CCNet
1.0.0
Links em papel: nossa versão mais recente do TPAMI com melhorias e extensões ( versão anterior do ICCV ).
Por Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Chang Huang, Humphrey Shi, Wenyu Liu e Thomas S. Huang.
2021/02: A implementação pura do Python do CCNET é lançada no ramo python puro. Obrigado Serge-Weihao.
2019/08: A nova versão CCNET é lançada no ramo Pytorch-1.1, que suporta o Pytorch 1.0 ou posterior e distribuiu treinamento e teste de multiprocessamento e teste Este código atual é uma implementação dos experimentos nas paisagens da cidade na versão CCNET ICCV. Implementamos nosso método baseado na caixa de ferramentas de segmentação de código aberto Pytorch.
2018/12: Renove o código e libere modelos treinados com r = 1,2. O modelo treinado com r = 2 alcança 79,74% no conjunto Val e 79,01% no conjunto de testes com testes em escala única.
2018/11: código lançado.
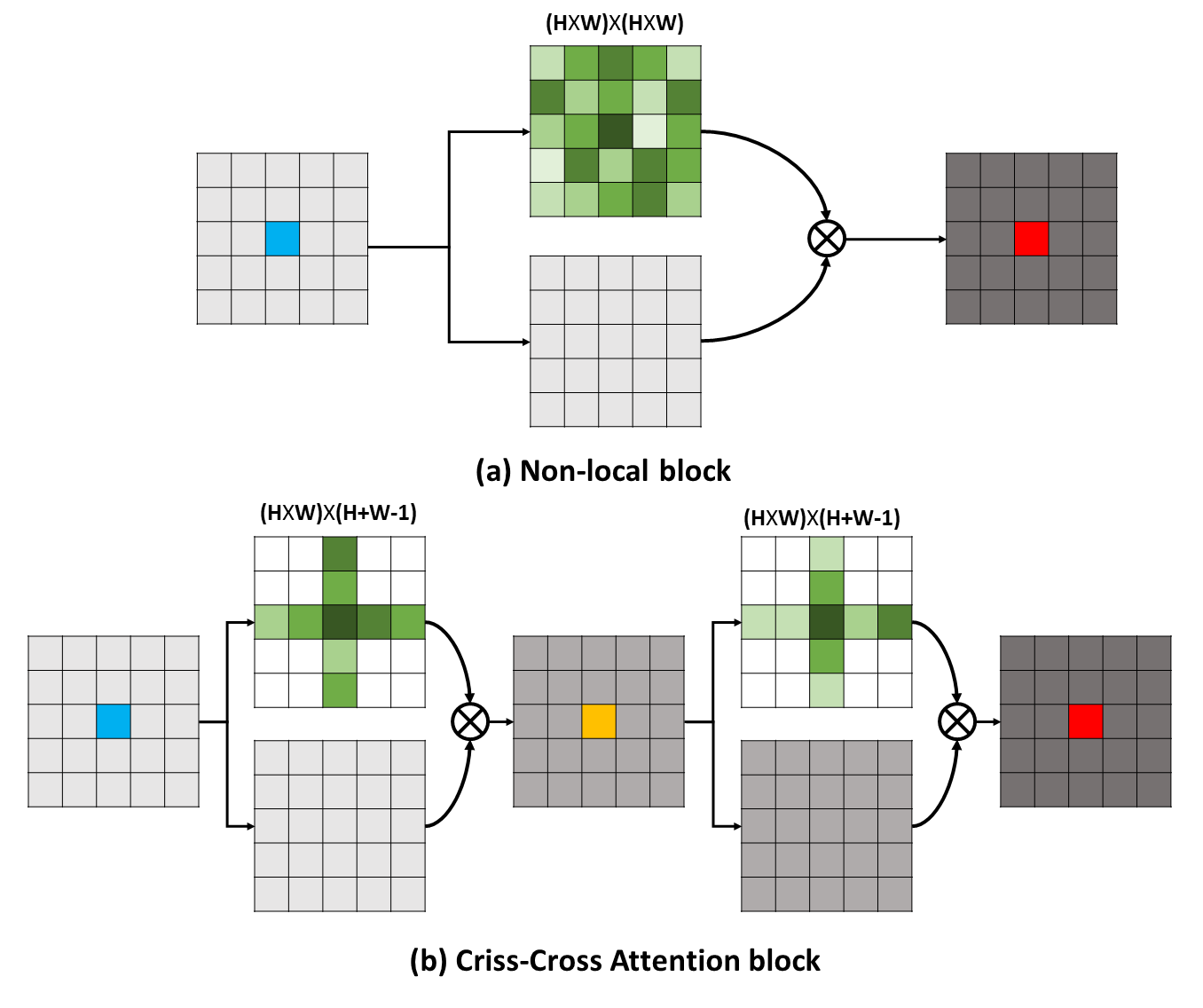 Dependências de longo alcance podem capturar informações contextuais úteis para beneficiar os problemas de entendimento visual. Neste trabalho, propomos uma rede cruzada (CCNET) para obter informações tão importantes de uma maneira mais eficaz e eficiente. Concretamente, para cada pixel, nosso CCNET pode colher as informações contextuais de seus pixels circundantes no caminho cruzado através de um novo módulo de atenção cruzado. Ao fazer uma operação recorrente adicional, cada pixel pode finalmente capturar as dependências de longo alcance de todos os pixels. No geral, nosso CCNET está com os seguintes méritos:
