Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
ยินดีต้อนรับสู่ Bookshelf-Qabot เป็นโครงการผู้ช่วยฐานความรู้ส่วนบุคคลโซลูชัน RAG ที่ออกแบบมาเพื่อปรับปรุงการเข้าถึงข้อมูลจำนวนมหาศาลของคุณอย่างรวดเร็วและแม่นยำโดยใช้พลังของแบบจำลองภาษาขนาดใหญ่ เครื่องมืออเนกประสงค์นี้เหมาะสำหรับนักวิจัยเจ้าของธุรกิจและทุกคนที่ต้องการการจัดการข้อมูลที่มีประสิทธิภาพ ความยืดหยุ่นของมันทำให้เหมาะสำหรับธุรกิจที่ต้องการเพิ่มขีดความสามารถในการบริการลูกค้าของพวกเขาให้การตอบกลับที่รวดเร็วและแม่นยำต่อการสอบถามข้อมูลของลูกค้า ไม่ว่าคุณจะเพิ่มประสิทธิภาพการทำงานของแต่ละบุคคลหรือเพิ่มการดำเนินงานทางธุรกิจโครงการนี้ได้รับการปรับแต่งสำหรับคุณ
คำถามและคำตอบแบบโต้ตอบกับ RAG : ใช้ประโยชน์จากสถาปัตยกรรมการดึง (RAG) เพื่ออำนวยความสะดวกในการตอบคำถามแบบไดนามิกและแม่นยำ
อินเทอร์เฟซการสร้างภาพข้อมูล : ให้อินเทอร์เฟซที่ง่ายต่อการนาเวทผ่าน Gradio และ API ผ่าน Fastapi สำหรับการเริ่มต้นโครงการแสดงให้เห็นถึงคำถามและคำตอบและการจัดแสดงตัวอย่าง
การจัดการความรู้ที่กำหนดเอง : เสนอตัวเลือกการปรับแต่งส่วนบุคคลเพื่อปรับฐานความรู้ให้ตรงกับความชอบของคุณ ผู้ใช้สามารถอัพโหลดและนำ vectorize ducoments ของตัวเองเพื่อสร้าง "ชั้นวางหนังสือ" ที่ไม่ซ้ำกันซึ่งเกี่ยวข้องกับข้อมูลเฉพาะโดเมนบางอย่าง
ความเข้ากันได้แบบหลายรูปแบบ : รองรับการสลับอย่างราบรื่นระหว่างแบบจำลองภาษาขนาดใหญ่หลายรุ่น (LLMS) เช่น GPT-3.5, GPT4 และอื่น ๆ ความยืดหยุ่นนี้ช่วยให้ผู้ใช้สามารถเลือกรุ่นที่ดีที่สุดสำหรับงานที่เฉพาะเจาะจงการเพิ่มประสิทธิภาพความแม่นยำความเร็วการตอบสนองและค่าใช้จ่าย
โคลนและตั้งค่าโครงการ:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtตั้งค่าคีย์ API
รับคีย์ API จาก OpenAI และสร้างไฟล์. ENV ภายใต้ไดเรกทอรีราก คัดลอกและวางสตริง API ด้วยรูปแบบต่อไปนี้
