CCNet
1.0.0
ลิงก์กระดาษ: เวอร์ชัน TPAMI ล่าสุดของเราพร้อมการปรับปรุงและส่วนขยาย ( เวอร์ชัน ICCV ก่อนหน้า )
โดย Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Chang Huang, Humphrey Shi, Wenyu Liu และ Thomas S. Huang
2021/02: การใช้ Python บริสุทธิ์ของ CCNET ถูกปล่อยออกมาในสาขา Pure-Python ขอบคุณ Serge-Weihao
2019/08: CCNET เวอร์ชันใหม่เปิดตัวในสาขา pytorch -1.1 ซึ่งรองรับ Pytorch 1.0 หรือใหม่กว่าและแจกจ่ายการฝึกอบรมการประมวลผลหลายครั้งและการทดสอบรหัสปัจจุบันนี้เป็นการดำเนินการทดลองบนทิวทัศน์ของเมืองในรุ่น CCNET ICCV เราใช้วิธีการของเราตามกล่องเครื่องมือการแบ่งส่วน Pytorch โอเพนซอร์ส
2018/12: ต่ออายุรหัสและปล่อยโมเดลที่ได้รับการฝึกอบรมด้วย r = 1,2 รูปแบบที่ผ่านการฝึกอบรมด้วย R = 2 ประสบความสำเร็จ 79.74% สำหรับชุด VAL และ 79.01% สำหรับชุดทดสอบด้วยการทดสอบสเกลเดี่ยว
2018/11: รหัสที่ปล่อยออกมา
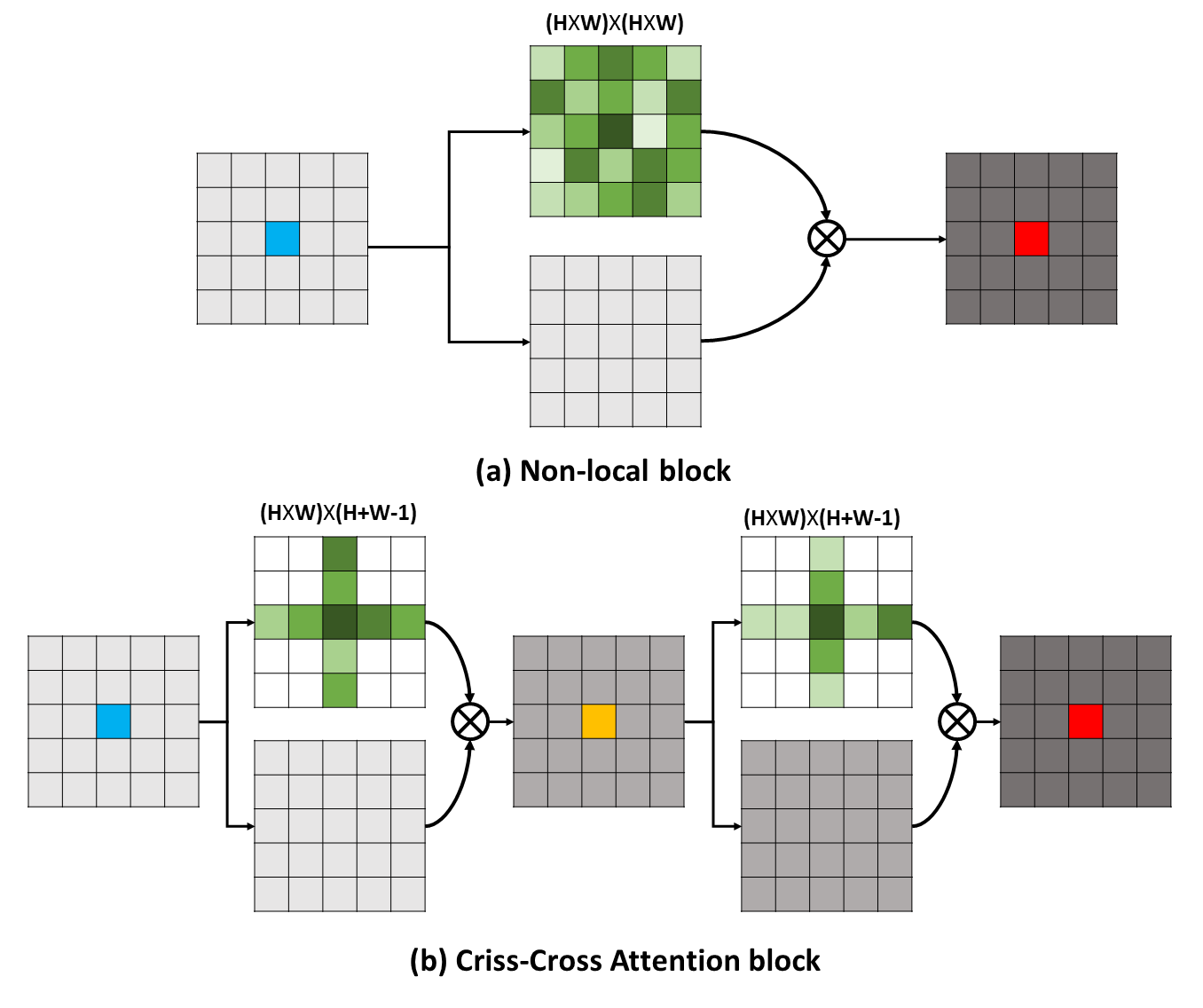 การพึ่งพาระยะยาวสามารถจับข้อมูลบริบทที่เป็นประโยชน์เพื่อประโยชน์ต่อปัญหาการทำความเข้าใจภาพ ในงานนี้เราเสนอเครือข่าย Criss-Cross (CCNET) เพื่อรับข้อมูลที่สำคัญเช่นนี้ผ่านวิธีที่มีประสิทธิภาพและมีประสิทธิภาพมากขึ้น สำหรับแต่ละพิกเซล CCNET ของเราสามารถเก็บเกี่ยวข้อมูลตามบริบทของพิกเซลโดยรอบบนเส้นทางครอสครอสผ่านโมดูลความสนใจครอสครอสครอสใหม่ ด้วยการดำเนินการที่เกิดขึ้นอีกครั้งในที่สุดพิกเซลแต่ละตัวสามารถจับการพึ่งพาระยะยาวจากพิกเซลทั้งหมด โดยรวมแล้ว CCNET ของเราอยู่กับข้อดีต่อไปนี้:
การพึ่งพาระยะยาวสามารถจับข้อมูลบริบทที่เป็นประโยชน์เพื่อประโยชน์ต่อปัญหาการทำความเข้าใจภาพ ในงานนี้เราเสนอเครือข่าย Criss-Cross (CCNET) เพื่อรับข้อมูลที่สำคัญเช่นนี้ผ่านวิธีที่มีประสิทธิภาพและมีประสิทธิภาพมากขึ้น สำหรับแต่ละพิกเซล CCNET ของเราสามารถเก็บเกี่ยวข้อมูลตามบริบทของพิกเซลโดยรอบบนเส้นทางครอสครอสผ่านโมดูลความสนใจครอสครอสครอสใหม่ ด้วยการดำเนินการที่เกิดขึ้นอีกครั้งในที่สุดพิกเซลแต่ละตัวสามารถจับการพึ่งพาระยะยาวจากพิกเซลทั้งหมด โดยรวมแล้ว CCNET ของเราอยู่กับข้อดีต่อไปนี้:
