BigGAN PyTorch
1.0.0
作者正式非官方的Pytorch Biggan实施。

该仓库包含用于对Andrew Brock,Jeff Donahue和Karen Simonyan的大型GAN培训的4-8 GPU培训大型GPU培训的代码。
此代码是Andy Brock和Alex Andonian的作者。
您将需要:
首先,您可以选择更快地准备目标数据集的预处理的HDF5版本。之后(或不),您将需要计算FID所需的启动时刻。这些都可以通过修改和运行来完成
sh scripts/utils/prepare_data.sh默认情况下,假设您的Imagenet训练集将其下载到此目录中的根文件夹data中,并将在128x128像素分辨率下准备缓存的HDF5。
在“脚本”文件夹中,有多个bash脚本,可以训练具有不同批次大小的大型脚本。该代码假设您无法访问完整的TPU POD,因此,通过使用梯度累积(在多个Minibatches上平均毕业生,并且仅在N积累后才采取优化器步骤),从而欺骗了大型批次。默认情况下, launch_BigGAN_bs256x8.sh脚本训练了一个全尺寸的Biggan型号,批次大小为256和8梯度积累,总批量的总尺寸为2048。在8xv100上,具有完整的精确培训(无张量的核心),该脚本需要15天才能训练150天的150k次数。
您首先需要找出设置可以支持的最大批量尺寸。此处提供的预训练模型在8xV100(每个16GB VRAM)上进行了培训,该模型的支持略高于默认使用的BS256。确定此问题后,您应该修改脚本,以使批处理次数梯度累积的数量等于您所需的总批量尺寸(BigGan默认值为2048)。
还要注意,此脚本使用--load_in_mem arg,该脚本将整个(〜64GB)i128.hdf5文件加载到RAM中以进行更快的数据加载。如果您没有足够的RAM来支持此(可能是96GB+),请删除此参数。

在培训期间,该脚本将使用训练指标和测试指标输出日志,将节省模型权重/优化器参数的多个副本(最新和5个得分最高),并每次节省权重时都会产生样品和插值。日志文件夹包含用于处理这些日志并使用MATLAB绘制结果的脚本(对不起,对不起)。
训练后,人们可以使用sample.py产生其他样本和插值,以不同的截断值,批次大小,站立统计量sample_BigGAN_bs256x8.sh累积数量等测试。
默认情况下,所有内容都保存到了权重/示例/日志/数据文件夹中,这些文件夹被假定在与此存储夹相同的文件夹中。您可以使用--base_root参数将所有这些指向不同的基本文件夹,也可以使用其各自的参数(例如--logs_root )为每个方面选择特定位置。
我们包括可以运行Biggan-De-Deep的脚本,但我们尚未使用它们进行完全训练的模型,因此请考虑未经测试。此外,我们还包括在Cifar上运行模型的脚本,并在Imagenet上运行SA-GAN(与EMA)和SN-GAN。 SA-GAN代码假设您具有4xtitanx(或在GPU RAM方面相同),并且将以128和2梯度累积的批次大小运行。
此存储库使用Pytorch Incept Inception网络来计算IS和FID。这些分数不同于您使用官方TF Inception代码获得的分数,仅用于监视目的!在模型上运行sample.py,并使用--sample_npz参数,然后运行inception_tf13以计算实际的张量为。请注意,您需要安装TensorFlow 1.3或更早,因为TF1.4+打破了原件是代码。
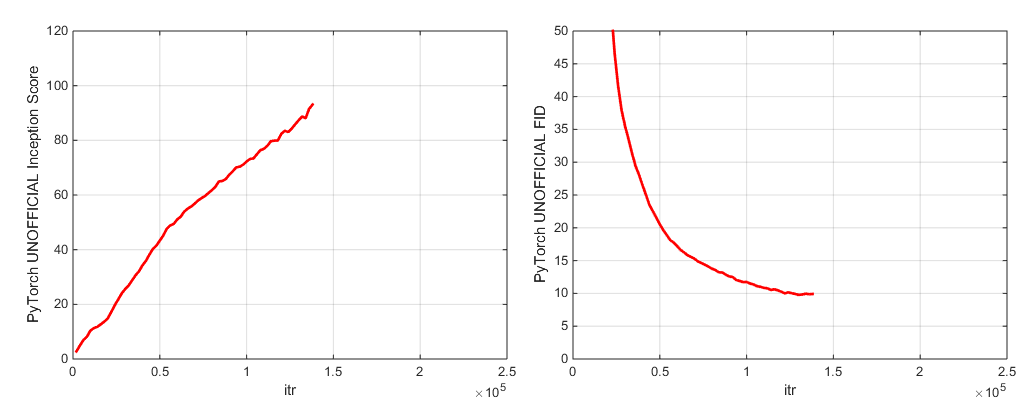 我们包括两个验证的模型检查点(使用G,D,G的EMA副本,优化器和状态):
我们包括两个验证的模型检查点(使用G,D,G的EMA副本,优化器和状态):
预计的365号地点模型即将到来。
此存储库还包含用于将原始TFHUB Biggan Generator重量移植到Pytorch的脚本。有关更多详细信息,请参见TFHUB文件夹中的脚本。

如果您想恢复中断的培训或微调预训练的模型,请运行相同的启动脚本,但要添加--resume参数。实验名称是从配置自动生成的,但是可以使用--experiment_name arg覆盖(例如,如果您希望使用修改的优化器设置来微调模型)。
要准备自己的数据集,您需要将其添加到dataSets.py.py并修改utils.py中的便利性(dset_dict,imsize_dict,root_dict,nclass_dict,class_per_sheet_dict),以使数据集具有适当的元数据。在prepar_data.sh中重复该过程(可选地产生HDF5预处理副本,并计算FID的启动矩)。
默认情况下,培训脚本将通过Inception评分来节省前5个最佳检查点。对于ImageNet以外的数据集,Inception评分可能是非常差的质量衡量标准,因此您可能想使用--which_best FID 。
要使用自己的训练功能(例如,训练一个bigvae):修改train_fns.gan_training_function或添加新的火车FN,然后在if config['which_train_fn'] == 'GAN': in train.py中添加。
--num_G_SVs参数计算更多SVS。 该代码是从头开始设计的,以作为进一步研究代码的可扩展,可侵入的基础。我们已经进行了很多思考,以确保抽象是研究的正确厚度 - 不是很厚,以至于无法穿透,但并不是那么薄,以至于没有用。关键的想法是,如果您想尝试SOTA设置并进行一些修改(尝试自己的新损失功能,体系结构,自我发挥作用块等),您应该可以通过将代码放在一个或两个地方来轻松地做到这一点,而不必担心其余的代码库。诸如self.s self.s and.conv and functools.partial的使用之类的东西都将其与此相关的脑海中汇总在一起,以及光谱规范类继承的设计。
话虽如此,这是一个单个项目的大型代码库。尽管我们试图对评论进行彻底的评价,但如果您认为有更清楚,更好的书面或更好地重构的内容,请随时提出问题或提取请求。
是否想处理或改进此代码?该仓库可以从中受益几件事,但尚不正常。
有关Imagenet标签,请参见此目录。
如果您使用此代码,请引用
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
感谢Google的慷慨云信用捐赠。
Jiayuan Mao和Tete Xiao的Syncbn。
进度酒吧最初来自JanSchlüter。
来自Voxnet的测试指标记录仪。
Pytorch从Modar M. Alfadly实施COV。
Tsung-Yu Lin和Subhransu Maji的FID的Pytorch快速矩阵SQRT。
TensorFlow Inception分数代码来自Openai的改进gan。


