BigGAN PyTorch
1.0.0
A implementação de Pytorch Biggan oficialmente oficialmente oficial do autor.

Este repositório contém código para o treinamento de 4-8 GPU de figuras de treinamento em grande escala GaN para síntese de imagem natural de alta fidelidade por Andrew Brock, Jeff Donahue e Karen Simonyan.
Este código é de Andy Brock e Alex Andonian.
Você precisará:
Primeiro, você pode opcionalmente preparar uma versão HDF5 pré-processada do seu conjunto de dados de destino para E/S mais rápida. Depois disso (ou não), você precisará dos momentos de início necessários para calcular o FID. Estes podem ser feitos modificando e executando
sh scripts/utils/prepare_data.sh O que, por padrão, assume que seu conjunto de treinamento ImageNet é baixado nos data da pasta raiz neste diretório e preparará o HDF5 em cache a resolução de 128x128 pixels.
Na pasta Scripts, existem vários scripts de bash que treinarão biggans com diferentes tamanhos de lote. Este código pressupõe que você não tenha acesso a um POD completo da TPU e, portanto, falsifica mega-lotes usando o acúmulo de gradiente (com a média de graduados em vários minibatches e apenas tomando um passo otimizador após n acumulações). Por padrão, o script launch_BigGAN_bs256x8.sh treina um modelo de biggan em tamanho grande com um tamanho de lote de 256 e 8 acumulações de gradiente, para um tamanho total de 2048.
Primeiro, você precisará descobrir o tamanho máximo em lote que sua configuração pode suportar. Os modelos pré-treinados fornecidos aqui foram treinados em 8xv100 (16 GB de VRAM cada), que podem suportar um pouco mais do que o BS256 usado por padrão. Depois de determinar isso, você deve modificar o script para que o tamanho do lote vezes o número de acumulações de gradiente seja igual ao tamanho total desejado do lote (o biggan padrão é 2048).
Observe também que este script usa o arquivo --load_in_mem carrega o arquivo inteiro (~ 64 GB) i128.hdf5 na RAM para um carregamento de dados mais rápido. Se você não tiver RAM suficiente para apoiar isso (provavelmente 96 GB+), remova esse argumento.

Durante o treinamento, este script produzirá logs com métricas de treinamento e métricas de teste, salvará várias cópias (2 mais recentes e 5 de maior pontuação) dos parâmetros de peso/otimizador do modelo e produzirão amostras e interpolações toda vez que economizam pesos. A pasta Logs contém scripts para processar esses logs e plotar os resultados usando o MATLAB (desculpe não desculpe).
Após o treinamento, pode -se usar sample.py para produzir amostras e interpolações adicionais, testar com diferentes valores de truncamento, tamanhos de lote, número de acumulações de estatísticas permanentes, etc. Consulte o script sample_BigGAN_bs256x8.sh para um exemplo.
Por padrão, tudo é salvo em pesos/amostras/logs/pastas de dados que se supõe estar na mesma pasta que este repo. Você pode apontar tudo isso para uma pasta de base diferente usando o argumento --base_root ou escolher locais específicos para cada um deles com seus respectivos argumentos (por exemplo --logs_root ).
Incluímos scripts para executar o Biggan, mas não treinamos totalmente um modelo usando-os, então considere-os não testados. Além disso, incluímos scripts para executar um modelo no CIFAR e para executar o sa-Gan (com EMA) e Sn-Gan no ImageNet. O código SA-GAN assume que você tem 4xtitanx (ou equivalente em termos de RAM da GPU) e será executado com um tamanho de lotes de 128 e 2 acumulações de gradiente.
Este repositório usa a rede de iniciativa Pytorch embutida para calcular o IS e o FID. Essas pontuações são diferentes das pontuações que você usaria usando o código oficial de Inception TF e são apenas para fins de monitoramento! Execute sample.py no seu modelo, com o argumento --sample_npz e execute o INFCECCECCETION_TF13 para calcular o tensorflow real é. Observe que você precisará ter o TensorFlow 1.3 ou anteriormente instalado, pois o TF1.4+ quebra o código original.
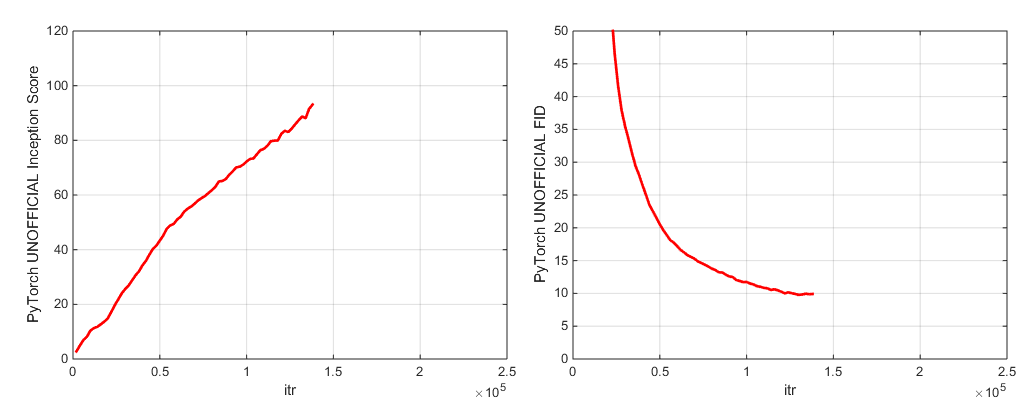 Incluímos dois pontos de verificação de modelo pré -terenciados (com G, D, a cópia EMA de G, os otimizadores e o ditado do estado):
Incluímos dois pontos de verificação de modelo pré -terenciados (com G, D, a cópia EMA de G, os otimizadores e o ditado do estado):
Modelos pré-criados para lugares-365 em breve.
Este repositório também contém scripts para portar os pesos originais do TFHub Biggan Generator para Pytorch. Veja os scripts na pasta TFHUB para obter mais detalhes.

