Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
Bienvenido a Bookshelf-Qabot, es un proyecto de asistente de base de conocimiento personal, una solución de trapo diseñada para optimizar su acceso a grandes cantidades de información utilizando de manera rápida y precisa el poder de los modelos de idiomas grandes. Esta herramienta versátil es perfecta para investigadores, dueños de negocios y cualquier persona que necesite una gestión eficiente de la información. Su escalabilidad lo hace ideal para empresas que buscan mejorar sus capacidades de servicio al cliente, proporcionando respuestas rápidas y precisas a las consultas de los clientes. Ya sea que esté optimizando la productividad individual o mejorando una operación comercial, este proyecto se adapta a usted.
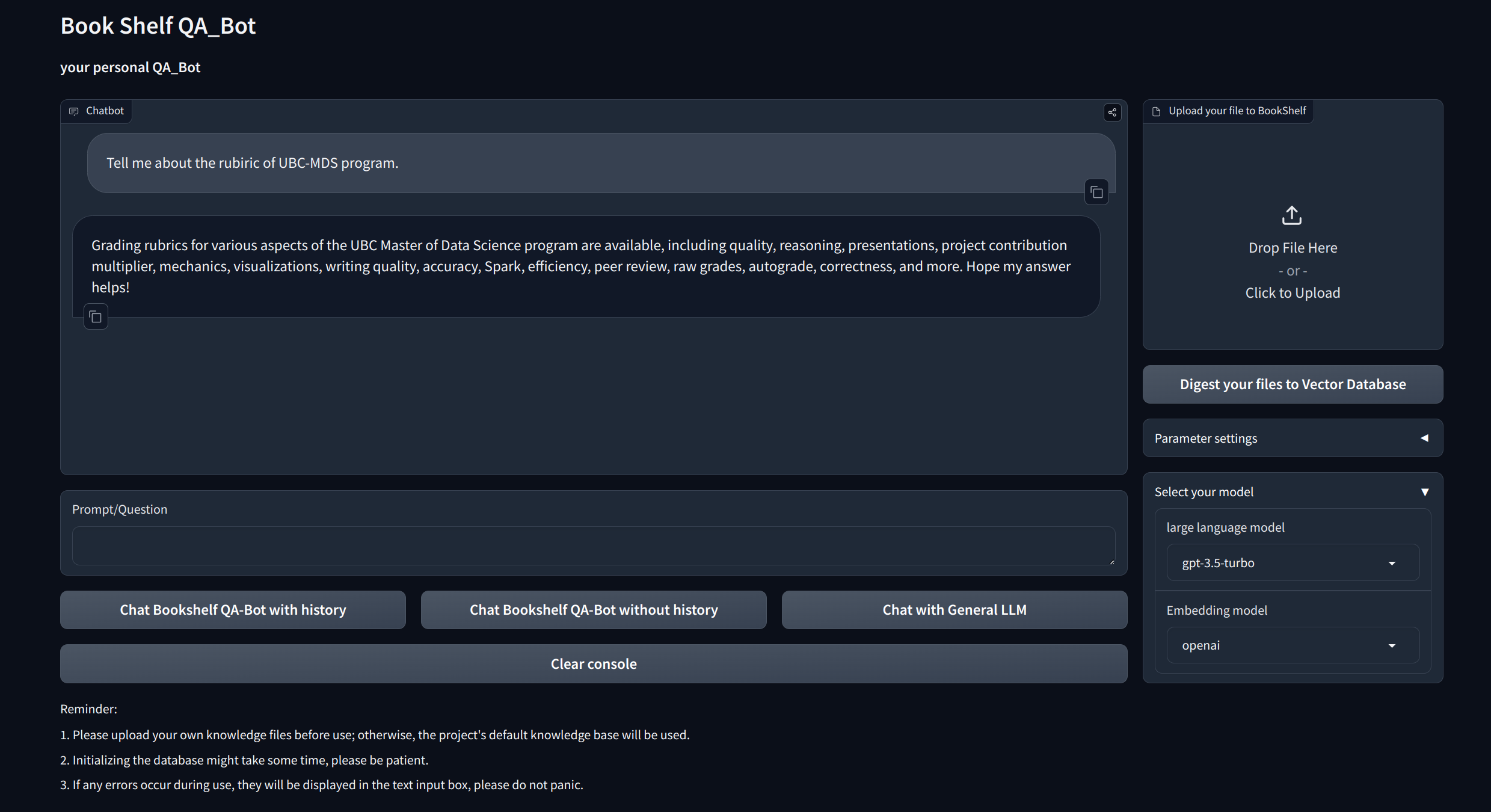
Preguntas y respuestas interactivas con trapo : aproveche la arquitectura de generación de recuperación de la generación (trapo) para facilitar la respuesta dinámica y precisa de las preguntas.
