Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
Selamat datang di Bookshelf-Qabot, ini adalah proyek asisten basis pengetahuan pribadi, solusi RAG yang dirancang untuk merampingkan akses Anda ke sejumlah besar informasi dengan cepat dan akurat menggunakan kekuatan model bahasa besar. Alat serbaguna ini sangat cocok untuk para peneliti, pemilik bisnis, dan siapa pun yang membutuhkan manajemen informasi yang efisien. Skalabilitasnya membuatnya ideal untuk bisnis yang ingin meningkatkan kemampuan layanan pelanggan mereka, memberikan tanggapan yang cepat dan akurat terhadap pertanyaan pelanggan. Apakah Anda mengoptimalkan produktivitas individu atau meningkatkan operasi bisnis, proyek ini dirancang untuk Anda.
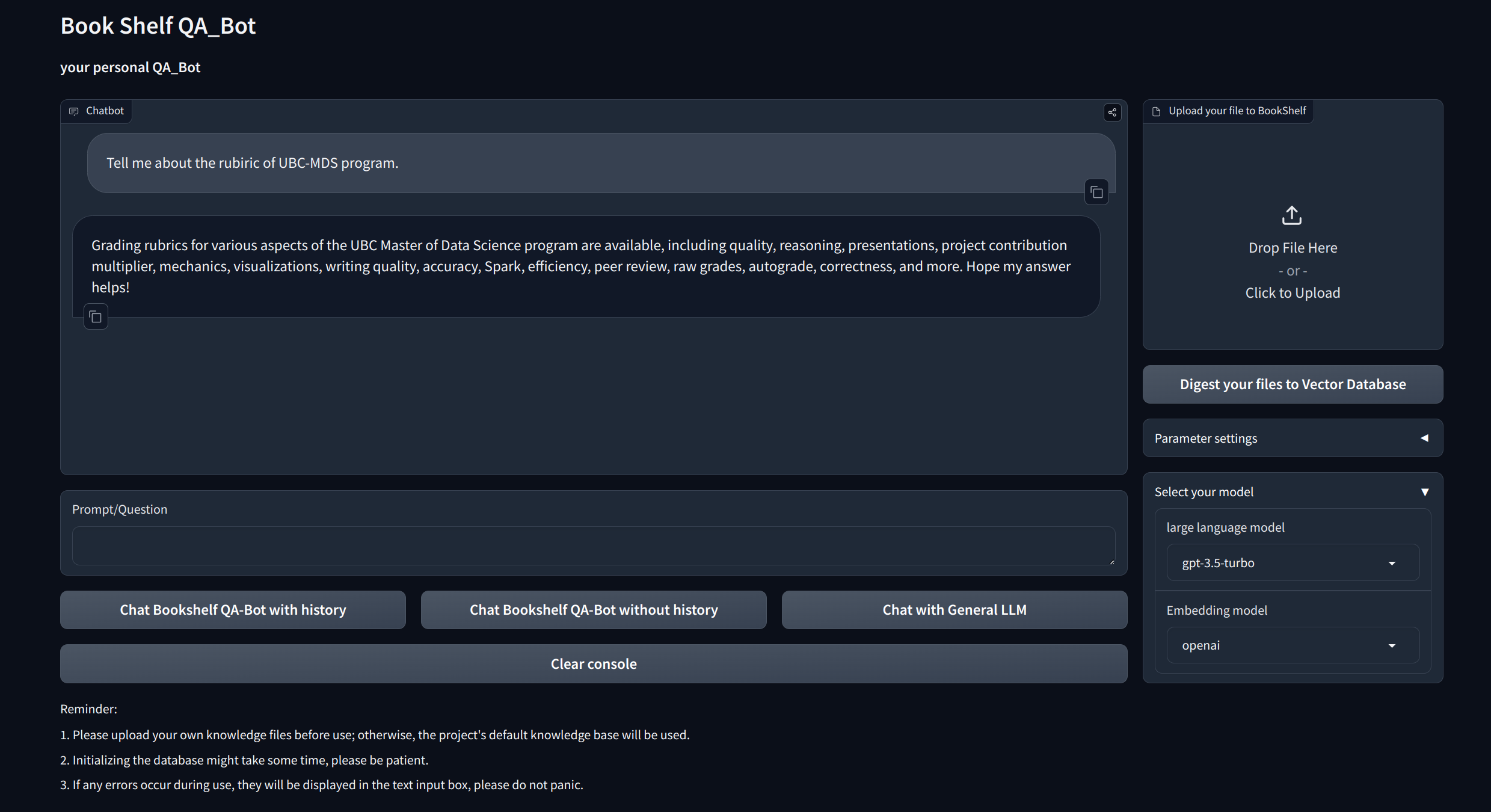
T&J interaktif dengan RAG : Leverage arsitektur generasi pengambilan (RAG) pengambilan untuk memfasilitasi penjawaban pertanyaan yang dinamis dan tepat.