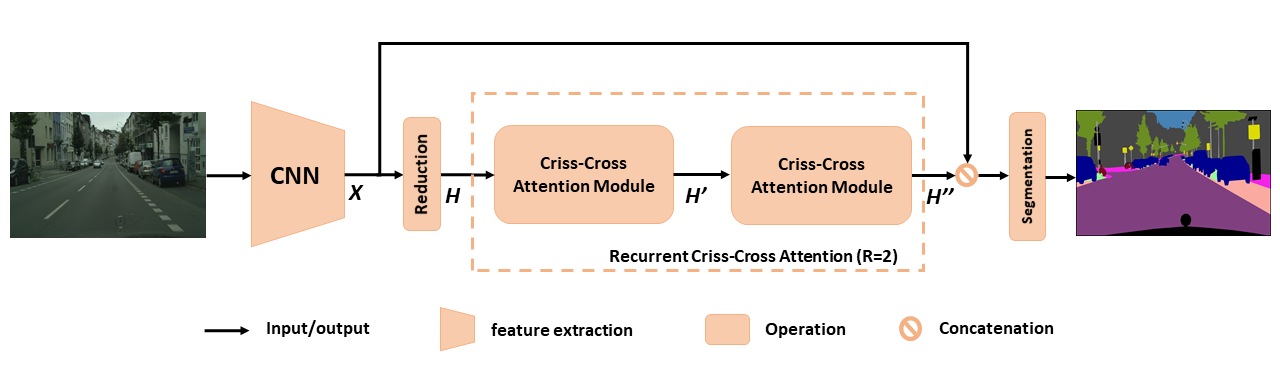 ภาพรวมของ CCNET ที่เสนอสำหรับการแบ่งส่วนความหมาย ความสนใจที่เกิดขึ้นซ้ำ ๆ กากบาทที่เสนอนั้นใช้เป็นแผนที่คุณลักษณะอินพุต H และคุณลักษณะเอาต์พุตแผนที่ H '' ซึ่งได้รับข้อมูลบริบทที่หลากหลายและหนาแน่นจากพิกเซลทั้งหมด โมดูลความสนใจกากบาทที่เกิดขึ้นซ้ำ ๆ สามารถคลี่ออกไปเป็นลูป r = 2 ซึ่งโมดูลความสนใจข้ามครอสทั้งหมดแบ่งปันพารามิเตอร์
ภาพรวมของ CCNET ที่เสนอสำหรับการแบ่งส่วนความหมาย ความสนใจที่เกิดขึ้นซ้ำ ๆ กากบาทที่เสนอนั้นใช้เป็นแผนที่คุณลักษณะอินพุต H และคุณลักษณะเอาต์พุตแผนที่ H '' ซึ่งได้รับข้อมูลบริบทที่หลากหลายและหนาแน่นจากพิกเซลทั้งหมด โมดูลความสนใจกากบาทที่เกิดขึ้นซ้ำ ๆ สามารถคลี่ออกไปเป็นลูป r = 2 ซึ่งโมดูลความสนใจข้ามครอสทั้งหมดแบ่งปันพารามิเตอร์
 เพื่อให้ได้ความเข้าใจที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับ RCCA ของเราเราเห็นภาพหน้ากากความสนใจที่เรียนรู้ดังแสดงในรูป สำหรับแต่ละภาพอินพุตเราเลือกจุดหนึ่ง (สีเขียวข้าม) และแสดงแผนที่ความสนใจที่สอดคล้องกันเมื่อ r = 1 และ r = 2 ในคอลัมน์ 2 และ 3 ตามลำดับ ในรูปเฉพาะข้อมูลบริบทจากเส้นทางกากบาทของจุดเป้าหมายคือการจับเมื่อ r = 1 ด้วยการใช้โมดูลกากบาทอีกหนึ่งโมดูลคือ R = 2 ในที่สุด RCCA สามารถรวมข้อมูลบริบทที่หนาแน่นและสมบูรณ์ยิ่งขึ้นเมื่อเทียบกับของ R = 1 นอกจากนี้เราสังเกตว่าโมดูลความสนใจสามารถจับความคล้ายคลึงกันทางความหมายและการพึ่งพาระยะยาว
เพื่อให้ได้ความเข้าใจที่ลึกซึ้งยิ่งขึ้นเกี่ยวกับ RCCA ของเราเราเห็นภาพหน้ากากความสนใจที่เรียนรู้ดังแสดงในรูป สำหรับแต่ละภาพอินพุตเราเลือกจุดหนึ่ง (สีเขียวข้าม) และแสดงแผนที่ความสนใจที่สอดคล้องกันเมื่อ r = 1 และ r = 2 ในคอลัมน์ 2 และ 3 ตามลำดับ ในรูปเฉพาะข้อมูลบริบทจากเส้นทางกากบาทของจุดเป้าหมายคือการจับเมื่อ r = 1 ด้วยการใช้โมดูลกากบาทอีกหนึ่งโมดูลคือ R = 2 ในที่สุด RCCA สามารถรวมข้อมูลบริบทที่หนาแน่นและสมบูรณ์ยิ่งขึ้นเมื่อเทียบกับของ R = 1 นอกจากนี้เราสังเกตว่าโมดูลความสนใจสามารถจับความคล้ายคลึงกันทางความหมายและการพึ่งพาระยะยาว