Interfaces de visualización : proporciona interfaces fáciles de navegar a través de Gradio y API a través de FastAPI para comenzar el proyecto, demostrar preguntas y respuestas y exhibir ejemplos.
Gestión del conocimiento personalizado : ofrece opciones de personalización para adaptar la base de conocimiento a sus preferencias. Los usuarios pueden cargar y vectorizar sus propios ducomentos para construir una "estantería" única que se ocupe de cierta información específica del dominio.
Compatibilidad multimodelo : admite una conmutación perfecta entre múltiples modelos de lenguaje grande (LLM) como GPT-3.5, GPT4 y más. Esta flexibilidad permite a los usuarios elegir el mejor modelo para tareas específicas, optimizar la precisión, la velocidad de respuesta y el costo.
Clon y configurar el proyecto:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtConfigurar la tecla API
Obtenga la tecla API de OpenAI y cree un archivo .env en el directorio root. Copie y pegue la cadena API con el siguiente formato.
OPENAI_API_KEY= " you openai api key string "Inicie el servidor API local:
cd app
uvicorn api:app --reload
O simplemente puedes ejecutar
bash app/run_api.sh
Ejecute el proyecto a través de Gradio:
python app/run_gradio.pyEste proyecto aprovecha un enfoque de pila completa basado en modelos de idiomas grandes, basado en el marco Langchain. La tecnología Core incluye llamadas de API LLM, trapo, bases de datos vectoriales y cadenas de preguntas y respuestas de recuperación. La arquitectura general del proyecto es la siguiente:
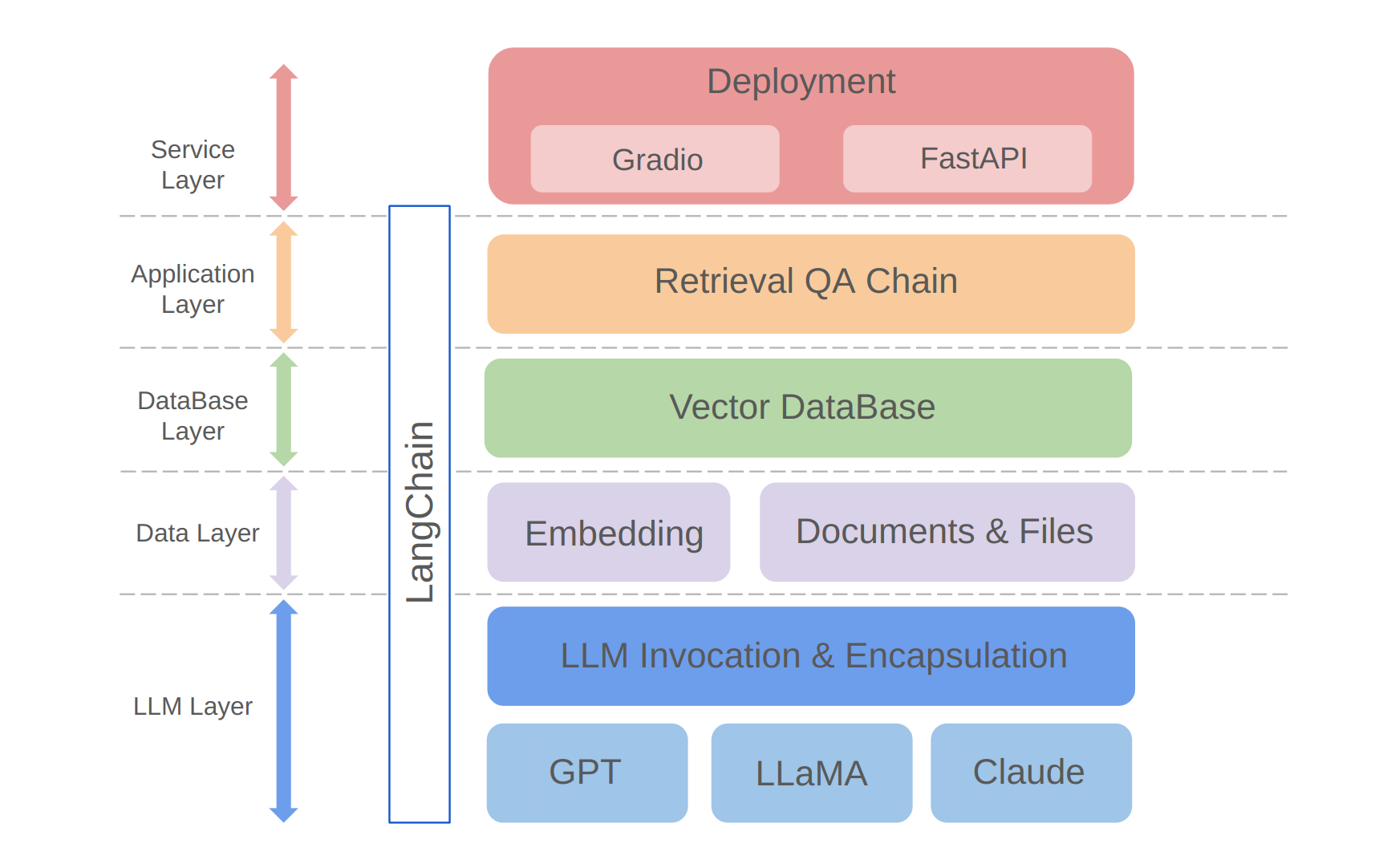
