CCNet
1.0.0
纸质链接:我们最新的TPAMI版本,具有改进和扩展(较早的ICCV版本)。
Zilong Huang,Xinggang Wang,Yunchao Wei,Lichao Huang,Chang Huang,Humphrey Shi,Wenyu Liu和Thomas S. Huang。
2021/02:CCNET的纯Python实现在分支纯Python中发布。感谢Serge-Weihao。
2019/08:新版本CCNET在Branch Pytorch-1.1上发布,该Branch Pytorch-1.1支持Pytorch 1.0或更高版本,并分布式多处理培训和测试此当前代码是对CCNET ICCV版本中CityScapes的实验的实现。我们基于开源Pytorch分段工具箱实现我们的方法。
2018/12:续订r = 1,2的代码和释放训练的模型。 R = 2的训练模型在Val设置上实现了79.74%,并在单尺测试的测试集上实现了79.01%。
2018/11:发布代码。
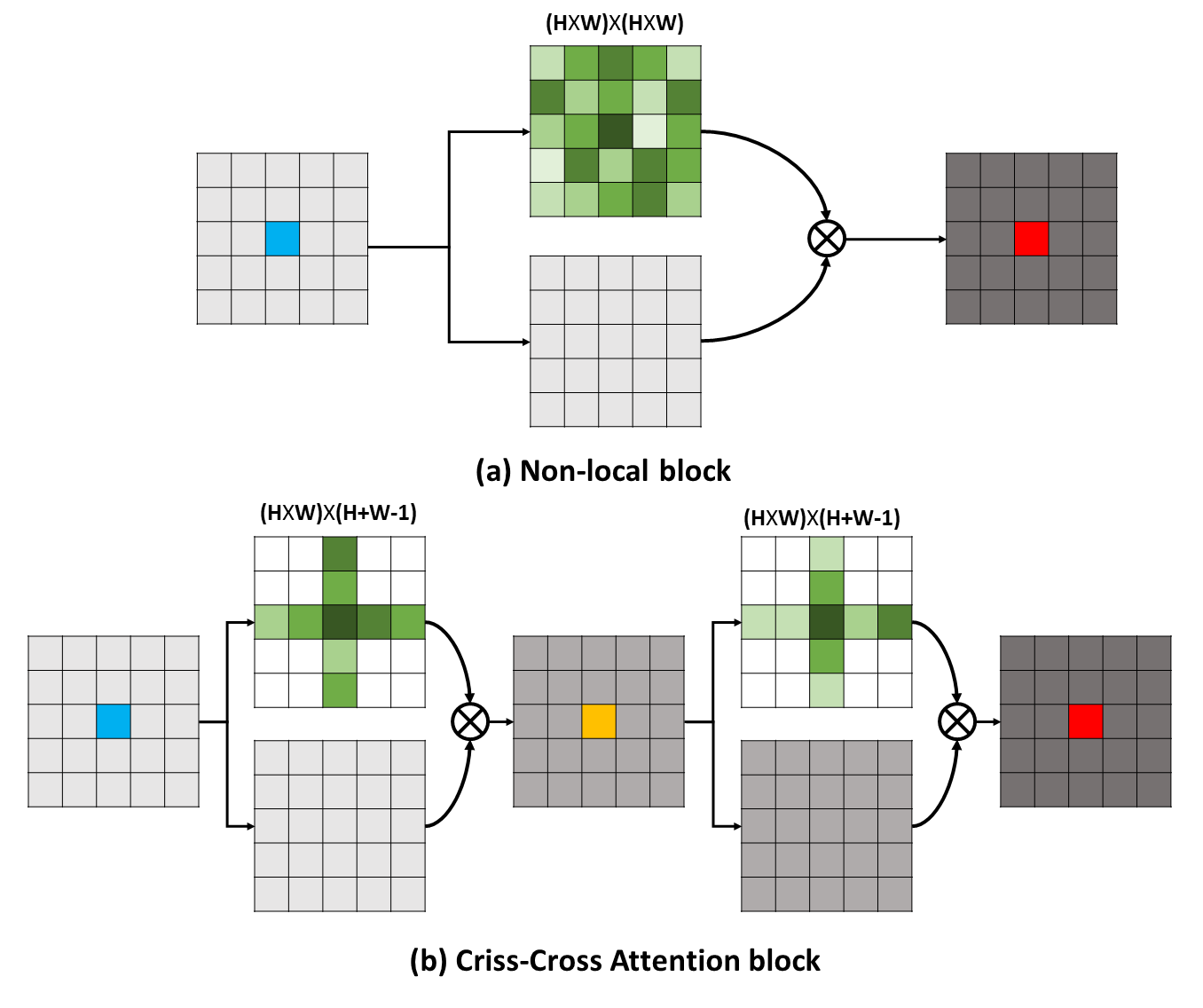 长期依赖性可以捕获有用的上下文信息,以使视觉理解问题受益。在这项工作中,我们提出了一个纵横交错的网络(CCNET),以通过更有效和有效的方式获得此类重要信息。具体而言,对于每个像素,我们的CCNet可以通过新型的纵横交错的注意模块收集其周围像素的上下文信息。通过进行进一步的复发操作,每个像素最终可以从所有像素中捕获远程依赖性。总体而言,我们的CCNET具有以下优点:
长期依赖性可以捕获有用的上下文信息,以使视觉理解问题受益。在这项工作中,我们提出了一个纵横交错的网络(CCNET),以通过更有效和有效的方式获得此类重要信息。具体而言,对于每个像素,我们的CCNet可以通过新型的纵横交错的注意模块收集其周围像素的上下文信息。通过进行进一步的复发操作,每个像素最终可以从所有像素中捕获远程依赖性。总体而言,我们的CCNET具有以下优点:
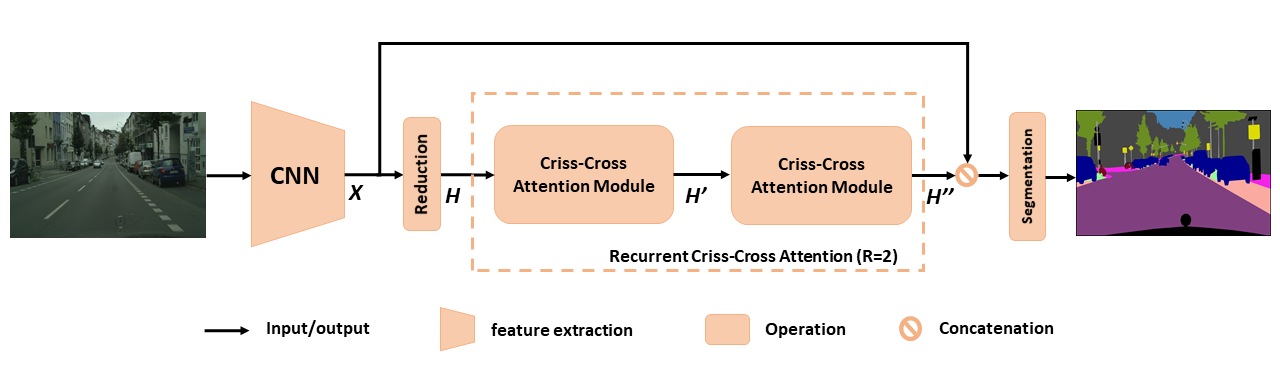 用于语义分割的拟议CCNET概述。提出的复发性纵横交错的注意力将输入特征映射h和输出特征映射h'' ,从所有像素中获取丰富而密集的上下文信息。复发性纵横交错的注意模块可以分为r = 2循环,其中所有纵横交错的注意模块共享参数。
用于语义分割的拟议CCNET概述。提出的复发性纵横交错的注意力将输入特征映射h和输出特征映射h'' ,从所有像素中获取丰富而密集的上下文信息。复发性纵横交错的注意模块可以分为r = 2循环,其中所有纵横交错的注意模块共享参数。
 为了更深入地了解我们的RCCA,我们可视化所学的注意力面具,如图所示。对于每个输入图像,我们选择一个点(绿十字),并分别在第2列和第3列中r = 2时显示相应的注意图。在图中,仅来自目标点的纵横道路径的上下文信息才能在r = 1时捕获。通过再采用一个纵横交错的模块,即r = 2, RCCA最终可以汇总密度和更丰富的上下文信息与r = 1相比。此外,我们观察到,注意模块可以捕获语义相似性和远程依赖性。