CCNET เปิดตัวภายใต้ใบอนุญาต MIT (ดูไฟล์ใบอนุญาตสำหรับรายละเอียด)
หากคุณพบว่า CCNET มีประโยชน์ในการวิจัยของคุณโปรดพิจารณาอ้าง:
@article { huang2020ccnet ,
author = { Huang, Zilong and Wang, Xinggang and Wei, Yunchao and Huang, Lichao and Shi, Humphrey and Liu, Wenyu and Huang, Thomas S. } ,
journal = { IEEE Transactions on Pattern Analysis and Machine Intelligence } ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
year = { 2020 } ,
month = { } ,
volume = { } ,
number = { } ,
pages = { 1-1 } ,
keywords = { Semantic Segmentation;Graph Attention;Criss-Cross Network;Context Modeling } ,
doi = { 10.1109/TPAMI.2020.3007032 } ,
ISSN = { 1939-3539 } }
@article { huang2018ccnet ,
title = { CCNet: Criss-Cross Attention for Semantic Segmentation } ,
author = { Huang, Zilong and Wang, Xinggang and Huang, Lichao and Huang, Chang and Wei, Yunchao and Liu, Wenyu } ,
booktitle = { ICCV } ,
year = { 2019 } } ในการติดตั้ง pytorch == 0.4.0 หรือ 0.4.1 โปรดดูที่ https://github.com/pytorch/pytorch#installation
4 x 12g GPU ( เช่น Titan XP)
Python 3.6
GCC (GCC) 4.8.5
Cuda 8.0
# Install **Pytorch**
$ conda install pytorch torchvision -c pytorch
# Install **Apex**
$ git clone https://github.com/NVIDIA/apex
$ cd apex
$ pip install -v --no-cache-dir --global-option= " --cpp_ext " --global-option= " --cuda_ext " ./
# Install **Inplace-ABN**
$ git clone https://github.com/mapillary/inplace_abn.git
$ cd inplace_abn
$ python setup.py install PLESAE ดาวน์โหลดชุดข้อมูล CityScapes และคลายซิปชุดข้อมูลลงใน YOUR_CS_PATH
โปรดดาวน์โหลด mit imagenet pretrained resnet101-imagenet.pth และใส่ลงในโฟลเดอร์ dataset
