CCNet
1.0.0
종이 링크 : 개선 및 확장 기능이있는 가장 최근의 TPAMI 버전 ( 이전 ICCV 버전 ).
Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Chang Huang, Humphrey Shi, Wenyu Liu 및 Thomas S. Huang.
2021/02 : CCNET의 순수한 Python 구현은 분기 Pure-Python에서 릴리스됩니다. Serge-Weihao에게 감사합니다.
2019/08 : 새 버전 CCNET는 Pytorch 1.0 이상을 지원하고 분산 다중 프로세싱 교육 및 테스트를 지원하는 Branch Pytorch-1.1에서 릴리스됩니다.이 현재 코드는 CCNET ICCV 버전의 도시 스케이프에서 실험을 구현 한 것입니다. 오픈 소스 Pytorch Segmentation Toolbox를 기반으로 방법을 구현합니다.
2018/12 : R = 1,2로 코드를 갱신하고 훈련 된 모델을 릴리스하십시오. R = 2 인 훈련 된 모델은 VAL 세트에서 79.74%, 단일 스케일 테스트로 테스트 세트에서 79.01%를 달성합니다.
2018/11 : 코드 릴리스.
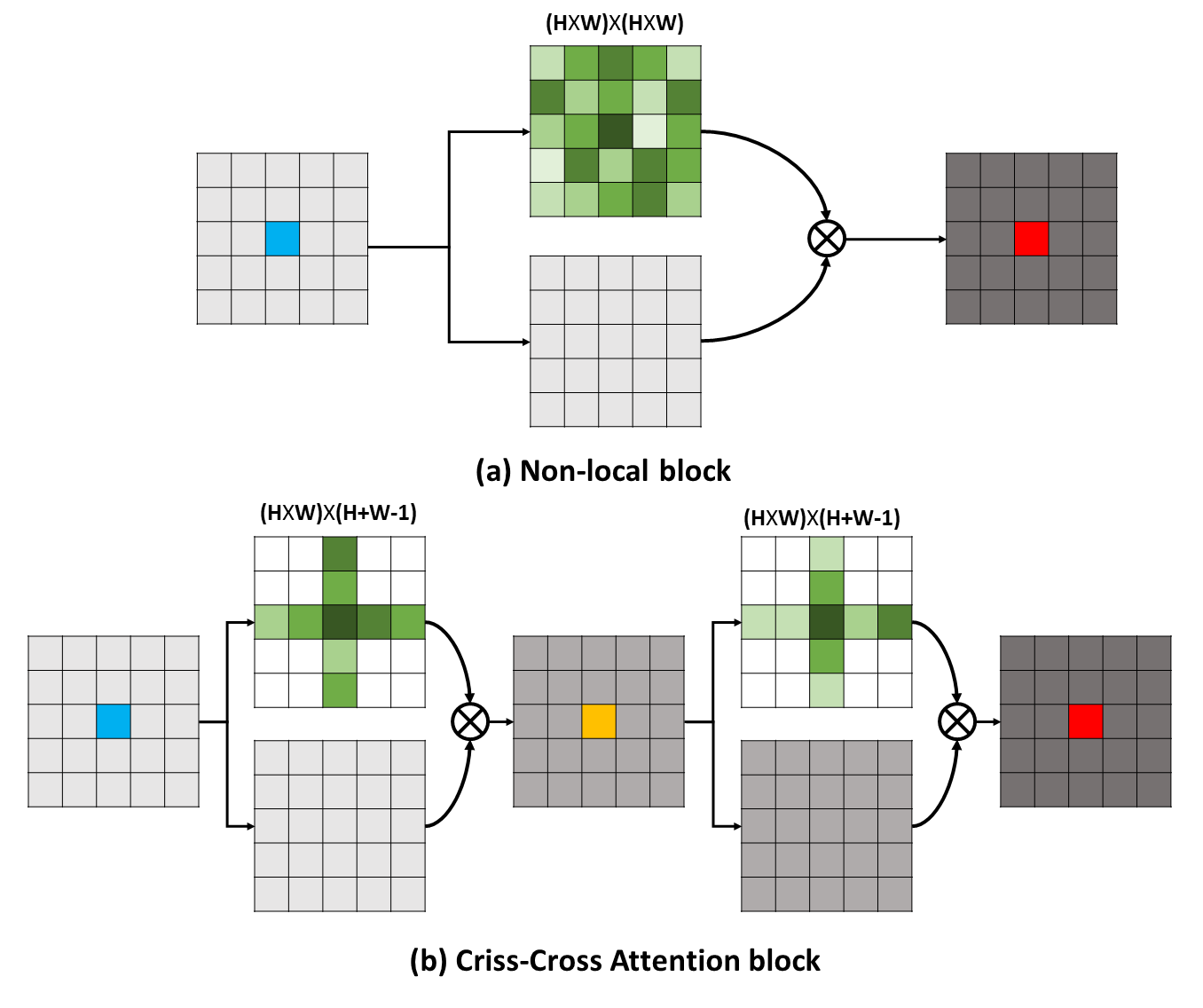 장거리 종속성은 시각적 이해 문제에 혜택을주기 위해 유용한 상황 정보를 캡처 할 수 있습니다. 이 작업에서는보다 효과적이고 효율적인 방법을 통해 이러한 중요한 정보를 얻기위한 CCNET (Criss-Cross Network)을 제안합니다. 구체적으로, 각 픽셀에 대해, 우리의 CCNET는 새로운 Criss-Cross주의 모듈을 통해 Criss-Cross 경로에서 주변 픽셀의 상황에 맞는 정보를 수확 할 수 있습니다. 추가 재발 작동을 통해 각 픽셀은 마침내 모든 픽셀에서 장거리 종속성을 캡처 할 수 있습니다. 전반적으로 CCNET은 다음과 같은 장점이 있습니다.
