BigGAN PyTorch
1.0.0
Официально неофициальная реализация автора Биггана.

Этот репо содержит код для обучения Biggans 4-8 GPU из крупномасштабной тренировки Gan для синтеза естественного изображения с высокой точностью от Эндрю Брока, Джеффа Донахью и Карен Симоньян.
Этот код от Энди Брока и Алекса Андуна.
Вам понадобится:
Во-первых, вы можете при желании подготовить предварительно обработанную версию HDF5 вашего целевого набора данных для более быстрого ввода-вывода. После этого (или нет), вам понадобятся моменты создания, необходимые для расчета FID. Они могут быть сделаны путем изменения и запуска
sh scripts/utils/prepare_data.sh Который по умолчанию предполагает, что ваш учебный набор ImageNet загружается в data корневой папки в этом каталоге и подготовит кэшированный HDF5 с разрешением 128x128 пикселей.
В папке Scripts есть несколько сценариев Bash, которые будут обучать Biggans с разными размерами партии. Этот код предполагает, что у вас нет доступа к полному POD TPU, и, соответственно, подделывает мега-страницы, используя накопление градиента (усреднение выпускников по нескольким minibatches и выполнение только шага оптимизатора после накопления N). По умолчанию сценарий launch_BigGAN_bs256x8.sh обучает полноразмерную модель Biggan с размером партии 256 и 8 градиентных накоплений, для общего размера партии 2048 года. На 8xv100 с полной тренировкой (без тензовых ядер) этот скрипт занимает 15 дней до 150 тыс. Итераций.
Сначала вам нужно будет выяснить максимальный размер партии, который может поддержать ваша установка. Предварительно обученные модели, предоставленные здесь, прошли обучение на 8xv100 (16 ГБ VRAM каждый), что может поддерживать чуть больше, чем BS256, используемый по умолчанию. После того, как вы определите это, вы должны изменить сценарий так, чтобы размер пакета разгонялся, что количество накопления градиента равняется вашему общему размеру общего количества пакетов (по умолчанию Biggan до 2048 года).
Также обратите внимание, что в этом скрипте используется ARG --load_in_mem , который загружает весь файл (~ 64 ГБ) i128.hdf5 в ОЗУ для более быстрой загрузки данных. Если у вас недостаточно оперативной памяти, чтобы поддержать это (вероятно, 96 ГБ+), удалите этот аргумент.

Во время обучения этот скрипт будет выводить журналы с помощью обучающих метрик и метриков тестирования, сэкономит несколько копий (2 самых последних и 5 самых высоких баллов) весов/оптимизатора модели и будет производить образцы и интерполяции каждый раз, когда он спасает веса. Папка журналов содержит сценарии для обработки этих журналов и построить результаты с использованием Matlab (извините, не извините).
После обучения можно использовать sample.py для получения дополнительных выборок и интерполяций, тестировать с различными значениями усечения, размера партий, количеством скоплений постоянного статистики и т. Д. См. Сценарий sample_BigGAN_bs256x8.sh для примера.
По умолчанию все сохраняется в папках веса/образцов/журналов/данных, которые предполагаются в той же папке, что и в этом репо. Вы можете указать на все это на другую базовую папку, используя аргумент --base_root или выбрать конкретные местоположения для каждого из них с их соответствующими аргументами (например, --logs_root ).
Мы включаем сценарии, чтобы запустить Biggan-Deep, но мы не полностью обучили модель, используя их, поэтому считайте их непроверенными. Кроме того, мы включаем сценарии для запуска модели на CIFAR, а также для запуска SA-GAN (с EMA) и SN-GAN на ImageNet. Код SA-GAN предполагает, что у вас есть 4xTitanx (или эквивалентный с точки зрения оперативной памяти GPU) и будет работать с размером партии 128 и 2 градиентных накоплений.
В этом репо используется встроенная встроенная сеть Pytorch для расчета IS и FID. Эти оценки отличаются от результатов, которые вы получите, используя официальный код основания TF, и только для целей мониторинга! Запустите Sample.py на вашей модели, с аргументом --sample_npz , затем запустите incepation_tf13, чтобы вычислить фактический тензорфлоу. Обратите внимание, что вам потребуется установлен TensorFlow 1.3 или ранее, так как TF1.4+ Breaks Original - это код.
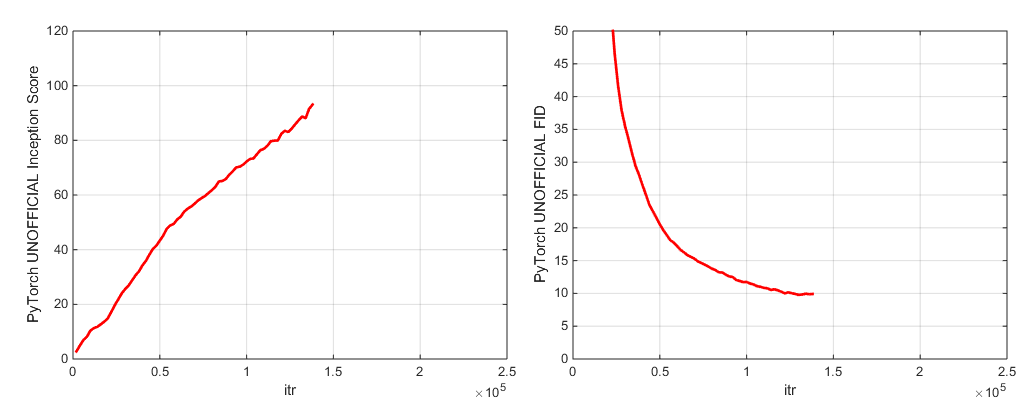 Мы включаем две предварительно проведенные модельные контрольно -пропускные пункты (с G, D, копия EMA G, оптимизаторы и DICT состояния):
Мы включаем две предварительно проведенные модельные контрольно -пропускные пункты (с G, D, копия EMA G, оптимизаторы и DICT состояния):
Предварительные модели для мест-365 скоро появятся.
Этот репо также содержит сценарии для переноса оригинальных весов генератора TFHUB Biggan в Pytorch. Смотрите сценарии в папке TFHUB для получения более подробной информации.

