BigGAN PyTorch
1.0.0
作者正式非官方的Pytorch Biggan實施。

該倉庫包含用於對Andrew Brock,Jeff Donahue和Karen Simonyan的大型GAN培訓的4-8 GPU培訓大型GPU培訓的代碼。
此代碼是Andy Brock和Alex Andonian的作者。
您將需要:
首先,您可以選擇更快地準備目標數據集的預處理的HDF5版本。之後(或不),您將需要計算FID所需的啟動時刻。這些都可以通過修改和運行來完成
sh scripts/utils/prepare_data.sh默認情況下,假設您的Imagenet訓練集將其下載到此目錄中的根文件夾data中,並將在128x128像素分辨率下準備緩存的HDF5。
在“腳本”文件夾中,有多個bash腳本,可以訓練具有不同批次大小的大型腳本。該代碼假設您無法訪問完整的TPU POD,因此,通過使用梯度累積(在多個Minibatches上平均畢業生,並且僅在N積累後才採取優化器步驟),從而欺騙了大型批次。默認情況下, launch_BigGAN_bs256x8.sh腳本訓練了一個全尺寸的Biggan型號,批次大小為256和8梯度積累,總批量的總尺寸為2048。在8xv100上,具有完整的精確培訓(無張量的核心),該腳本需要15天才能訓練150天的150k次數。
您首先需要找出設置可以支持的最大批量尺寸。此處提供的預訓練模型在8xV100(每個16GB VRAM)上進行了培訓,該模型的支持略高於默認使用的BS256。確定此問題後,您應該修改腳本,以使批處理次數梯度累積的數量等於您所需的總批量尺寸(BigGan默認值為2048)。
還要注意,此腳本使用--load_in_mem arg,該腳本將整個(〜64GB)i128.hdf5文件加載到RAM中以進行更快的數據加載。如果您沒有足夠的RAM來支持此(可能是96GB+),請刪除此參數。

在培訓期間,該腳本將使用訓練指標和測試指標輸出日誌,將節省模型權重/優化器參數的多個副本(最新和5個得分最高),並每次節省權重時都會產生樣品和插值。日誌文件夾包含用於處理這些日誌並使用MATLAB繪製結果的腳本(對不起,對不起)。
訓練後,人們可以使用sample.py產生其他樣本和插值,以不同的截斷值,批次大小,站立統計量sample_BigGAN_bs256x8.sh累積數量等測試。
默認情況下,所有內容都保存到了權重/示例/日誌/數據文件夾中,這些文件夾被假定在與此存儲夾相同的文件夾中。您可以使用--base_root參數將所有這些指向不同的基本文件夾,也可以使用其各自的參數(例如--logs_root )為每個方面選擇特定位置。
我們包括可以運行Biggan-De-Deep的腳本,但我們尚未使用它們進行完全訓練的模型,因此請考慮未經測試。此外,我們還包括在Cifar上運行模型的腳本,並在Imagenet上運行SA-GAN(與EMA)和SN-GAN。 SA-GAN代碼假設您具有4xtitanx(或在GPU RAM方面相同),並且將以128和2梯度累積的批次大小運行。
此存儲庫使用Pytorch Incept Inception網絡來計算IS和FID。這些分數不同於您使用官方TF Inception代碼獲得的分數,僅用於監視目的!在模型上運行sample.py,並使用--sample_npz參數,然後運行inception_tf13以計算實際的張量為。請注意,您需要安裝TensorFlow 1.3或更早,因為TF1.4+打破了原件是代碼。
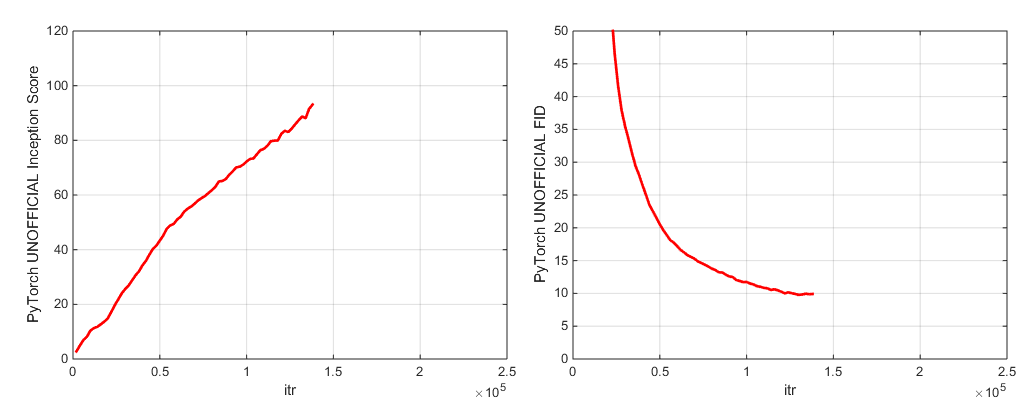 我們包括兩個驗證的模型檢查點(使用G,D,G的EMA副本,優化器和狀態):
我們包括兩個驗證的模型檢查點(使用G,D,G的EMA副本,優化器和狀態):
預計的365號地點模型即將到來。
此存儲庫還包含用於將原始TFHUB Biggan Generator重量移植到Pytorch的腳本。有關更多詳細信息,請參見TFHUB文件夾中的腳本。