Dependências de longo alcance podem capturar informações contextuais úteis para beneficiar os problemas de entendimento visual. Neste trabalho, propomos uma rede cruzada (CCNET) para obter informações tão importantes de uma maneira mais eficaz e eficiente. Concretamente, para cada pixel, nosso CCNET pode colher as informações contextuais de seus pixels circundantes no caminho cruzado através de um novo módulo de atenção cruzado. Ao fazer uma operação recorrente adicional, cada pixel pode finalmente capturar as dependências de longo alcance de todos os pixels. No geral, nosso CCNET está com os seguintes méritos:
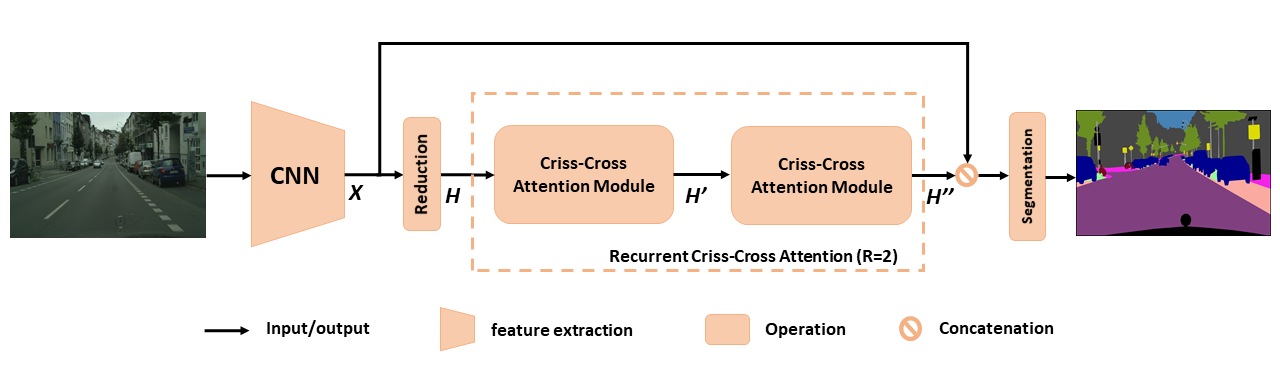 Visão geral do CCNET proposto para segmentação semântica. A atenção cruzada recorrente proposta leva como mapas de recurso de entrada H e mapas de saída de saída H '' que obtêm informações contextuais ricas e densas de todos os pixels. O módulo de atenção cruzado de cruzamento recorrente pode ser desenrolado em r = 2 loops, nos quais todos os módulos de atenção cruzados compartilham parâmetros.
Visão geral do CCNET proposto para segmentação semântica. A atenção cruzada recorrente proposta leva como mapas de recurso de entrada H e mapas de saída de saída H '' que obtêm informações contextuais ricas e densas de todos os pixels. O módulo de atenção cruzado de cruzamento recorrente pode ser desenrolado em r = 2 loops, nos quais todos os módulos de atenção cruzados compartilham parâmetros.
