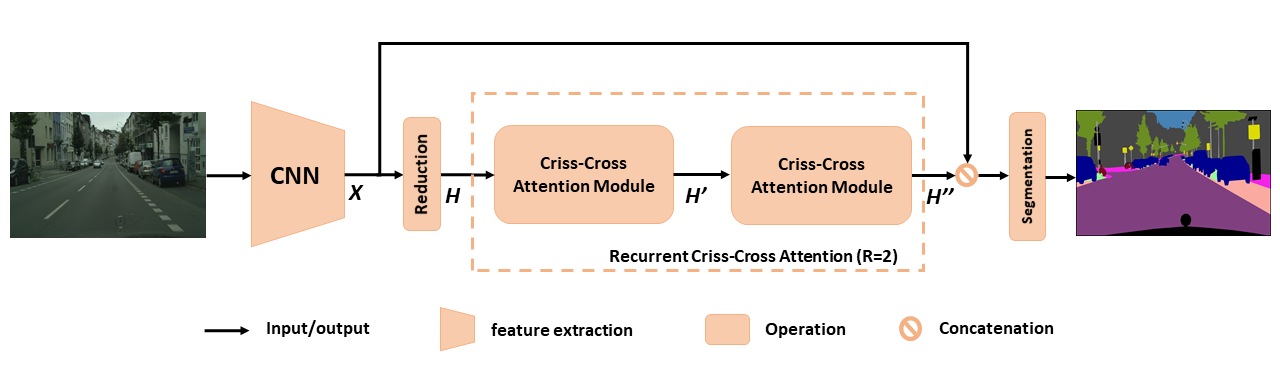 Überblick über das vorgeschlagene CCNET für die semantische Segmentierung. Die vorgeschlagene Aufmerksamkeit der wiederkehrenden Kreuzungskreuzungen nimmt als Eingangsfunktionskarten H und Ausgangsfunktion MAPS H '' auf, die reichhaltige und dichte kontextbezogene Informationen von allen Pixeln erhalten. Das rezidivierende Aufmerksamkeitsmodul für Kreuz-Kreuz-Cross kann in r = 2-Schleifen ausgearbeitet werden, bei denen alle Aufmerksamkeitsmodule für Kreuzungskreuzungen Parameter teilen.
Überblick über das vorgeschlagene CCNET für die semantische Segmentierung. Die vorgeschlagene Aufmerksamkeit der wiederkehrenden Kreuzungskreuzungen nimmt als Eingangsfunktionskarten H und Ausgangsfunktion MAPS H '' auf, die reichhaltige und dichte kontextbezogene Informationen von allen Pixeln erhalten. Das rezidivierende Aufmerksamkeitsmodul für Kreuz-Kreuz-Cross kann in r = 2-Schleifen ausgearbeitet werden, bei denen alle Aufmerksamkeitsmodule für Kreuzungskreuzungen Parameter teilen.
 Um ein tieferes Verständnis unserer RCCA zu erhalten, visualisieren wir die gelernten Aufmerksamkeitsmasken, wie in der Figur gezeigt. Für jedes Eingabebild wählen wir einen Punkt (grünes Kreuz) aus und zeigen seine entsprechenden Aufmerksamkeitskarten an, wenn r = 1 und r = 2 in den Spalten 2 bzw. 3. In der Abbildung wird nur kontextbezogene Informationen aus dem Kreuzspfad des Zielpunkts erfasst, wenn r = 1 . Durch die Einführung eines weiteren Kreuzungsmoduls, dh r = 2 Die RCCA kann schließlich dichtere und reichhaltigere Kontextinformationen im Vergleich zu r = 1 aggregieren. Außerdem stellen wir fest, dass das Aufmerksamkeitsmodul semantische Ähnlichkeit und Abhängigkeiten langfristig erfassen könnte.
Um ein tieferes Verständnis unserer RCCA zu erhalten, visualisieren wir die gelernten Aufmerksamkeitsmasken, wie in der Figur gezeigt. Für jedes Eingabebild wählen wir einen Punkt (grünes Kreuz) aus und zeigen seine entsprechenden Aufmerksamkeitskarten an, wenn r = 1 und r = 2 in den Spalten 2 bzw. 3. In der Abbildung wird nur kontextbezogene Informationen aus dem Kreuzspfad des Zielpunkts erfasst, wenn r = 1 . Durch die Einführung eines weiteren Kreuzungsmoduls, dh r = 2 Die RCCA kann schließlich dichtere und reichhaltigere Kontextinformationen im Vergleich zu r = 1 aggregieren. Außerdem stellen wir fest, dass das Aufmerksamkeitsmodul semantische Ähnlichkeit und Abhängigkeiten langfristig erfassen könnte.
CCNET wird unter der MIT -Lizenz veröffentlicht (Einzelheiten finden Sie in der Lizenzdatei).
Wenn Sie CCNET in Ihrer Forschung nützlich finden, sollten Sie sich angeben:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } So installieren Sie Pytorch == 0.4.0 oder 0.4.1, finden Sie unter https://github.com/pytorch/pytorch#installation.
4 x 12G GPUs ( z. B. Titan XP)
Python 3.6
GCC (GCC) 4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install Plesae laden Cityscapes -Datensatz herunter und entpacken Sie den Datensatz in YOUR_CS_PATH .
Bitte laden Sie MIT imageNet vor, die resnet101-iMagenet.PTH vorgebracht sind, und geben Sie es in dataset ein.
Trainingsskript.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【 Empfehlen Sie 】 Sie können das OHEM -Flag auch öffnen, um die Leistungslücke zwischen VAL und Testsatz zu verringern.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000Bewertungsskript.
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2Alles in einem.
./run_local.sh YOUR_CS_PATHWir führen CCNET mit r = 1,2 dreimal im CityScape -Datensatz separat aus und melden die Ergebnisse in der folgenden Tabelle. Bitte beachten Sie, dass es einige Probleme mit der Validierung/Test -Set -Genauigkeitslücke (1 ~ 2%) gibt. Sie müssen mehrmals laufen, um eine kleine Lücke zu erzielen oder die OHEM -Flagge einzuschalten. Das Einschalten von Ohem Flag kann auch die Leistung am Val -Set verbessern. Im Allgemeinen empfehle ich, Ohem im Trainingsschritt zu verwenden.
Wir trainieren alle Modelle im feinen Trainingssatz und verwenden die einzelnen Skala zum Testen. Das ausgebildete Modell mit r = 2 79,74 kann auch etwa 79,01 Miou auf dem Cityscape -Testsatz mit einzelnen Maßstäben erzielen (zur Sparenzeit verwenden wir das gesamte Bild als Eingabe).
| R | Miou auf Cityscape Val Set (Einzelstufe) | Link |
|---|---|---|
| 1 | 77.31 & 77.91 & 76.89 | 77,91 |
| 2 | 79.74 & 79.22 & 78,40 | 79,74 |
| 2+ohem | 78.67 & 80.00 & 79.83 | 80.00 |
Wir danken NSFC, ARC DecRA DE190101315, ARC DP200100938, Hust-Horizon Computer Vision ResearchCenter und IBM-Illinois Center for Cognitive Computingsingems Research (C3SR).
Selbsthergerichtete Methoden:
Objektkontextnetzwerk
Doppelaufmerksamkeitsnetzwerk
Semantische Segmentierungs -Toolboxs:
Pytorch-Segmentations-Toolbox
Semantische Segmentierungs-Pytorch
Pytorch-Coding