OPENAI_API_KEY= " you openai api key string "เริ่มเซิร์ฟเวอร์ API ในพื้นที่:
cd app
uvicorn api:app --reload
หรือคุณสามารถวิ่งได้
bash app/run_api.sh
เรียกใช้โครงการผ่าน Gradio:
python app/run_gradio.pyโครงการนี้ใช้ประโยชน์จากวิธีการเต็มรูปแบบตามแบบจำลองภาษาขนาดใหญ่ที่สร้างขึ้นบนกรอบ Langchain เทคโนโลยีหลักรวมถึงการโทร LLM API, RAG, ฐานข้อมูลเวกเตอร์และโซ่ตอบคำถาม สถาปัตยกรรมโดยรวมของโครงการมีดังนี้:
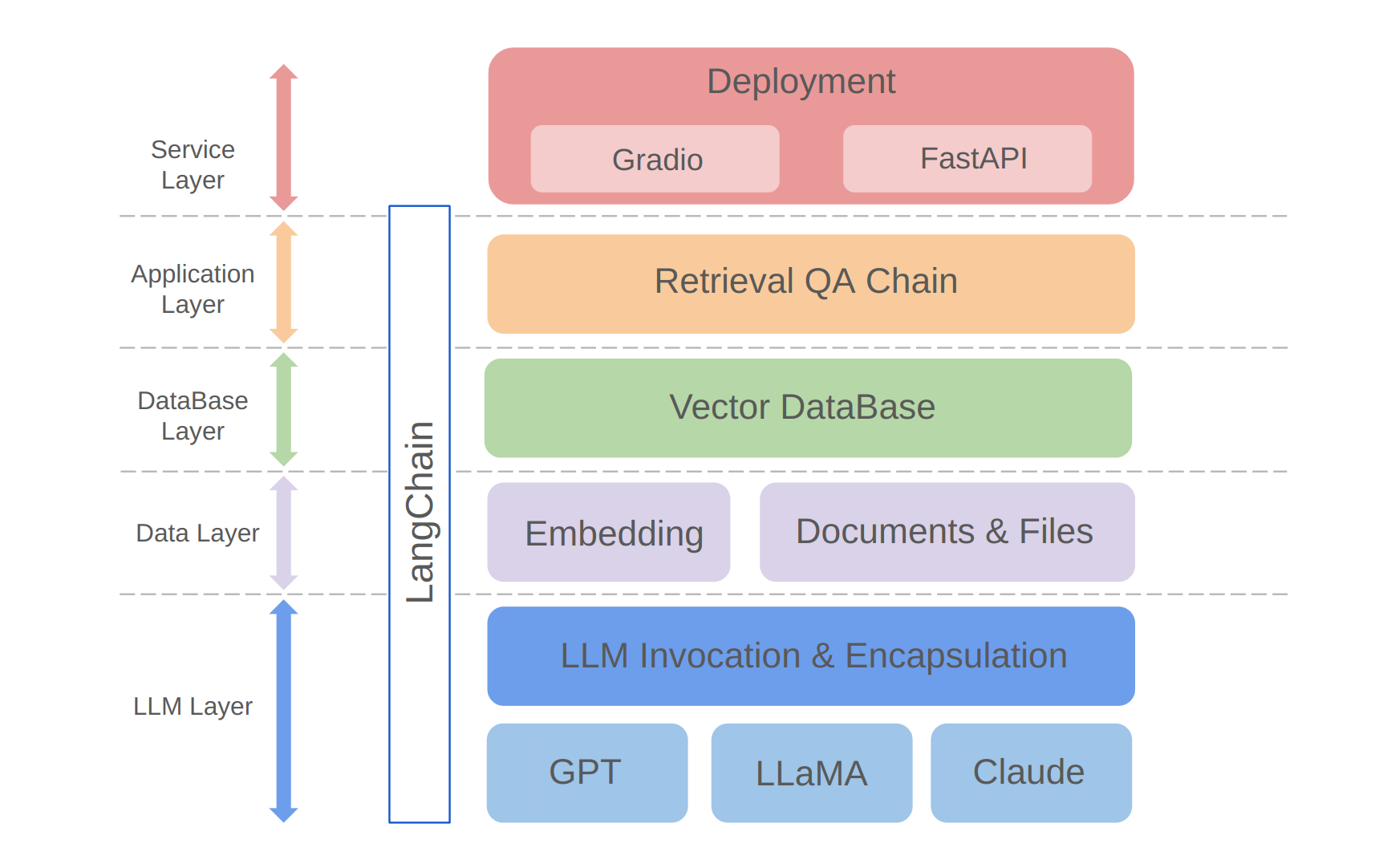
ดังที่แสดงไว้ข้างต้นโครงการมีโครงสร้างจากด้านล่างขึ้นไปสู่เลเยอร์ LLM, เลเยอร์ข้อมูล, เลเยอร์ฐานข้อมูล, เลเยอร์แอปพลิเคชันและเลเยอร์บริการ
①เลเยอร์ LLM ส่วนใหญ่เกี่ยวข้องกับการห่อหุ้มของ LLM เรียกร้องให้ LLM APIs และรุ่นยอดนิยมหลายรุ่นช่วยให้ผู้ใช้ทางเข้าแบบครบวงจรและวิธีการเข้าถึงรุ่นที่แตกต่างกันรองรับการสลับโมเดลแบบทันที
②ชั้นข้อมูลส่วนใหญ่จะรวมข้อมูลแหล่งที่มาของฐานความรู้ส่วนบุคคลและ API ฝังซึ่งข้อมูลแหล่งที่มาหลังจากการประมวลผลการฝังฐานข้อมูลสามารถใช้งานได้โดยฐานข้อมูลเวกเตอร์
③เลเยอร์ฐานข้อมูลส่วนใหญ่ขึ้นอยู่กับฐานข้อมูลเวกเตอร์ที่สร้างขึ้นบนข้อมูลแหล่งความรู้ส่วนบุคคลซึ่งฉันเลือก Chroma ในโครงการนี้
④เลเยอร์แอปพลิเคชันคือการห่อหุ้มชั้นบนสุดของฟังก์ชั่นหลักซึ่งเราห่อหุ้มต่อไปตามคลาสฐานโซ่ Q & A แบบดึงข้อมูลที่ได้รับจาก Langchain ซึ่งสนับสนุนสวิตช์โมเดลที่แตกต่างกัน
⑤ชั้นบนสุดคือเลเยอร์บริการที่ฉันใช้ gradio เพื่อสร้างการสาธิตและ fastapi เพื่อรวบรวม APIs เพื่อรองรับการเข้าถึงบริการของโครงการ
ขอขอบคุณสำหรับความสนใจในโครงการนี้ ฉันรอคอยที่จะมีส่วนร่วมของคุณและดูว่าคุณจะใช้มันเพื่อปรับปรุงการจัดการข้อมูลและการดึงงานของคุณหรือปรับขนาดสำหรับแอปพลิเคชันธุรกิจเช่นการบริการลูกค้า!


