BigGAN PyTorch
1.0.0
La implementación oficialmente no oficial de Pytorch Biggan del autor.

Este repositorio contiene código para el entrenamiento de 4-8 GPU de grandes del entrenamiento de GaN a gran escala para la síntesis de imágenes naturales de alta fidelidad de Andrew Brock, Jeff Donahue y Karen Simonyan.
Este código es de Andy Brock y Alex Andonian.
Necesitarás:
Primero, opcionalmente puede preparar una versión HDF5 preprocesada de su conjunto de datos de destino para E/S más rápidas. Después de esto (o no), necesitará los momentos de inicio necesarios para calcular FID. Ambos se pueden hacer modificando y ejecutando
sh scripts/utils/prepare_data.sh Que, por defecto, supone que su conjunto de capacitación ImageNet se descarga en los data de la carpeta raíz en este directorio, y preparará el HDF5 en caché a la resolución de 128x128 píxeles.
En la carpeta de scripts, hay múltiples scripts bash que entrenarán grandes con diferentes tamaños de lotes. Este código supone que no tiene acceso a una POD TPU completa y, en consecuencia, falsifica los mega lotes mediante el uso de la acumulación de gradiente (promediando graduados en múltiples minibatches, y solo da un paso optimizador después de las n acumulaciones). De manera predeterminada, el script launch_BigGAN_bs256x8.sh entrena un modelo Biggan de tamaño completo con un tamaño de lote de acumulaciones de gradiente 256 y 8, para un tamaño total de lotes de 2048. En 8XV100 con capacitación de precisión completa (sin núcleos de tensor), este script lleva 15 días a capacitar a 150k iteraciones.
Primero deberá averiguar el tamaño máximo de lotes que su configuración puede admitir. Los modelos previamente capacitados proporcionados aquí fueron capacitados en 8XV100 (16 GB de VRAM cada uno), lo que puede admitir un poco más que el BS256 utilizado por defecto. Una vez que haya determinado esto, debe modificar el script para que el tamaño de lote sea el número de acumulaciones de gradiente sea igual al tamaño total de lotes deseado (Biggan predeterminada a 2048).
Tenga en cuenta también que este script usa el archivo --load_in_mem arg, que carga el archivo completo (~ 64GB) i128.hdf5 en RAM para una carga de datos más rápida. Si no tiene suficiente RAM para admitir esto (probablemente 96GB+), elimine este argumento.

Durante el entrenamiento, este script generará registros con métricas de entrenamiento y métricas de prueba, ahorrará múltiples copias (2 más recientes y 5 de puntuación más alta) de los pesos del modelo/parámetros de optimizador, y producirá muestras e interpolaciones cada vez que guarde pesos. La carpeta de registros contiene scripts para procesar estos registros y trazar los resultados usando MATLAB (lo siento, no lo siento).
Después del entrenamiento, se puede usar sample.py para producir muestras e interpolaciones adicionales, probar con diferentes valores de truncamiento, tamaños de lotes, número de acumulaciones de estadísticas de pie, etc. Consulte el script sample_BigGAN_bs256x8.sh para un ejemplo.
Por defecto, todo se guarda en pesas/muestras/registros/carpetas de datos que se supone que están en la misma carpeta que este repositorio. Puede señalar todo esto a una carpeta base diferente utilizando el argumento --base_root , o elegir ubicaciones específicas para cada uno de estos con sus respectivos argumentos (por ejemplo, --logs_root ).
Incluimos scripts para ejecutar Biggan-DepeP, pero no hemos entrenado completamente un modelo que los use, así que considéralos no probados. Además, incluimos scripts para ejecutar un modelo en CIFAR y ejecutar SA-Gan (con EMA) y SN-Gan en Imagenet. El código SA-Gan supone que tiene 4Xtitanx (o equivalente en términos de RAM GPU) y se ejecutará con un tamaño de lote de 128 y 2 acumulaciones de gradiente.
Este repositorio utiliza la red de inicio incorporada de Pytorch para calcular IS y FID. ¡Estos puntajes son diferentes de los puntajes que obtendría utilizando el código oficial de inicio de TF, y solo son para fines de monitoreo! Ejecute sample.py en su modelo, con el argumento --sample_npz , luego ejecute Inception_TF13 para calcular el flujo de tensor real es. Tenga en cuenta que necesitará instalarse TensorFlow 1.3 o anteriormente, ya que TF1.4+ rompe el código original es.
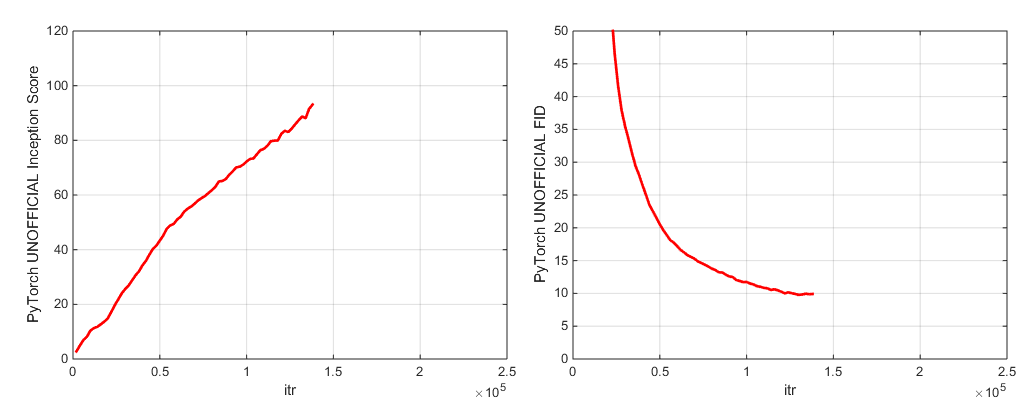 Incluimos dos puntos de control modelo previos a la aparición (con G, D, la copia EMA de G, los optimizadores y el estado de estado):
Incluimos dos puntos de control modelo previos a la aparición (con G, D, la copia EMA de G, los optimizadores y el estado de estado):
Modelos previos a los lugares para lugares-365 próximamente.
Este repositorio también contiene scripts para portar los pesos originales del generador TFHUB Biggan a Pytorch. Vea los scripts en la carpeta TFHUB para obtener más detalles.

