Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
歡迎使用Bookshelf-Qabot,這是一個個人知識庫助理項目,旨在快速,準確地使用大語言模型的力量來簡化您對大量信息的訪問。該多功能工具非常適合研究人員,企業主和需要有效的信息管理的任何人。它的可擴展性使其非常適合希望增強其客戶服務能力的企業,從而對客戶查詢提供快速準確的響應。無論您是優化個人生產力還是提高業務運營,該項目都是為您量身定制的。
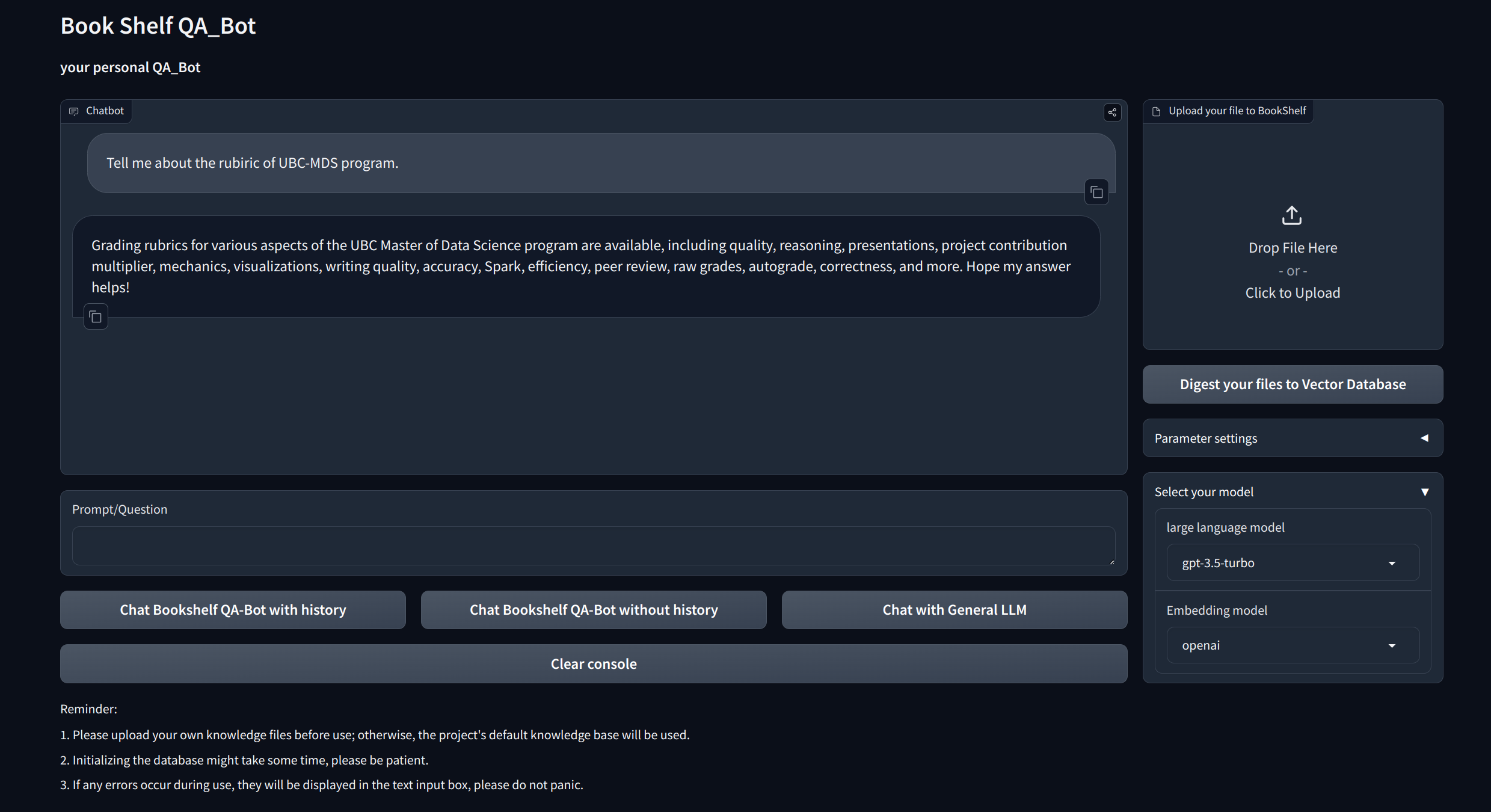
與抹布的交互式問答:利用檢索功能的生成(RAG)體系結構來促進動態和精確的問題回答。
可視化接口:通過FastApi通過Gradio和API提供易於啟動的接口,以啟動項目,演示問答和展示示例。
自定義知識管理:提供個性化選項,以根據您的喜好調整知識庫。用戶可以上傳和矢量化自己的凝結,以構建一個獨特的“書架”,該“書架”涉及某些特定領域的信息。
多模型兼容性:支持多個大型語言模型(LLM)(例如GPT-3.5,GPT4等)之間的無縫切換。這種靈活性使用戶可以為特定任務選擇最佳模型,從而優化準確性,響應速度和成本。
克隆並設置該項目:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txt設置API密鑰
從OpenAI獲取API鍵,並在root Directory下創建.ENV文件。複製並粘貼API字符串,並使用以下格式。