 Para obter uma compreensão mais profunda do nosso RCCA, visualizamos as máscaras de atenção aprendidas, como mostrado na figura. Para cada imagem de entrada, selecionamos um ponto (cruz verde) e mostramos seus mapas de atenção correspondentes quando r = 1 e r = 2 nas colunas 2 e 3, respectivamente. Na figura, apenas informações contextuais do caminho cruzado do ponto alvo são capturadas quando r = 1 . Ao adotar mais um módulo cruzado, ou seja, r = 2, o RCCA pode finalmente agregar informações mais densas e mais ricas em comparação com as de r = 1 . Além disso, observamos que o módulo de atenção poderia capturar similaridade semântica e dependências de longo alcance.
Para obter uma compreensão mais profunda do nosso RCCA, visualizamos as máscaras de atenção aprendidas, como mostrado na figura. Para cada imagem de entrada, selecionamos um ponto (cruz verde) e mostramos seus mapas de atenção correspondentes quando r = 1 e r = 2 nas colunas 2 e 3, respectivamente. Na figura, apenas informações contextuais do caminho cruzado do ponto alvo são capturadas quando r = 1 . Ao adotar mais um módulo cruzado, ou seja, r = 2, o RCCA pode finalmente agregar informações mais densas e mais ricas em comparação com as de r = 1 . Além disso, observamos que o módulo de atenção poderia capturar similaridade semântica e dependências de longo alcance.
O CCNET é liberado sob a licença do MIT (consulte o arquivo de licença para obter detalhes).
Se você achar o CCNET útil em sua pesquisa, considere citar:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } Para instalar pytorch == 0.4.0 ou 0.4.1, consulte https://github.com/pytorch/pytorch#installation.
4 x 12g GPUs ( por exemplo, Titan XP)
Python 3.6
GCC (GCC) 4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install PLESAE Download do DataSet da Cityscapes e descompacte o conjunto de dados em YOUR_CS_PATH .
Faça o download do MIT ImageNet pré-terenciado Resnet101-ImageNet.PTH e coloque-o na pasta dataset .
Script de treinamento.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【 Recomendar 】 Você também pode abrir o sinalizador Ohem para reduzir a diferença de desempenho entre Val e conjunto de testes.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000Script de avaliação.
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2Tudo em um.
./run_local.sh YOUR_CS_PATHExecutamos o CCNET com r = 1,2 três vezes no conjunto de dados da paisagem da cidade separadamente e relatamos os resultados na tabela a seguir. Observe que existem alguns problemas sobre a lacuna de precisão do conjunto de validação/teste (1 ~ 2%). Você precisa executar várias vezes para obter uma pequena lacuna ou ligar a bandeira Ohem. A bandeira de OHEM também pode melhorar o desempenho no conjunto Val. Em geral, eu recomendo que você use Ohem na etapa de treinamento.
Treinamos todos os modelos no conjunto de treinamento fino e usamos a escala única para teste. O modelo treinado com r = 2 79,74 também pode atingir cerca de 79,01 miou no conjunto de testes de paisagem urbana com testes em escala única (para economizar tempo, usamos toda a imagem como entrada).
| R | Miou no cityscape Val Set (escala única) | Link |
|---|---|---|
| 1 | 77.31 e 77.91 e 76.89 | 77.91 |
| 2 | 79,74 e 79.22 e 78.40 | 79.74 |
| 2+Ohem | 78,67 e 80,00 e 79,83 | 80,00 |
Agradecemos ao NSFC, ARC Decra de190101315, ARC DP200100938, Hust-Horizon Vision ResearchCenter e Centro IBM-Illinois para Pesquisa de Sistemas de Computação Cognitiva (C3SR).
Métodos relacionados à auto-atimento:
Rede de contexto de objeto
Rede de atenção dupla
Caixas de ferramentas de segmentação semântica:
Pytorch-Segmentation-Toolbox
Segmentação semântica-Pytorch
Codificação de pytorch