Antarmuka Visualisasi : Menyediakan antarmuka yang mudah dinavigasi melalui Gradio dan API melalui FASTAPI untuk memulai proyek, menunjukkan tanya jawab, dan menampilkan contoh.
Manajemen Pengetahuan Kustomisasi : Menawarkan opsi personalisasi untuk menyesuaikan basis pengetahuan dengan preferensi Anda. Pengguna dapat mengunggah dan memvektorisasi ducoments mereka sendiri untuk membangun "rak buku" yang unik yang berhubungan dengan informasi khusus domain tertentu.
Kompatibilitas Multi-Model : Mendukung perpindahan mulus antara beberapa model bahasa besar (LLM) seperti GPT-3.5, GPT4, dan banyak lagi. Fleksibilitas ini memungkinkan pengguna untuk memilih model terbaik untuk tugas -tugas tertentu, mengoptimalkan akurasi, kecepatan dan biaya respons.
Klon dan atur proyek:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtAtur kunci API
Dapatkan Kunci API dari OpenAI, dan buat file .env di bawah direktori root. Salin dan tempel string API dengan format berikut.
OPENAI_API_KEY= " you openai api key string "Mulai server API lokal:
cd app
uvicorn api:app --reload
Atau Anda bisa berlari
bash app/run_api.sh
Jalankan proyek melalui gradio:
python app/run_gradio.pyProyek ini memanfaatkan pendekatan full-stack berdasarkan model bahasa besar, dibangun di atas kerangka kerja Langchain. Teknologi inti termasuk panggilan API LLM, RAG, database vektor, dan rantai T&J pengambilan. Arsitektur keseluruhan proyek ini adalah sebagai berikut:
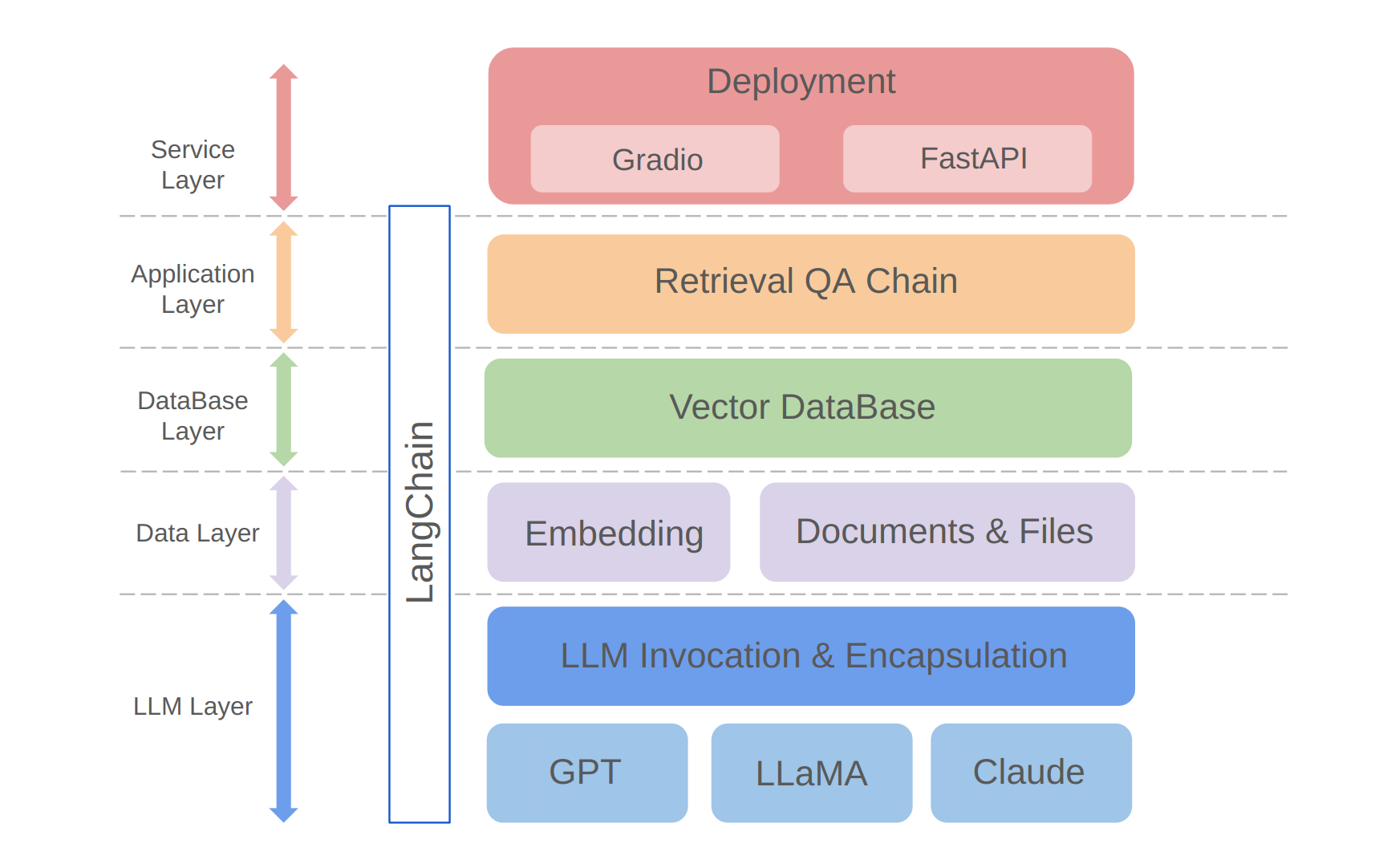