为了更深入地了解我们的RCCA,我们可视化所学的注意力面具,如图所示。对于每个输入图像,我们选择一个点(绿十字),并分别在第2列和第3列中r = 2时显示相应的注意图。在图中,仅来自目标点的纵横道路径的上下文信息才能在r = 1时捕获。通过再采用一个纵横交错的模块,即r = 2, RCCA最终可以汇总密度和更丰富的上下文信息与r = 1相比。此外,我们观察到,注意模块可以捕获语义相似性和远程依赖性。
CCNET根据MIT许可发布(有关详细信息,请参阅许可证文件)。
如果您发现CCNET在研究中有用,请考虑引用:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } }要安装Pytorch == 0.4.0或0.4.1,请参阅https://github.com/pytorch/pytorch/pytorch#installation。
4 x 12g GPU(例如泰坦XP)
Python 3.6
GCC(GCC)4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py installPLESAE下载CityScapes数据集并将数据集解压缩到YOUR_CS_PATH中。
请下载MIT ImaTEnet预测的Resnet101-Imagenet.pth,然后将其放入dataset文件夹中。
培训脚本。
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【建议您还可以打开OHEM标志,以减少Val和测试集之间的性能差距。
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000评估脚本。
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2全部。
./run_local.sh YOUR_CS_PATH我们在CityScape数据集上分别在CCNET上运行r = 1,2的CCNET,并在下表中报告结果。请注意,验证/测试集精度差距(1〜2%)存在一些问题。您需要多次运行才能达到一个小差距或打开OHEM标志。打开OHEM标志也可以改善阀门的性能。通常,我建议您在训练步骤中使用OHEM。
我们在精细训练集中训练所有模型,并使用单秤进行测试。 r = 2 79.74的训练有素的模型也可以在带有单比例测试的城市景观测试集上达到约79.01 miou(为了节省时间,我们将整个图像用作输入)。
| r | MIOU在城市景观瓦特套件(单尺度) | 关联 |
|---|---|---|
| 1 | 77.31& 77.91 &76.89 | 77.91 |
| 2 | 79.74 &79.22&78.40 | 79.74 |
| 2+OHEM | 78.67& 80.00 &79.83 | 80.00 |
我们感谢NSFC,ARC DECRA DE190101315,ARC DP200100938,HUST-HORIZON计算机视觉研究中心和IBM-Illinois认知计算机研究中心(C3SR)。
自我注意相关方法:
对象上下文网络
双重注意网络
语义分割工具箱:
pytorch-seventation-toolbox
语义细分式 - 托尔奇
pytorch编码