Если вы хотите возобновить прерванную тренировку или точно настроить предварительно обученную модель, запустите тот же сценарий запуска, но с добавленным аргументом --resume . Имена экспериментов автоматически генерируются из конфигурации, но могут быть переопределены с использованием arg --experiment_name (например, если вы хотите точно настроить модель, используя модифицированные настройки оптимизатора).
Чтобы подготовить свой собственный набор данных, вам нужно будет добавить его в наборы данных. Повторите процесс в Prepare_Data.SH (необязательно создайте предварительную копию HDF5 и рассчитайте моменты основания для FID).
По умолчанию учебный скрипт сохранит 5 лучших лучших контрольных точек, измеренных по баллу «Начало». Для наборов данных, отличных от ImageNet, оценка начала может быть очень плохим показателем качества, поэтому вы, вероятно, захотите использовать --which_best FID .
Чтобы использовать свою собственную обучающую функцию (например, обучение Bigvae): либо измените Train_fns.gan_training_function, либо добавьте новый поезд FN и добавьте его после if config['which_train_fn'] == 'GAN': line in train.py .
--num_G_SVs . Этот код разработан с нуля, чтобы служить расширяемой, взломанной базой для дальнейшего кода исследования. Мы задумались о том, чтобы убедиться, что абстракции являются правильной толщиной для исследований-не настолько толстые, чтобы быть непроницаемыми, но не настолько тонкими, чтобы быть бесполезными. Ключевая идея заключается в том, что если вы хотите экспериментировать с настройкой SOTA и внести некоторую модификацию (попробуйте свою собственную новую функцию потерь, архитектуру, блок самостоятельного прихода и т. Д.) Вы должны легко сделать это, просто сбросив свой код в одном или двух местах, не беспокоясь об остальной части базы кода. Такие вещи, как использование Self.which_conv и functools.partial в определении модели biggan.py, были собраны с учетом этого, как и дизайн наследства класса спектральной нормы.
С учетом сказанного, это несколько большая кодовая база для одного проекта. Хотя мы старались быть тщательными с комментариями, если есть что -то, что, по вашему мнению, может быть более ясным, лучше написанным или лучше, пожалуйста, не стесняйтесь поднять проблему или запрос на тягу.
Хотите поработать или улучшить этот код? Есть несколько вещей, от которых это репо выиграет, но которые еще не работают.
Смотрите этот каталог для ярлыков ImageNet.
Если вы используете этот код, пожалуйста, цитируйте
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
Спасибо Google за щедрые пожертвования в облачных кредитах.
Syncbn от Jiayuan Mao и Tete Xiao.
Прогресс Бар родом из Яна Шлютера.
Регистратор тестовых метрик от Voxnet.
Реализация Pytorch COV от Modar M. Alfadly.
Pytorch Fast Matrix SQRT для FID от Tsung-Yu Lin и Subhransu Maji.
Tensorflow Начало код сцены от Openai усовершенствовано.


