BigGAN PyTorch
1.0.0
Implementasi Pytorch Biggan yang secara resmi tidak resmi penulis.

Repo ini berisi kode untuk 4-8 pelatihan GPU Biggans dari pelatihan GAN skala besar untuk sintesis gambar alami kesetiaan tinggi oleh Andrew Brock, Jeff Donahue, dan Karen Simonyan.
Kode ini oleh Andy Brock dan Alex Andonian.
Anda akan membutuhkan:
Pertama, Anda dapat secara opsional menyiapkan versi HDF5 yang telah diproses dari dataset target Anda untuk I/O yang lebih cepat. Mengikuti ini (atau tidak), Anda akan membutuhkan momen awal yang diperlukan untuk menghitung FID. Keduanya dapat dilakukan dengan memodifikasi dan menjalankan
sh scripts/utils/prepare_data.sh Yang secara default mengasumsikan set pelatihan Imagenet Anda diunduh ke dalam data folder root di direktori ini, dan akan menyiapkan HDF5 yang di -cache pada resolusi piksel 128x128.
Di folder skrip, ada beberapa skrip bash yang akan melatih Biggan dengan ukuran batch yang berbeda. Kode ini mengasumsikan Anda tidak memiliki akses ke pod TPU penuh, dan karenanya spoof mega-batch dengan menggunakan akumulasi gradien (rata-rata lulusan atas beberapa minibatch, dan hanya mengambil langkah pengoptimal setelah akumulasi N). Secara default, skrip launch_BigGAN_bs256x8.sh melatih model Biggan berukuran penuh dengan ukuran batch 256 dan 8 akumulasi gradien, dengan ukuran total 2048. Pada 8XV100 dengan pelatihan presisi penuh (tanpa inti tensor), skrip ini membutuhkan waktu 15 hari untuk melatih hingga 150k iteration.
Pertama -tama Anda perlu mencari tahu ukuran batch maksimum yang dapat didukung oleh pengaturan Anda. Model pra-terlatih yang disediakan di sini dilatih pada 8XV100 (masing-masing 16GB VRAM) yang dapat mendukung sedikit lebih banyak daripada BS256 yang digunakan secara default. Setelah Anda menentukan ini, Anda harus memodifikasi skrip sehingga ukuran batch kali jumlah akumulasi gradien sama dengan ukuran total batch yang Anda inginkan (Biggan default hingga 2048).
Perhatikan juga bahwa skrip ini menggunakan arg --load_in_mem , yang memuat seluruh file (~ 64GB) i128.hdf5 ke dalam RAM untuk pemuatan data yang lebih cepat. Jika Anda tidak memiliki cukup RAM untuk mendukung ini (mungkin 96GB+), hapus argumen ini.

Selama pelatihan, skrip ini akan menghasilkan log dengan metrik pelatihan dan metrik uji, akan menyimpan banyak salinan (2 yang paling baru dan 5 skor tertinggi) dari model bobot/pengoptimal param, dan akan menghasilkan sampel dan interpolasi setiap kali menghemat bobot. Folder log berisi skrip untuk memproses log ini dan memplot hasil menggunakan MATLAB (maaf tidak maaf).
Setelah pelatihan, seseorang dapat menggunakan sample.py untuk menghasilkan sampel dan interpolasi tambahan, tes dengan nilai pemotongan yang berbeda, ukuran batch, jumlah akumulasi stat standing, dll. Lihat skrip sample_BigGAN_bs256x8.sh untuk contoh.
Secara default, semuanya disimpan ke bobot/sampel/log/folder data yang diasumsikan berada di folder yang sama dengan repo ini. Anda dapat mengarahkan semua ini ke folder dasar yang berbeda menggunakan argumen --base_root , atau memilih lokasi tertentu untuk masing -masing dengan argumen masing -masing (misalnya --logs_root ).
Kami menyertakan skrip untuk menjalankan Biggan-Deep, tetapi kami belum sepenuhnya melatih model menggunakannya, jadi anggap mereka belum teruji. Selain itu, kami menyertakan skrip untuk menjalankan model di CIFAR, dan untuk menjalankan Sa-Gan (dengan EMA) dan SN-GAN di ImageNet. Kode SA-GAN mengasumsikan Anda memiliki 4xTitanx (atau setara dalam hal RAM GPU) dan akan berjalan dengan ukuran batch 128 dan 2 akumulasi gradien.
Repo ini menggunakan jaringan awal pytorch in-built untuk menghitung dan FID. Skor ini berbeda dari skor yang akan Anda dapatkan menggunakan kode awal TF resmi, dan hanya untuk tujuan pemantauan! Jalankan sampel.py pada model Anda, dengan argumen --sample_npz , kemudian jalankan insteption_tf13 untuk menghitung TensorFlow yang sebenarnya adalah. Perhatikan bahwa Anda perlu memiliki TensorFlow 1.3 atau yang diinstal sebelumnya, karena TF1.4+ merusak kode IS asli.
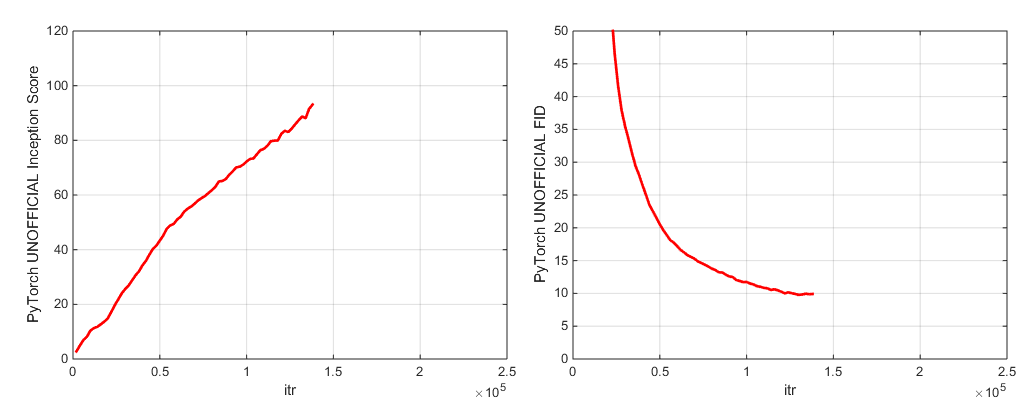 Kami menyertakan dua pos pemeriksaan model pretrained (dengan G, D, salinan EMA dari G, Optimizers, dan Dikt Negara):
Kami menyertakan dua pos pemeriksaan model pretrained (dengan G, D, salinan EMA dari G, Optimizers, dan Dikt Negara):
Model pretrained untuk tempat-365 segera hadir.
Repo ini juga berisi skrip untuk porting bobot generator TFHUB Biggan asli ke Pytorch. Lihat skrip di folder TFHUB untuk lebih jelasnya.