OPENAI_API_KEY= " you openai api key string "啟動本地API服務器:
cd app
uvicorn api:app --reload
或者您可以簡單地運行
bash app/run_api.sh
通過Gradio運行項目:
python app/run_gradio.py該項目利用基於大語言模型的全棧方法,該方法建立在蘭班框架上。核心技術包括LLM API呼叫,抹布,矢量數據庫和檢索問答鏈。該項目的整體架構如下:
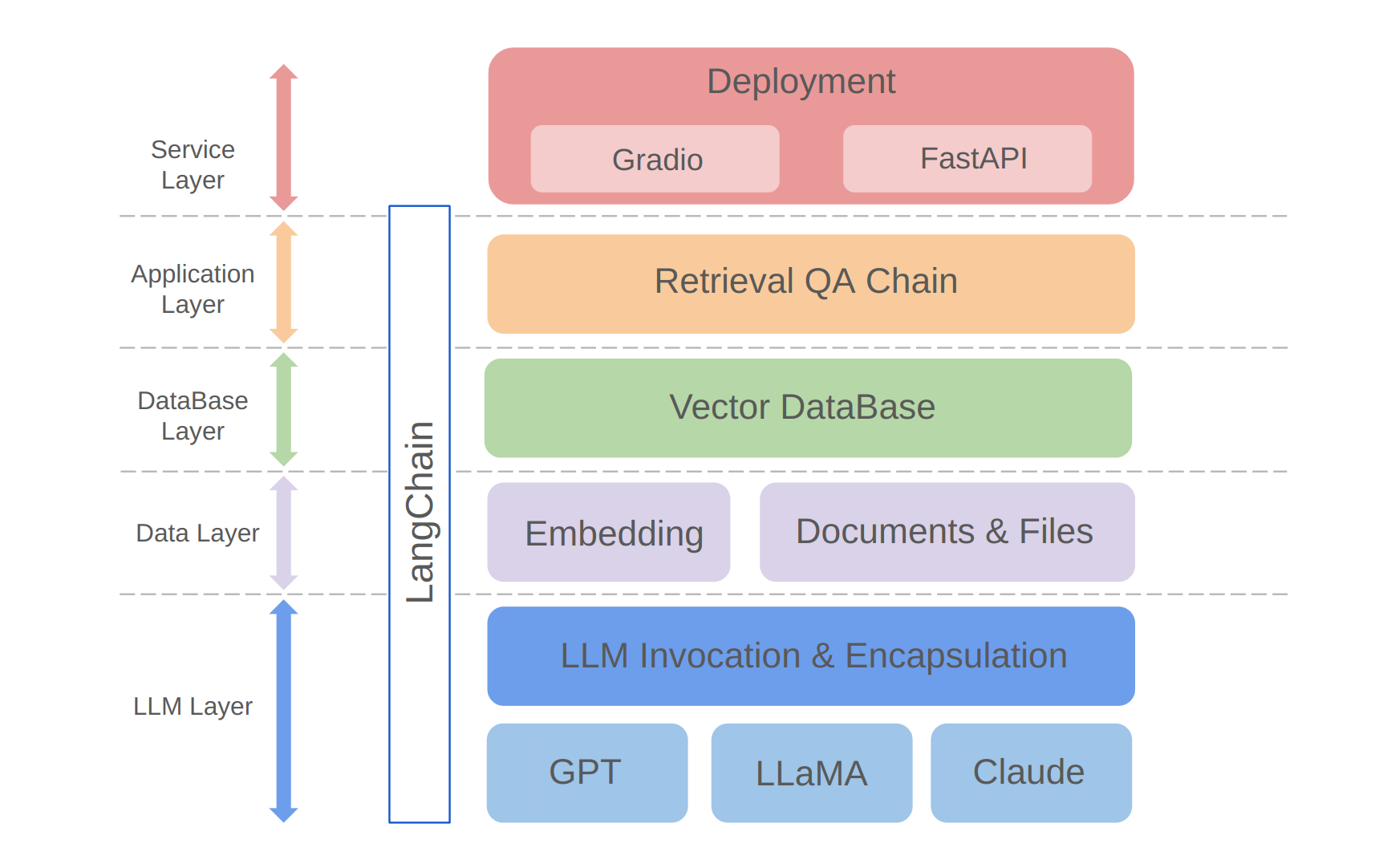
如上所示,該項目是從自下而上的LLM層,數據層,數據庫層,應用程序層和服務層構造的。
①LLM層主要涉及LLM的封裝,要求使用幾個流行的LLM API和型號,從而使用戶有一個統一的入口和訪問不同型號的方式,支持在線模型切換;
②數據層主要包括個人知識庫和嵌入API的源數據,在該數據庫中,嵌入處理後的源數據可以由矢量數據庫使用;
③數據庫層主要基於基於個人知識基源數據的向量數據庫,我在該項目中選擇了Chroma;
④應用程序層是核心功能的頂層封裝,我們根據Langchain提供的檢索問答鏈基類進一步封裝,從而支持不同的模型開關並促進基於數據庫的檢索Q&A的實現;
⑤頂層是服務層,在那裡我實施了Gradio來構建演示和FastApi來組裝API以支持項目的服務訪問。
感謝您對該項目的關注。我期待著您的貢獻,並了解如何使用它來增強信息管理和檢索任務,或將其擴展到客戶服務等業務應用程序!