Seperti yang ditunjukkan di atas, proyek disusun dari bawah ke atas ke dalam lapisan LLM, lapisan data, lapisan basis data, lapisan aplikasi, dan lapisan layanan.
① Lapisan LLM terutama melibatkan enkapsulasi panggilan LLM untuk beberapa API dan model LLM yang populer, yang memungkinkan pengguna pintu masuk terpadu dan cara untuk mengakses model yang berbeda, mendukung pengalihan model on-the-fly;
② Lapisan data terutama mencakup data sumber dari basis pengetahuan pribadi dan API embedding, di mana data sumber setelah pemrosesan embedding dapat digunakan oleh database vektor;
③ Lapisan basis data terutama didasarkan pada database vektor yang dibangun di atas data sumber basis pengetahuan pribadi, yang saya pilih Chroma dalam proyek ini;
④ Lapisan aplikasi adalah enkapsulasi lapisan atas dari fungsi inti, di mana kami selanjutnya dienkapsulasi berdasarkan pengambilan kelas dasar rantai Q&A yang disediakan oleh Langchain, sehingga mendukung berbagai sakelar model dan memfasilitasi implementasi Q&A pengambilan berbasis database;
⑤ Lapisan atas adalah lapisan layanan, di mana saya menerapkan Gradio untuk membangun demo dan FASTAPI untuk mengumpulkan API untuk mendukung akses layanan proyek.
Terima kasih atas minat Anda pada proyek ini. Saya menantikan kontribusi Anda dan melihat bagaimana Anda akan menggunakannya untuk meningkatkan manajemen informasi Anda dan pengambilan tugas atau meningkatkannya untuk aplikasi bisnis seperti layanan pelanggan!