如果您想恢復中斷的培訓或微調預訓練的模型,請運行相同的啟動腳本,但要添加--resume參數。實驗名稱是從配置自動生成的,但是可以使用--experiment_name arg覆蓋(例如,如果您希望使用修改的優化器設置來微調模型)。
要準備自己的數據集,您需要將其添加到dataSets.py.py並修改utils.py中的便利性(dset_dict,imsize_dict,root_dict,nclass_dict,class_per_sheet_dict),以使數據集具有適當的元數據。在prepar_data.sh中重複該過程(可選地產生HDF5預處理副本,併計算FID的啟動矩)。
默認情況下,培訓腳本將通過Inception評分來節省前5個最佳檢查點。對於ImageNet以外的數據集,Inception評分可能是非常差的質量衡量標準,因此您可能想使用--which_best FID 。
要使用自己的訓練功能(例如,訓練一個bigvae):修改train_fns.gan_training_function或添加新的火車FN,然後在if config['which_train_fn'] == 'GAN': in train.py中添加。
--num_G_SVs參數計算更多SVS。 該代碼是從頭開始設計的,以作為進一步研究代碼的可擴展,可侵入的基礎。我們已經進行了很多思考,以確保抽像是研究的正確厚度 - 不是很厚,以至於無法穿透,但並不是那麼薄,以至於沒有用。關鍵的想法是,如果您想嘗試SOTA設置並進行一些修改(嘗試自己的新損失功能,體系結構,自我發揮作用塊等),您應該可以通過將代碼放在一個或兩個地方來輕鬆地做到這一點,而不必擔心其餘的代碼庫。諸如self.s self.s and.conv and functools.partial的使用之類的東西都將其與此相關的腦海中匯總在一起,以及光譜規範類繼承的設計。
話雖如此,這是一個單個項目的大型代碼庫。儘管我們試圖對評論進行徹底的評價,但如果您認為有更清楚,更好的書面或更好地重構的內容,請隨時提出問題或提取請求。
是否想處理或改進此代碼?該倉庫可以從中受益幾件事,但尚不正常。
有關Imagenet標籤,請參見此目錄。
如果您使用此代碼,請引用
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
感謝Google的慷慨雲信用捐贈。
Jiayuan Mao和Tete Xiao的Syncbn。
進度酒吧最初來自JanSchlüter。
來自Voxnet的測試指標記錄儀。
Pytorch從Modar M. Alfadly實施COV。
Tsung-Yu Lin和Subhransu Maji的FID的Pytorch快速矩陣SQRT。
TensorFlow Inception分數代碼來自Openai的改進gan。