Jika Anda ingin melanjutkan pelatihan yang terputus atau menyempurnakan model pra-terlatih, jalankan skrip peluncuran yang sama tetapi dengan argumen --resume ditambahkan. Nama percobaan secara otomatis dihasilkan dari konfigurasi, tetapi dapat diganti menggunakan arg --experiment_name (misalnya, jika Anda ingin menyempurnakan model menggunakan pengaturan pengoptimal yang dimodifikasi).
Untuk menyiapkan dataset Anda sendiri, Anda perlu menambahkannya ke datasets.py dan memodifikasi diktsing kenyamanan di utils.py (dset_dict, imsize_dict, root_dict, nclass_dict, class_per_sheet_dict) untuk memiliki metadata yang sesuai untuk dataset Anda. Ulangi prosesnya dalam prepared_data.sh (secara opsional menghasilkan salinan HDF5 preprosesed, dan menghitung momen awal untuk FID).
Secara default, skrip pelatihan akan menyimpan 5 pos pemeriksaan terbaik teratas yang diukur dengan skor awal. Untuk set data selain Imagenet, skor awal dapat menjadi ukuran kualitas yang sangat buruk, jadi Anda mungkin ingin menggunakan --which_best FID .
Untuk menggunakan fungsi pelatihan Anda sendiri (misalnya melatih bigvae): Baik memodifikasi train_fns.gan_training_function atau menambahkan kereta baru FN dan menambahkannya setelah if config['which_train_fn'] == 'GAN': baris di train.py .
--num_G_SVs . Kode ini dirancang dari bawah ke atas untuk berfungsi sebagai basis yang dapat diperluas dan dapat diretas untuk kode penelitian lebih lanjut. Kami telah menempatkan banyak pemikiran untuk memastikan abstraksi adalah ketebalan yang tepat untuk penelitian-tidak begitu tebal sehingga tidak bisa ditembus, tetapi tidak terlalu tipis sehingga tidak berguna. Gagasan kuncinya adalah bahwa jika Anda ingin bereksperimen dengan pengaturan SOTA dan membuat beberapa modifikasi (cobalah fungsi kerugian baru Anda sendiri, arsitektur, blok perhatian diri, dll) Anda harus dapat dengan mudah melakukannya hanya dengan menjatuhkan kode Anda di satu atau dua tempat, tanpa harus khawatir tentang basis kode lainnya. Hal -hal seperti penggunaan diri. Yang mana dan functools.partial dalam definisi model Biggan.py disatukan dengan ini, seperti halnya desain warisan kelas norma spektral.
Dengan itu, ini adalah basis kode yang agak besar untuk satu proyek. Sementara kami mencoba untuk menyeluruh dengan komentar, jika ada sesuatu yang menurut Anda bisa lebih jelas, lebih baik ditulis, atau lebih baik refactored, jangan ragu untuk mengangkat masalah atau permintaan tarik.
Ingin mengerjakan atau meningkatkan kode ini? Ada beberapa hal yang akan diuntungkan oleh repo ini, tetapi yang belum berhasil.
Lihat Direktori ini untuk Label Imagenet.
Jika Anda menggunakan kode ini, silakan mengutip
@inproceedings{
brock2018large,
title={Large Scale {GAN} Training for High Fidelity Natural Image Synthesis},
author={Andrew Brock and Jeff Donahue and Karen Simonyan},
booktitle={International Conference on Learning Representations},
year={2019},
url={https://openreview.net/forum?id=B1xsqj09Fm},
}
Terima kasih kepada Google untuk sumbangan kredit cloud yang murah hati.
Syncbn oleh Jiayuan Mao dan Tete Xiao.
Progress Bar berasal dari Jan Schlüter.
Tes Metrics Logger dari Voxnet.
Implementasi Pytorch dari COV dari Modar M. Alfadly.
Pytorch Fast Matrix Sqrt untuk FID dari Tsung-yu Lin dan Subhransu Maji.
TensorFlow Inception Skor Code dari Openai's Exhip-Gan.


