BigGAN PyTorch
1.0.0
مؤلف المؤلف رسميا بتنفيذ بيتورش بيغان.

يحتوي هذا الريبو على رمز لـ 4-8 GPU التدريب على Biggans من تدريب GAN على نطاق واسع من أجل تخليق الصور الطبيعية العالية Fidelity من تأليف أندرو بروك ، وجيف دوناهو ، وكارين سيمونيان.
هذا الرمز من تأليف أندي بروك وأليكس أندريان.
سوف تحتاج:
أولاً ، يمكنك إعداد إصدار HDF5 الذي تم معالجته مسبقًا من مجموعة البيانات المستهدفة الخاصة بك لأجهزة I/O أسرع. بعد هذا (أو لا) ، ستحتاج إلى لحظات البدء اللازمة لحساب FID. يمكن أن يتم ذلك عن طريق التعديل والتشغيل
sh scripts/utils/prepare_data.sh الذي يفترض افتراضيًا ، يتم تنزيل مجموعة تدريب ImageNet الخاصة بك في data المجلد الجذر في هذا الدليل ، وسيقوم بإعداد HDF5 المخزنة مؤقتًا بدقة 128x128 بكسل.
في مجلد البرامج النصية ، هناك نصوص باش متعددة ستقوم بتدريب Biggans بأحجام دفع مختلفة. يفترض هذا الرمز أنه لا يمكنك الوصول إلى جراب TPU الكامل ، وبناءً على ذلك ، فإن محاكاة الدموية الضخمة باستخدام تراكم التدرج (متوسط الخريجين على حافزات صغيرة متعددة ، واتخاذ خطوة مُحسّنة فقط بعد تراكم N). بشكل افتراضي ، يقوم برنامج التشغيل launch_BigGAN_bs256x8.sh بتدريب نموذج كبير بالحجم الكامل بحجم 256 و 8 تراكم متدرج ، للحصول على حجم إجمالي قدره 2048. في 8xv100 مع تدريب كامل الدقة (لا يوجد توترات توتر) ، يستغرق هذا البرنامج النصي 150 يومًا إلى 150 ألفًا.
ستحتاج أولاً إلى اكتشاف الحد الأقصى لحجم الدُفعة التي يمكن أن يدعمها الإعداد. تم تدريب النماذج التي تم تدريبها مسبقًا المقدمة هنا على 8xv100 (16 جيجا بايت لكل منهما) والتي يمكن أن تدعم أكثر بقليل من BS256 المستخدم افتراضيًا. بمجرد تحديد ذلك ، يجب عليك تعديل البرنامج النصي بحيث يكون حجم الدُفعة يزيد من عدد تراكم التدرج يساوي حجم الدفعة المطلوب (Biggan Defults إلى 2048).
لاحظ أيضًا أن هذا البرنامج النصي يستخدم --load_in_mem arg ، والذي يقوم بتحميل ملف i128.hdf5 بالكامل (~ 64 جيجا بايت) في ذاكرة الوصول العشوائي لتحميل البيانات بشكل أسرع. إذا لم يكن لديك ما يكفي من ذاكرة الوصول العشوائي لدعم هذا (ربما 96 جيجابايت+) ، قم بإزالة هذه الوسيطة.

أثناء التدريب ، سيقوم هذا البرنامج النصي بإخراج سجلات مع مقاييس التدريب ومقاييس الاختبار ، وسيوفر نسخ متعددة (أحدث و 5 درجات أعلى) من الأوزان/المُحسَّنة النموذجية ، وسوف تنتج عينات واستيفاء في كل مرة يوفر فيها الأوزان. يحتوي مجلد Logs على البرامج النصية لمعالجة هذه السجلات ورسم النتائج باستخدام MATLAB (آسف ليس آسف).
بعد التدريب ، يمكن للمرء sample_BigGAN_bs256x8.sh sample.py لإنتاج عينات إضافية واستيفاءات ، واختبار مع قيم اقتطاع مختلفة ، وأحجام الدُفعات ، وعدد تراكم الأساسيات الدائمة ، وما إلى ذلك.