Si desea reanudar el entrenamiento interrumpido o ajustar un modelo previamente capacitado, ejecute el mismo script de lanzamiento pero con el argumento --resume agregado. Los nombres de los experimentos se generan automáticamente a partir de la configuración, pero se pueden anular utilizando el --experiment_name Arg (por ejemplo, si desea ajustar un modelo utilizando configuraciones modificadas de optimizador).
Para preparar su propio conjunto de datos, deberá agregarlo a DataSets.py y modificar los dicts de conveniencia en utils.py (dset_dict, imsize_dict, root_dict, nclass_dict, classes_per_sheet_dict) para tener los metadatos apropiados para su datos. Repita el proceso en prepare_data.sh (opcionalmente produce una copia preprocesada de HDF5 y calcule los momentos de inicio para FID).
Por defecto, el script de entrenamiento guardará los 5 mejores puntos de control medidos por la puntuación de inicio. Para conjuntos de datos que no sean Imagenet, la puntuación de inicio puede ser una medida de calidad muy pobre, por lo que es probable que desee usar --which_best FID en su lugar.
Para usar su propia función de entrenamiento (por ejemplo, Train A BigVae): Modifique Train_FNS.GAN_TRINING_FUNCTION o agregue un nuevo tren FN y agregue después de la if config['which_train_fn'] == 'GAN': Line in train.py .
--num_G_SVs . Este código está diseñado desde cero para servir como una base extensible y hackable para un código de investigación adicional. Hemos pensado mucho en asegurarnos de que las abstracciones sean el grosor correcto para la investigación, no tan gruesos como para ser impenetrables, pero no tan delgados como para ser inútiles. La idea clave es que si desea experimentar con una configuración de SOTA y hacer alguna modificación (pruebe su propia función de pérdida, arquitectura, bloqueo de autoatición, etc.), debería poder hacerlo fácilmente simplemente dejando caer su código en uno o dos lugares, sin tener que preocuparse por el resto de la base de código. Cosas como el uso de self.shch_conv y FunccTools.Partial in the Biggan.py Definición del modelo se pusieron en mente con esto, al igual que el diseño de la herencia de clase de norma espectral.
Dicho esto, esta es una base de código algo grande para un solo proyecto. Si bien tratamos de ser minuciosos con los comentarios, si hay algo que cree que podría ser más claro, mejor escrito o mejor refactorizado, no dude en plantear un problema o una solicitud de extracción.
¿Quieres trabajar o mejorar este código? Hay un par de cosas de las que se beneficiaría este repositorio, pero que aún no funcionan.
Vea este directorio para las etiquetas de ImageNet.
Si usa este código, por favor cita
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
Gracias a Google por las generosas donaciones de crédito en la nube.
Syncbn por Jiayuan Mao y Tete Xiao.
Progress Bar originaria de Jan Schlüter.
Pruebe el registrador de métricas desde Voxnet.
Implementación de Pytorch de CoV de Modar M. Alfadly.
Pytorch Fast Matrix SQRT para FID de Tsung-yu Lin y Subhransu Maji.
TensorFlow Inception Code de puntaje de OpenAI's mejorado.