장거리 종속성은 시각적 이해 문제에 혜택을주기 위해 유용한 상황 정보를 캡처 할 수 있습니다. 이 작업에서는보다 효과적이고 효율적인 방법을 통해 이러한 중요한 정보를 얻기위한 CCNET (Criss-Cross Network)을 제안합니다. 구체적으로, 각 픽셀에 대해, 우리의 CCNET는 새로운 Criss-Cross주의 모듈을 통해 Criss-Cross 경로에서 주변 픽셀의 상황에 맞는 정보를 수확 할 수 있습니다. 추가 재발 작동을 통해 각 픽셀은 마침내 모든 픽셀에서 장거리 종속성을 캡처 할 수 있습니다. 전반적으로 CCNET은 다음과 같은 장점이 있습니다.
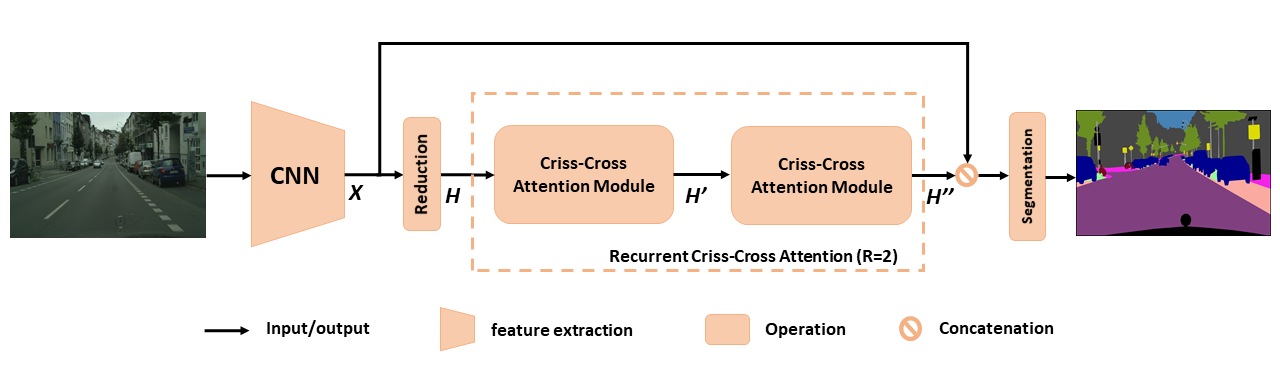 시맨틱 세분화를위한 제안 된 CCNET의 개요. 제안 된 재발 성 선조주의는 입력 기능 맵 H 및 출력 기능 맵 h '' 로 모든 픽셀에서 풍부하고 조밀 한 상황 정보를 얻습니다. 재발 성 세기-교차주의 모듈은 r = 2 루프로 풀릴 수 있으며, 여기서 모든 Criss-Cross주의 모듈은 매개 변수를 공유합니다.
시맨틱 세분화를위한 제안 된 CCNET의 개요. 제안 된 재발 성 선조주의는 입력 기능 맵 H 및 출력 기능 맵 h '' 로 모든 픽셀에서 풍부하고 조밀 한 상황 정보를 얻습니다. 재발 성 세기-교차주의 모듈은 r = 2 루프로 풀릴 수 있으며, 여기서 모든 Criss-Cross주의 모듈은 매개 변수를 공유합니다.
