BigGAN PyTorch
1.0.0
저자의 공식적으로 비공식 Pytorch Biggan 구현.

이 repo에는 Andrew Brock, Jeff Donahue 및 Karen Simonyan의 고 충실도 자연 이미지 합성을위한 대규모 GAN 훈련에서 Biggans에 대한 4-8 GPU 교육 코드가 포함되어 있습니다.
이 코드는 Andy Brock과 Alex Andonian의 것입니다.
당신은 필요할 것입니다 :
먼저, 더 빠른 I/O를 위해 대상 데이터 세트의 사전 처리 된 HDF5 버전을 선택적으로 준비 할 수 있습니다. 이후에 (또는 그렇지 않음) FID를 계산하는 데 필요한 시작 순간이 필요합니다. 이들은 수정 및 실행을 통해 수행 할 수 있습니다
sh scripts/utils/prepare_data.sh 기본적으로 ImageNet 교육 세트 가이 디렉토리의 루트 폴더 data 로 다운로드되었다고 가정하고 128x128 픽셀 해상도로 캐시 된 HDF5를 준비합니다.
스크립트 폴더에는 배치 크기가 다른 큰 배쉬 스크립트가 여러 개 있습니다. 이 코드는 전체 TPU POD에 액세스 할 수 없다고 가정하고, 그라디언트 축적을 사용하여 대형 배치를 스푸핑합니다 (여러 미니 디바치의 grad를 평균화하고 N 축적 후 최적화 단계 만 수행). 기본적으로 launch_BigGAN_bs256x8.sh 스크립트는 총 배치 크기가 256 및 8 그라디언트 축적의 전체 크기의 Biggan 모델을 훈련합니다.
먼저 설정이 지원할 수있는 최대 배치 크기를 파악해야합니다. 여기에 제공된 미리 훈련 된 모델은 기본적으로 사용되는 BS256보다 약간 더 많은 것을 지원할 수있는 8xv100 (각각 16GB VRAM)에서 교육을 받았습니다. 이를 결정하면 배치 크기가 구배 축적 수가 원하는 총 배치 크기 (Biggan 기본값 2048)와 동일하도록 스크립트를 수정해야합니다.
또한이 스크립트는 --load_in_mem arg를 사용하여 전체 (~ 64GB) i128.hdf5 파일을 RAM에로드하여 더 빠른 데이터로드를 위해 RAM에로드합니다. 이를 지원할 RAM이 충분하지 않으면 (아마도 96GB+)이 인수를 제거하십시오.

훈련 중에이 스크립트는 교육 메트릭 및 테스트 메트릭으로 로그를 출력하고 모델 가중/최적화 매개 변수의 여러 사본 (가장 최근 및 5 개의 가장 높은 점수)을 저장하며 가중치를 절약 할 때마다 샘플 및 보간을 생성합니다. 로그 폴더에는 이러한 로그를 처리하고 MATLAB을 사용하여 결과를 플로팅하기위한 스크립트가 포함되어 있습니다 (죄송합니다).
훈련 후 sample.py sample_BigGAN_bs256x8.sh 하여 추가 샘플 및 보간을 생성하고 다른 잘린 값, 배치 크기, 스탠딩 스탯 축적 수 등으로 테스트 할 수 있습니다.
기본적으로 모든 것이이 repo와 동일한 폴더에 있다고 가정되는 가중치/샘플/로그/데이터 폴더에 저장됩니다. --base_root 인수를 사용 하여이 모든 것을 다른 기본 폴더에 가리키거나 해당 인수 (예 : --logs_root )와 함께 각각의 각각의 특정 위치를 선택할 수 있습니다.
우리는 Biggan-Deep를 실행하는 스크립트를 포함하지만, 모델을 완전히 훈련시키지 않았으므로 테스트되지 않은 것을 고려하십시오. 또한 CIFAR에서 모델을 실행하고 ImaGenet에서 SA-Gan (EMA) 및 SN-GAN을 실행하는 스크립트가 포함되어 있습니다. SA-GAN 코드는 4XTITANX (또는 GPU RAM의 관점에서 동등한)가 있다고 가정하고 128 및 2 개의 그라디언트 축적으로 실행됩니다.
이 repo는 Pytorch 내에서 구축 된 Inception 네트워크를 사용하여 IS 및 FID를 계산합니다. 이 점수는 공식 TF Inception 코드를 사용하는 점수와 다르며 모니터링 목적으로 만 사용됩니다! --sample_npz 인수를 사용하여 모델에서 Sample.py를 실행 한 다음 inception_tf13을 실행하여 실제 텐서 플로우를 계산하십시오. TF1.4+가 원본 IS 코드를 중단하므로 Tensorflow 1.3 이상이 설치되어 있어야합니다.
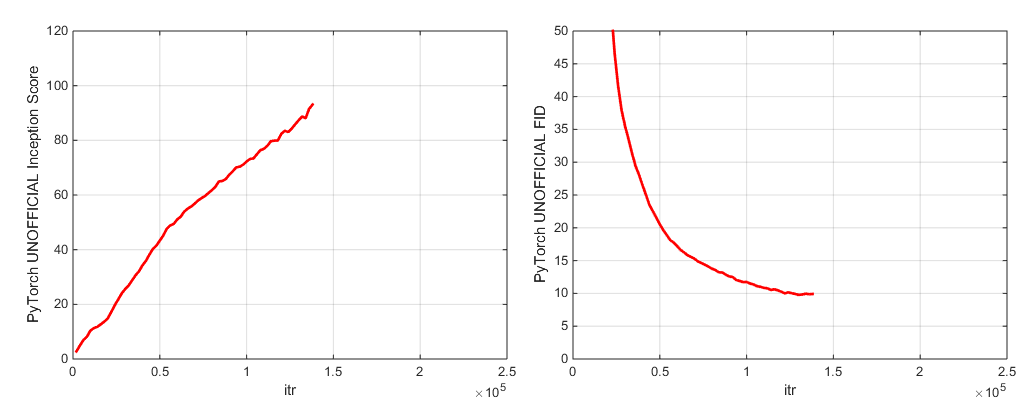 우리는 2 개의 사전 예방 된 모델 체크 포인트 (G, D, G의 EMA 사본, 최적화 및 상태 dict)를 포함합니다.
우리는 2 개의 사전 예방 된 모델 체크 포인트 (G, D, G의 EMA 사본, 최적화 및 상태 dict)를 포함합니다.
장소 -365에 대한 사전 제한 모델이 곧 출시 될 예정입니다.
이 repo에는 원래 TFHUB Biggan Generator Weights를 Pytorch로 포팅하기위한 스크립트도 포함되어 있습니다. 자세한 내용은 TFHUB 폴더의 스크립트를 참조하십시오.