Como se muestra arriba, el proyecto está estructurado de abajo hacia arriba hacia la capa LLM, la capa de datos, la capa de base de datos, la capa de aplicación y la capa de servicio.
① La capa LLM implica principalmente la encapsulación de las llamadas de LLM para varias API y modelos LLM populares, lo que permite a los usuarios una entrada unificada y una forma de acceder a diferentes modelos, admitiendo el cambio de modelo sobre la marcha;
② La capa de datos incluye principalmente los datos de origen de la base de conocimiento personal y la API de incrustación, donde los datos de origen después del procesamiento de incrustación pueden ser utilizados por la base de datos de vectores;
③ La capa de base de datos se basa principalmente en la base de datos vectorial basada en los datos de la fuente de la base de conocimiento personal, para los cuales elegí el croma en este proyecto;
④ La capa de aplicación es la encapsulación de las funciones centrales de la capa superior, donde encapsulamos aún más en la clase de base de cadena de preguntas y respuestas proporcionadas por Langchain, admitiendo así diferentes conmutadores de modelo y facilitando la implementación de Q&A de recuperación basada en la base de datos;
⑤ La capa superior es la capa de servicio, donde implementé Gradio para construir demostraciones y Fastapi para ensamblar API para admitir el acceso al servicio del proyecto.
Gracias por su interés en este proyecto. ¡Espero con ansias sus contribuciones y ver cómo lo utilizará para mejorar su gestión de información y tareas de recuperación o escalarlo para aplicaciones comerciales como el servicio al cliente!