สคริปต์การฝึกอบรม
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2【 แนะนำ 】คุณยังสามารถเปิดธง OHEM เพื่อลดช่องว่างประสิทธิภาพระหว่าง VAL และชุดทดสอบ
python train.py --data-dir ${YOUR_CS_PATH} --random-mirror --random-scale --restore-from ./dataset/resnet101-imagenet.pth --gpu 0,1,2,3 --learning-rate 1e-2 --input-size 769,769 --weight-decay 1e-4 --batch-size 8 --num-steps 60000 --recurrence 2 --ohem 1 --ohem-thres 0.7 --ohem-keep 100000สคริปต์การประเมินผล
python evaluate.py --data-dir ${YOUR_CS_PATH} --restore-from snapshots/CS_scenes_60000.pth --gpu 0 --recurrence 2ทั้งหมดในหนึ่ง
./run_local.sh YOUR_CS_PATHเราเรียกใช้ CCNET ด้วย r = 1,2 สามครั้งในชุดข้อมูล CityScape แยกกันและรายงานผลลัพธ์ในตารางต่อไปนี้ โปรดทราบว่ามีปัญหาบางอย่างเกี่ยวกับช่องว่างการตรวจสอบ/ทดสอบความแม่นยำ (1 ~ 2%) คุณต้องทำงานหลายครั้งเพื่อให้ได้ช่องว่างเล็ก ๆ หรือเปิดธง Ohem การเปิดธง OHEM ยังสามารถปรับปรุงประสิทธิภาพในชุด VAL โดยทั่วไป, ฉันขอแนะนำให้คุณใช้ OHEM ในขั้นตอนการฝึกอบรม
เราฝึกอบรมทุกรุ่นในชุดการฝึกอบรมที่ดีและใช้สเกลเดียวสำหรับการทดสอบ รูปแบบที่ผ่านการฝึกอบรมด้วย R = 2 79.74 สามารถบรรลุได้ประมาณ 79.01 MIOU ใน ชุดทดสอบทิวทัศน์ของเมือง ด้วยการทดสอบระดับเดียว (เพื่อประหยัดเวลาเราใช้ภาพทั้งหมดเป็นอินพุต)
| R | Miou on Cityscape Val Set (สเกลเดี่ยว) | การเชื่อมโยง |
|---|---|---|
| 1 | 77.31 & 77.91 & 76.89 | 77.91 |
| 2 | 79.74 & 79.22 & 78.40 | 79.74 |
| 2+OHEM | 78.67 & 80.00 & 79.83 | 80.00 |
เราขอขอบคุณ NSFC, ARC Decra DE190101315, ARC DP200100938, Vision Computer Horizon Vision Center และศูนย์วิจัย IBM-ILLINOIS เพื่อการวิจัยการคำนวณทางปัญญา (C3SR)
วิธีการที่เกี่ยวข้องกับการดูแลตนเอง:
เครือข่ายบริบทวัตถุ
เครือข่ายความสนใจคู่
กล่องเครื่องมือการแบ่งส่วนความหมาย:
Pytorch-segmentation-toolbox
ความหมายของการแบ่งส่วน
การเข้ารหัส pytorch