중단 교육을 재개하거나 미리 훈련 된 모델을 미세 조정하려면 동일한 출시 스크립트를 실행하지만 --resume 메 인수가 추가되었습니다. 실험 이름은 구성에서 자동으로 생성되지만 --experiment_name arg (예 : 수정 된 Optimizer 설정을 사용하여 모델을 미세 조정하려는 경우)를 사용하여 재정의 할 수 있습니다.
자신의 데이터 세트를 준비하려면 DataSets.py에 추가하고 utils.py (dset_dict, imsize_dict, root_dict, nclass_dict, class_per_sheet_dict)에서 편의 학습을 수정해야합니다. prepary_data.sh에서 프로세스를 반복하십시오 (선택적으로 HDF5 전처리 사본을 생성하고 FID의 시작 순간을 계산하십시오).
기본적으로 교육 스크립트는 Inception 점수로 측정 된 상위 5 개의 최고의 체크 포인트를 저장합니다. ImageNet 이외의 데이터 세트의 경우 Inception Score --which_best FID 품질이 매우 좋지 않을 수 있으므로 대신 사용하고 싶을 것입니다.
자신의 교육 기능 (예 : Bigvae Train)을 사용하려면 : Train_fns.gan_training_function을 수정하거나 새 열차 FN을 추가하고 if config['which_train_fn'] == 'GAN': train.py 에서 줄을 추가합니다.
--num_G_SVs 인수를 통해 더 많은 SV를 컴퓨팅하는 것을 지원합니다. 이 코드는 처음부터 추가 연구 코드를위한 확장 가능한 해킹 가능한 기반으로 사용되도록 설계되었습니다. 우리는 추상화가 연구에 적합한 두께인지 확인하는 데 많은 생각을했습니다. 뚫을 수없는 것만 큼 두껍지는 않지만 쓸모없는 것만 큼 얇지는 않습니다. 핵심 아이디어는 SOTA 설정을 실험하고 수정하려면 (새로운 손실 함수, 아키텍처, 자체 변환 블록 등을 시도해보십시오) 코드베이스의 나머지 부분에 대해 걱정할 필요없이 코드를 한두 곳에서 삭제하면 쉽게 그렇게 할 수 있다는 것입니다. selfgan.py 모델 정의에서 self.hich_conv 및 functools.partial의 사용과 같은 것들이 스펙트럼 규범 클래스 상속의 설계와 마찬가지로 이것을 염두에 두었습니다.
그 말로, 이것은 단일 프로젝트를위한 다소 큰 코드베이스입니다. 우리가 의견을 철저히하려고 노력했지만, 더 명확하거나, 더 나은 글을 쓰거나, 재현 할 수 있다고 생각하는 것이 있다면, 자유롭게 문제 나 풀 요청을 제기하십시오.
이 코드를 작업하거나 개선하고 싶습니까? 이 repo가 혜택을받을 몇 가지가 있지만 아직 작동하지 않습니다.
ImageNet 레이블 은이 디렉토리를 참조하십시오.
이 코드를 사용하는 경우 인용하십시오
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
관대 한 클라우드 신용 기부에 대한 Google에게 감사드립니다.
Jiyuan Mao와 Tete Xiao의 Syncbn.
Progress Bar는 원래 Jan Schlüter에서.
Voxnet의 테스트 메트릭 로거.
Modar M. Alfadly에서 COV의 Pytorch 구현.
Tsung-Yu Lin 및 Subhransu Maji의 FID 용 Pytorch Fast Matrix SQRT.
OpenAI의 개선 된 -GAN의 TensorFlow Inception 점수 코드.