بشكل افتراضي ، يتم حفظ كل شيء على الأوزان/العينات/سجلات/مجلدات البيانات التي يُفترض أنها في نفس المجلد مثل هذا الريبو. يمكنك توجيه كل هذه الأشياء إلى مجلد أساسي مختلف باستخدام الوسيطة --base_root ، أو اختيار مواقع محددة لكل من هذه الوسائط الخاصة بها (على سبيل المثال --logs_root ).
نحن ندرج البرامج النصية لتشغيل Biggan-Deep ، لكننا لم ندرب نموذجًا تمامًا باستخدامها ، لذا فكروا في ذلك. بالإضافة إلى ذلك ، نقوم بتضمين البرامج النصية لتشغيل نموذج على CIFAR ، وتشغيل SA-GAN (مع EMA) و SN-GAN على ImageNet. يفترض رمز SA-GAN أن لديك 4xtitanx (أو ما يعادلها من حيث RAM GPU) وسيتم تشغيله بحجم دفعة من 128 و 2 تراكم التدرج.
يستخدم هذا الريبو شبكة التأسيس في Pytorch في حساب IS و FID. تختلف هذه الدرجات عن الدرجات التي ستحصل عليها باستخدام رمز تأسيس TF الرسمي ، وهي فقط لأغراض المراقبة! قم بتشغيل sample.py على النموذج الخاص بك ، باستخدام وسيطة --sample_npz ، ثم قم بتشغيل inception_tf13 لحساب tensorflow الفعلي. لاحظ أنك ستحتاج إلى تثبيت TensorFlow 1.3 أو تم تثبيته في وقت سابق ، حيث يقوم TF1.4+ بفك الرمز الأصلي.
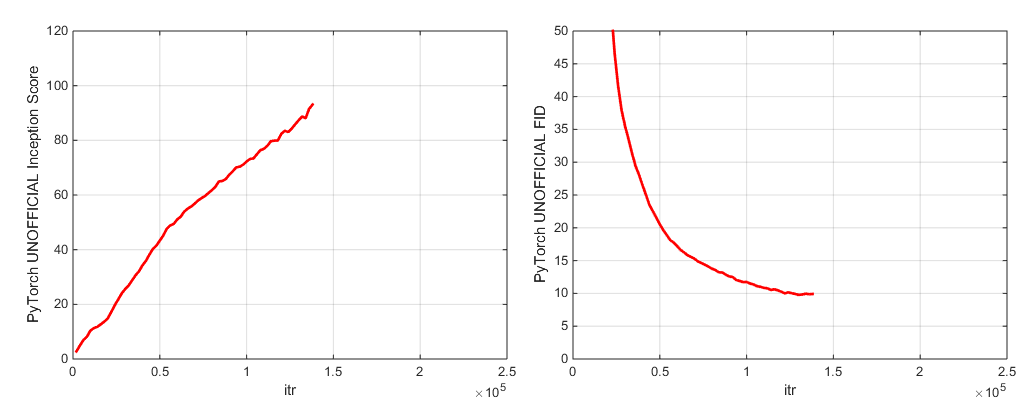 نحن ندرج نقاط تفتيش نموذجية من النماذج (مع G و D ونسخة EMA من G و The Pensidizers و DICT):
نحن ندرج نقاط تفتيش نموذجية من النماذج (مع G و D ونسخة EMA من G و The Pensidizers و DICT):
نماذج مسبقة للأماكن-365 قريبا.
يحتوي هذا الريبو أيضًا على برامج نصية لتنظيف أوزان مولد TFHUB Biggan الأصلية إلى Pytorch. انظر البرامج النصية في مجلد TFHUB لمزيد من التفاصيل.