Se você deseja retomar o treinamento interrompido ou ajustar um modelo pré-treinado, execute o mesmo script de lançamento, mas com o argumento --resume adicionado. Os nomes dos experimentos são gerados automaticamente a partir da configuração, mas podem ser substituídos usando o --experiment_name arg (por exemplo, se você deseja ajustar um modelo usando configurações de otimizador modificado).
Para preparar seu próprio conjunto de dados, você precisará adicioná -lo ao DataSets.py e modificar os ditos de conveniência no utils.py (dset_dict, imsize_dict, root_dict, ncllass_dict, classes_per_sheet_dict) para ter o metadata apropriado para o seu datásico. Repita o processo em preparar_data.sh (opcionalmente, produz uma cópia pré -processada HDF5 e calcule os momentos de início para FID).
Por padrão, o script de treinamento salvará os 5 melhores pontos de verificação, conforme medido pela pontuação inicial. Para os conjuntos de dados que não sejam o ImageNet, a pontuação inicial pode ser uma medida muito ruim de qualidade; portanto, você provavelmente desejará usar --which_best FID .
Para usar sua própria função de treinamento (por exemplo, um bigvae): modifique o trep_fns.gan_training_function ou adicione um novo trem fn e adicione -o após a if config['which_train_fn'] == 'GAN': linha em train.py .
--num_G_SVs . Este código foi projetado desde o início para servir como uma base extensível e hackeable para um código de pesquisa adicional. Pensamos muito em garantir que as abstrações sejam a espessura certa para a pesquisa-não tão grossa que seja impenetrável, mas não tão fina que seja inútil. A idéia principal é que, se você deseja experimentar uma configuração do SOTA e fazer alguma modificação (experimente sua nova função de perda, arquitetura, bloco de auto-atendimento etc.), você poderá fazê-lo facilmente apenas soltando seu código em um ou dois lugares, sem ter que se preocupar com o restante da base de código. Coisas como o uso de self.which_conv e functools.parcial na definição do modelo biggan.py foram montadas juntas com isso em mente, assim como o design da herança da classe de norma espectral.
Com isso dito, esta é uma base de código um tanto grande para um único projeto. Enquanto tentamos ser minuciosos com os comentários, se houver algo que você acha que pode ser mais claro, melhor escrito ou melhor reformado, sinta -se à vontade para levantar um problema ou uma solicitação de tração.
Deseja trabalhar ou melhorar este código? Há algumas coisas pelas quais o repositório se beneficiaria, mas que ainda não funcionariam.
Veja este diretório para rótulos do ImageNet.
Se você usar este código, cite
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
Obrigado ao Google pelas generosas doações de crédito em nuvem.
Syncbn por Jiayuan Mao e Tete Xiao.
Barra de progresso originalmente de Jan Schlüter.
Teste métricas de logger da Voxnet.
Implementação de Pytorch do COV do Modar M. Alfadly.
Pytorch Fast Matrix Sqrt para Fid de Tsung-Yu Lin e Subhransu Maji.
Código de pontuação do TensorFlow Inception do Gan Melhorado do OpenAI.


