BigGAN PyTorch
1.0.0
L'auteur est officiellement non officiel de la mise en œuvre de Pytorch Biggan.

Ce dépôt contient du code pour la formation GPU 4-8 des Biggans à partir de la formation GAN à grande échelle pour la synthèse d'image naturelle haute fidélité par Andrew Brock, Jeff Donahue et Karen Simonyan.
Ce code est par Andy Brock et Alex Andonian.
Vous aurez besoin:
Tout d'abord, vous pouvez éventuellement préparer une version HDF5 prétraitée de votre ensemble de données cible pour des E / S plus rapides. Après cela (ou non), vous aurez besoin des moments de création nécessaires pour calculer le FID. Ceux-ci peuvent tous deux être faits en modifiant et en fonctionnant
sh scripts/utils/prepare_data.sh Ce qui suppose par défaut que votre ensemble de formation ImageNet est téléchargé dans les data du dossier racine dans ce répertoire, et préparera le HDF5 en cache à une résolution de 128x128 pixels.
Dans le dossier des scripts, il existe plusieurs scripts bash qui entraîneront des biggans avec différentes tailles de lots. Ce code suppose que vous n'avez pas accès à un pod TPU complet, et en conséquence, usurre les méga-lots en utilisant l'accumulation de gradient (en moyenne des diplômés sur plusieurs minibatchs, et en faisant uniquement une étape d'optimiseur après les accumulations N). Par défaut, le script launch_BigGAN_bs256x8.sh forme un modèle de grande taille avec une taille de lot de 256 et 8 accumulations de gradient, pour une taille totale de lots de 2048. Sur 8xv100 avec une formation complète (pas de noyaux de tension), ce script met 15 jours pour s'entraîner à 150k.
Vous devrez d'abord déterminer la taille maximale du lot que votre configuration peut prendre en charge. Les modèles pré-formés fournis ici ont été formés sur 8xv100 (16 Go de VRAM chacun) qui peuvent prendre en charge un peu plus que le BS256 utilisé par défaut. Une fois que vous avez déterminé cela, vous devez modifier le script de sorte que la taille du lot met en période le nombre d'accumulations de gradient est égale à la taille totale du lot souhaitée (Biggan par défaut est à 2048).
Notez également que ce script utilise l'Arg --load_in_mem , qui charge l'intégralité du fichier (~ 64 Go) i128.hdf5 dans RAM pour un chargement de données plus rapide. Si vous n'avez pas assez de RAM pour soutenir cela (probablement 96 Go +), supprimez cet argument.

Pendant la formation, ce script sortira des journaux avec des mesures d'entraînement et des mesures de test, économisera plusieurs copies (2 les plus récentes et 5 les plus élevées) des poids de poids / paramètres d'optimiseur, et produira des échantillons et des interpolations chaque fois qu'il économise des poids. Le dossier des journaux contient des scripts pour traiter ces journaux et tracer les résultats à l'aide de MATLAB (désolé pas désolé).
Après la formation, on peut utiliser sample.py pour produire des échantillons et des interpolations supplémentaires, tester avec différentes valeurs de troncature, tailles de lots, nombre d'accumulations de statistiques debout, etc. Voir l' sample_BigGAN_bs256x8.sh Script pour un exemple.
Par défaut, tout est enregistré sur des poids / échantillons / journaux / dossiers de données qui sont supposés être dans le même dossier que ce dépôt. Vous pouvez pointer tous ces éléments vers un dossier de base différent en utilisant l'argument --base_root , ou choisir des emplacements spécifiques pour chacun de ceux-ci avec leurs arguments respectifs (par exemple --logs_root ).
Nous incluons des scripts pour gérer Biggan-Deep, mais nous n'avons pas entièrement formé un modèle en les utilisant, alors considérons-les non testés. De plus, nous incluons des scripts pour exécuter un modèle sur CIFAR et pour exécuter SA-Gan (avec EMA) et SN-GAN sur ImageNet. Le code SA-GAN suppose que vous avez 4xtitanx (ou équivalent en termes de RAM GPU) et que vous fonctionnera avec une taille de lot de 128 et 2 accumulations de gradient.
Ce référentiel utilise le réseau de création de Pytorch intégré à calculer l'IS et FID. Ces scores sont différents des scores que vous obtiendriez en utilisant le code de création TF officiel et ne sont qu'à des fins de surveillance! Exécutez un exemple.py sur votre modèle, avec l'argument --sample_npz , puis exécutez INCECTION_TF13 pour calculer le TensorFlow réel est. Notez que vous devrez installer TensorFlow 1.3 ou précédent, car TF1.4 + casse l'original est le code.
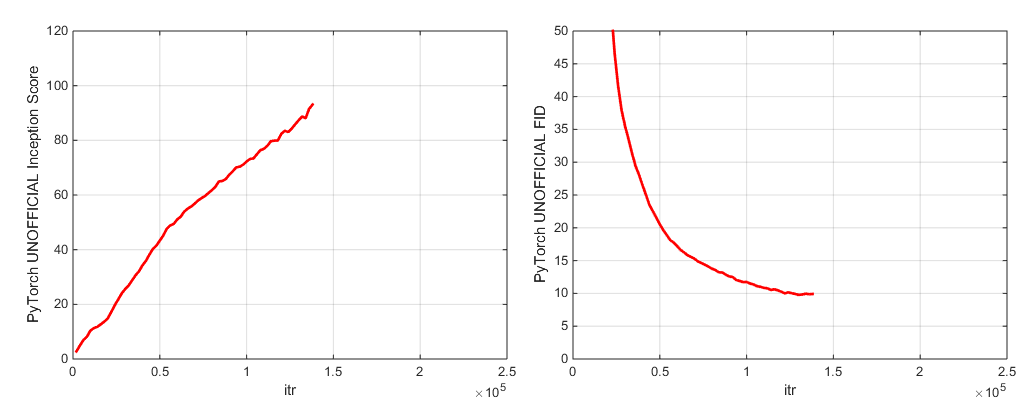 Nous incluons deux points de contrôle de modèle pré-entraînés (avec G, D, la copie EMA de G, The Optimizers et The State Dict):
Nous incluons deux points de contrôle de modèle pré-entraînés (avec G, D, la copie EMA de G, The Optimizers et The State Dict):
Modèles pré-entraînés pour les lieux-365 à venir bientôt.
Ce dépôt contient également des scripts pour le portage des poids du générateur TFHUB Biggan d'origine à Pytorch. Voir les scripts dans le dossier TFHUB pour plus de détails.

