Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
Bienvenue à Bookshelf-Qabot, il s'agit d'un projet d'assistant de base de connaissances personnels, une solution de chiffon conçue pour rationaliser votre accès à de grandes quantités d'informations rapidement et avec précision en utilisant la puissance des modèles de grande langue. Cet outil polyvalent est parfait pour les chercheurs, les propriétaires d'entreprise et toute personne ayant besoin d'une gestion efficace de l'information. Son évolutivité le rend idéal pour les entreprises qui cherchent à améliorer leurs capacités de service à la clientèle, en fournissant des réponses rapides et précises aux demandes des clients. Que vous optimistiez la productivité individuelle ou que vous amélioriez une opération commerciale, ce projet est adapté à vous.
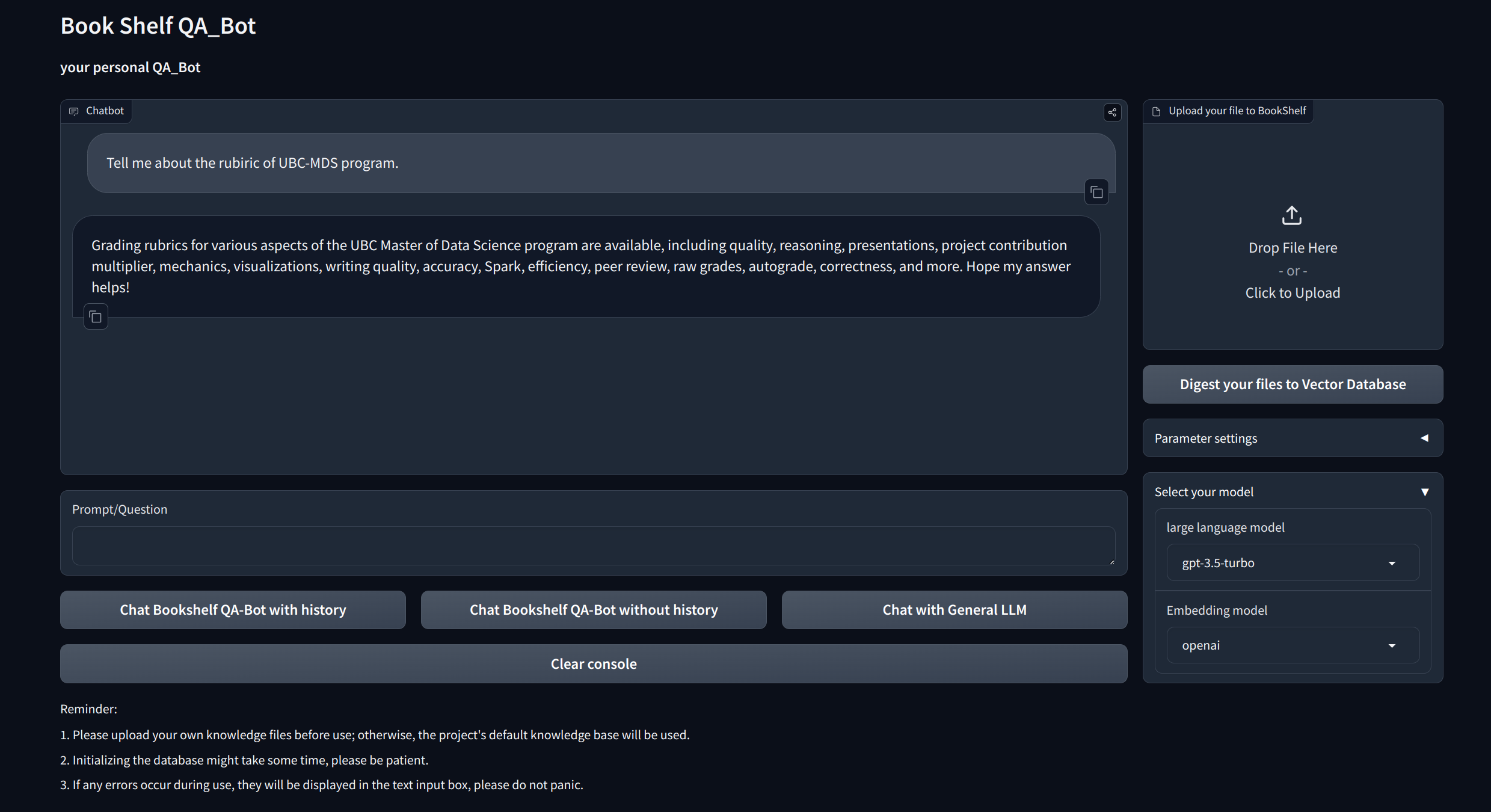
Questions et réponses interactives avec chiffon : tirez parti de l'architecture de génération (RAG) (RAG) de la récupération pour faciliter la réponse dynamique et précise.