إذا كنت ترغب في استئناف التدريب المقطع أو ضبط نموذج تم تدريبه مسبقًا ، فقم بتشغيل نفس البرنامج النصي للانطلاق ولكن مع --resume الحجة المضافة. يتم إنشاء أسماء التجربة تلقائيًا من التكوين ، ولكن يمكن تجاوزها باستخدام- --experiment_name arg (على سبيل المثال ، إذا كنت ترغب في ضبط نموذج باستخدام إعدادات مُحسّنة معدلة).
لإعداد مجموعة البيانات الخاصة بك ، ستحتاج إلى إضافتها إلى مجموعات البيانات. ypy وتعديل التصميمات الراحة في utils.py (dset_dict ، imsize_dict ، root_dict ، nclass_dict ، classes_per_sheet_dict) للحصول على البيانات الوصفية المناسبة لمجموعة البيانات الخاصة بك. كرر العملية في prepared_data.sh (تنتج اختياريا نسخة HDF5 معالجة مسبقا ، وحساب لحظات بدء FID).
بشكل افتراضي ، سيوفر البرنامج النصي التدريبي أفضل 5 نقاط تفتيش كما تم قياسها من خلال درجة البداية. بالنسبة لمجموعات البيانات بخلاف ImageNet ، يمكن أن تكون نقاط Inception مقياسًا سيئًا للغاية للجودة ، لذلك من المحتمل أن ترغب في استخدام --which_best FID بدلاً من ذلك.
لاستخدام وظيفة التدريب الخاصة بك (على سبيل المثال ، قم بتدريب BigVae): إما تعديل Train_fns.gan_training_function أو إضافة قطار جديد وأضفه بعد if config['which_train_fn'] == 'GAN': line in train.py .
--num_G_SVs . تم تصميم هذا الرمز من الألف إلى الياء ليكون بمثابة قاعدة قابلة للتمديد يمكن اختراقها لمزيد من رمز البحث. لقد وضعنا الكثير من التفكير في التأكد من أن التجريدات هي السماكة المناسبة للبحث-ليس سميكًا جدًا بحيث لا يمكن اختراقه ، ولكن ليس رفيعًا بحيث يكون عديمة الفائدة. الفكرة الرئيسية هي أنه إذا كنت ترغب في تجربة إعداد SOTA وإجراء بعض التعديل (جرب وظيفة الخسارة الجديدة الخاصة بك ، والهندسة المعمارية ، وكتلة الاعتداء الذاتي ، وما إلى ذلك) ، فيجب أن تكون قادرًا على القيام بذلك بسهولة عن طريق إسقاط الكود في مكان واحد أو مكانين ، دون الحاجة إلى القلق بشأن بقية قاعلة الكود. أشياء مثل استخدام Self.hich_conv و functools.partial في تعريف نموذج Biggan.py مع هذا في الاعتبار ، كما كان تصميم ميراث الطبقة الطيفية.
مع ذلك ، هذه قاعدة كود كبيرة إلى حد ما لمشروع واحد. على الرغم من أننا حاولنا أن نكون شاملين في التعليقات ، إذا كان هناك شيء تعتقد أنه قد يكون أكثر وضوحًا أو مكتوبة بشكل أفضل أو تم إعادة تشكيله بشكل أفضل ، فلا تتردد في إثارة مشكلة أو طلب سحب.
هل تريد العمل على هذا الرمز أو تحسينه؟ هناك أمرين سيستفيد منه هذا الريبو ، ولكنه لا يعمل بعد.
انظر هذا الدليل لتسميات ImageNet.
إذا كنت تستخدم هذا الرمز ، يرجى الاستشهاد
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
بفضل Google على التبرعات الائتمانية السحابية السخية.
Syncbn بواسطة Jiayuan Mao و Tete Xiao.
شريط التقدم في الأصل من جان شلتر.
اختبار مقاييس المسجل من voxnet.
تنفيذ Pytorch من COV من Modar M. Alfadly.
Pytorch Fast Matrix SQRT لـ FID من Tsung-Yu Lin و Subhransu Maji.
رمز نقاط تأسيس TensorFlow من Openai المحسّن.