 RCCA에 대한 더 깊은 이해를 얻으려면 그림과 같이 학습 된주의 마스크를 시각화합니다. 각 입력 이미지에 대해, 우리는 열 2와 3에서 각각 r = 1 및 r = 2 일 때 1 점 (녹색 크로스)을 선택하고 해당주의 맵을 표시합니다. 그림에서, 대상 지점의 Criss-cross 경로의 문맥 정보 만 r = 1 일 때 캡처됩니다. 하나 이상의 Criss-cross 모듈을 채택함으로써, r = 2 RCCA는 r = 1 의 것과 비교하여 밀도가 풍부하고 더 풍부한 맥락 정보를 집계 할 수 있습니다. 또한주의 모듈이 의미 론적 유사성과 장거리 종속성을 포착 할 수 있음을 관찰합니다.
RCCA에 대한 더 깊은 이해를 얻으려면 그림과 같이 학습 된주의 마스크를 시각화합니다. 각 입력 이미지에 대해, 우리는 열 2와 3에서 각각 r = 1 및 r = 2 일 때 1 점 (녹색 크로스)을 선택하고 해당주의 맵을 표시합니다. 그림에서, 대상 지점의 Criss-cross 경로의 문맥 정보 만 r = 1 일 때 캡처됩니다. 하나 이상의 Criss-cross 모듈을 채택함으로써, r = 2 RCCA는 r = 1 의 것과 비교하여 밀도가 풍부하고 더 풍부한 맥락 정보를 집계 할 수 있습니다. 또한주의 모듈이 의미 론적 유사성과 장거리 종속성을 포착 할 수 있음을 관찰합니다.
CCNET은 MIT 라이센스에 따라 릴리스됩니다 (자세한 내용은 라이센스 파일 참조).
연구에 CCNET이 유용하다고 생각되면 다음을 고려하십시오.
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } pytorch == 0.4.0 또는 0.4.1을 설치하려면 https://github.com/pytorch/pytorch#installation을 참조하십시오.
4 x 12g GPU ( 예 : 타이탄 XP)
파이썬 3.6
GCC (GCC) 4.8.5
CUDA 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install Plesae는 CityScapes 데이터 세트를 다운로드하고 데이터 세트를 YOUR_CS_PATH 로 연결합니다.
MIT ImageNet 사전 RESNET101-Imagenet.pth를 다운로드하여 dataset 폴더에 넣으십시오.
훈련 스크립트.
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【val과 테스트 세트 사이의 성능 간격을 줄이기 위해 OM 플래그를 열 수 있습니다 .
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000평가 스크립트.
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2모두 하나.
./run_local.sh YOUR_CS_PATHCityScape 데이터 세트에서 R = 1,2 로 CCNET을 실행하고 다음 표에 결과를보고합니다. 검증/테스트 세트 정확도 간격 (1 ~ 2%)에 대한 몇 가지 문제가 있습니다. 작은 간격을 달성하거나 OM 깃발을 켜려면 여러 번 실행해야합니다. OM 깃발을 켜면 VAL 세트의 성능이 향상 될 수 있습니다. 일반적으로 훈련 단계에서 OHEM을 사용하는 것이 좋습니다.
우리는 모든 모델을 미세 훈련 세트에서 훈련시키고 단일 스케일을 사용하여 테스트합니다. r = 2 79.74 의 훈련 된 모델은 단일 스케일 테스트를 통해 Cityscape 테스트 세트 에서 약 79.01 MIOU를 달성 할 수 있습니다 (시간을 절약하기 위해 전체 이미지를 입력으로 사용).
| 아르 자형 | Cityscape val 세트의 Miou (단일 스케일) | 링크 |
|---|---|---|
| 1 | 77.31 & 77.91 & 76.89 | 77.91 |
| 2 | 79.74 & 79.22 & 78.40 | 79.74 |
| 2+om | 78.67 & 80.00 & 79.83 | 80.00 |
NSFC, ARC DECRA DE190101315, ARC DP200100938, HUST-HORIZON Computer Vision ResearchCenter 및 IBM-Illinois Cognitive Computingsystems Research (C3SR)에 감사드립니다.
자체 변환 관련 방법 :
객체 컨텍스트 네트워크
이중주의 네트워크
시맨틱 세분화 도구 상자 :
Pytorch-sementation-toolbox
시맨틱 세분화 파이터
Pytorch-Encoding