Interfaces de visualisation : fournit des interfaces faciles à naviguer via Gradio et API via FastAPI pour démarrer le projet, démontrer des questions et réponses et présenter des exemples.
Gestion des connaissances personnalisées : propose des options de personnalisation pour adapter la base de connaissances à vos préférences. Les utilisateurs peuvent télécharger et vectoriser leurs propres dicoments pour créer une "bibliothèque" unique qui traite de certaines informations spécifiques au domaine.
Compatibilité multimodèle : prend en charge la commutation transparente entre plusieurs modèles de grande langue (LLMS) tels que GPT-3.5, GPT4, etc. Cette flexibilité permet aux utilisateurs de choisir le meilleur modèle pour des tâches spécifiques, d'optimiser la précision, la vitesse de réponse et le coût.
Clone et configurer le projet:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtConfigurer la clé API
Obtenez la clé API à partir d'OpenAI et créez un fichier .env sous Root Directory. Copiez et collez la chaîne API avec le format suivant.
OPENAI_API_KEY= " you openai api key string "Démarrez le serveur API local:
cd app
uvicorn api:app --reload
Ou vous pouvez simplement courir
bash app/run_api.sh
Exécutez le projet via Gradio:
python app/run_gradio.pyCe projet tire parti d'une approche complète basée sur des modèles de grandes langues, construits sur le cadre de Langchain. La technologie principale comprend les appels API LLM, le chiffon, les bases de données vectorielles et les chaînes de questions / réponses de récupération. L'architecture globale du projet est la suivante:
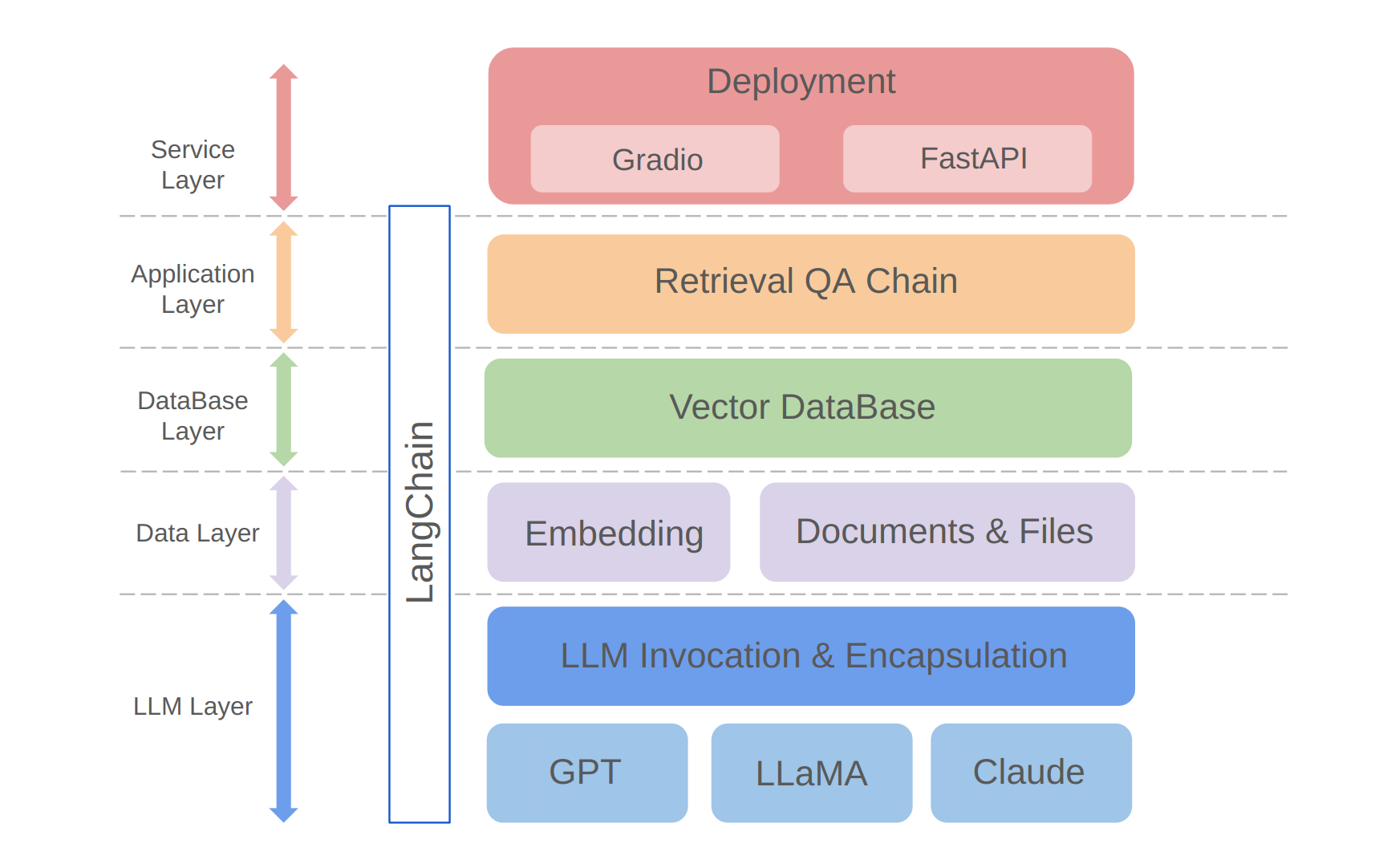