Si vous souhaitez reprendre une formation interrompue ou affiner un modèle pré-formé, exécutez le même script de lancement mais avec l'argument --resume ajouté. Les noms d'expérience sont automatiquement générés à partir de la configuration, mais peuvent être remplacés à l'aide du --experiment_name Arg (par exemple, si vous souhaitez affiner un modèle en utilisant des paramètres d'optimiseur modifiés).
Pour préparer votre propre ensemble de données, vous devrez l'ajouter à DataSets.py et modifier les dictions de commodité dans utils.py (dset_dict, imsize_dict, root_dict, nclass_dict, classes_per_sheet_dict) pour avoir les métadonnées appropriées pour votre ensemble de données. Répétez le processus dans préparent_data.sh (produisez éventuellement une copie prétraitée HDF5 et calculez les moments de création pour FID).
Par défaut, le script d'entraînement économisera les 5 meilleurs points de contrôle mesurés par le score de création. Pour les ensembles de données autres que ImageNet, le score de création peut être une très mauvaise mesure de la qualité, vous voudrez donc probablement utiliser --which_best FID à la place.
Pour utiliser votre propre fonction de formation (par exemple, entraînez-vous un bigvae): modifiez Train_Fns.gan_training_function ou ajoutez un nouveau train fn et ajoutez-le après la if config['which_train_fn'] == 'GAN': ligne dans train.py .
--num_G_SVs . Ce code est conçu à partir de zéro pour servir de base extensible et piratable pour un code de recherche plus approfondi. Nous avons beaucoup réfléchi à nous assurer que les abstractions sont la bonne épaisseur de recherche - pas si épaisses qu'elles sont impénétrables, mais pas si minces qu'elles sont inutiles. L'idée clé est que si vous souhaitez expérimenter une configuration SOTA et effectuer une modification (essayez votre propre nouvelle fonction de perte, architecture, bloc d'auto-agencement, etc.), vous devriez pouvoir le faire facilement simplement en supprimant votre code à un ou deux endroits, sans avoir à vous soucier du reste de la base de code. Des choses comme l'utilisation de Self.Which_conv et Functools.Partial dans la définition du modèle Biggan.py ont été conçues dans ce domaine, tout comme la conception de l'héritage de la classe norme spectrale.
Cela dit, il s'agit d'une base de code un peu grande pour un seul projet. Bien que nous ayons essayé d'être minutieux avec les commentaires, s'il y a quelque chose que vous pensez pourrait être plus clair, mieux écrit ou mieux refactorisé, n'hésitez pas à soulever un problème ou une demande de traction.
Vous voulez travailler ou améliorer ce code? Il y a quelques choses que ce dépôt bénéficierait, mais qui ne fonctionnent pas encore.
Voir ce répertoire pour les étiquettes ImageNet.
Si vous utilisez ce code, veuillez citer
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
Merci à Google pour les généreux dons de crédit cloud.
Syncbn par Jiayuan Mao et Tete Xiao.
Progress Bar originaire de Jan Schlüter.
Test des métriques Logger de VoxNet.
Pytorch Implémentation de CoV de Modar M. Alfadly.
Pytorch Fast Matrix SQRT pour FID de Tsung-Yu Lin et Subhransu Maji.
Tensorflow Inception Score Code de l'amélioration d'Openai.