Comme indiqué ci-dessus, le projet est structuré de bas en haut dans la couche LLM, la couche de données, la couche de base de données, la couche d'application et la couche de service.
① La couche LLM implique principalement l'encapsulation des appels LLM pour plusieurs API et modèles LLM populaires, permettant aux utilisateurs une entrée unifiée et un moyen d'accéder à différents modèles, en prenant en charge la commutation du modèle à la volée;
② La couche de données comprend principalement les données source de la base de connaissances personnelles et de l'API d'intégration, où les données source après traitement d'intégration peuvent être utilisées par la base de données vectorielle;
③ La couche de base de données est principalement basée sur la base de données vectorielle construite sur les données de source de base de connaissances personnelles, pour lesquelles j'ai choisi le chroma dans ce projet;
④ La couche d'application est l'encapsulation supérieure des fonctions principales, où nous avons en outre encapsulé sur la base de la classe de base de la chaîne de questions et réponses fournie par Langchain, prenant ainsi en charge différents commutateurs de modèle et facilitant la mise en œuvre des questions et réponses de récupération basées sur la base de données;
⑤ La couche supérieure est la couche de service, où j'ai implémenté Gradio pour créer des démos et Fastapi pour assembler des API pour prendre en charge l'accès au service du projet.
Merci pour votre intérêt pour ce projet. J'attends avec impatience vos contributions et je vois comment vous l'utiliserez pour améliorer vos tâches de gestion et de récupération des informations ou de les développer pour des applications commerciales comme le service client!


