Bookshelf QABot
V0.2.1 QABot based on LLMs + RAG
مرحبًا بك في Bookshelf-QABOT ، إنه مشروع مساعد قاعدة للمعرفة الشخصية ، وهو حل RACT مصمم لتبسيط وصولك إلى كميات هائلة من المعلومات بسرعة ودقة باستخدام طرازات اللغة الكبيرة. هذه الأداة متعددة الاستخدامات مثالية للباحثين وأصحاب الأعمال وأي شخص يحتاج إلى إدارة المعلومات الفعالة. قابلية التوسع تجعلها مثالية للشركات التي تتطلع إلى تعزيز قدرات خدمة العملاء الخاصة بهم ، وتوفير ردود سريعة ودقيقة على استفسارات العملاء. سواء كنت تقوم بتحسين الإنتاجية الفردية أو تعزيز عملية تجارية ، فإن هذا المشروع مصمم لك.
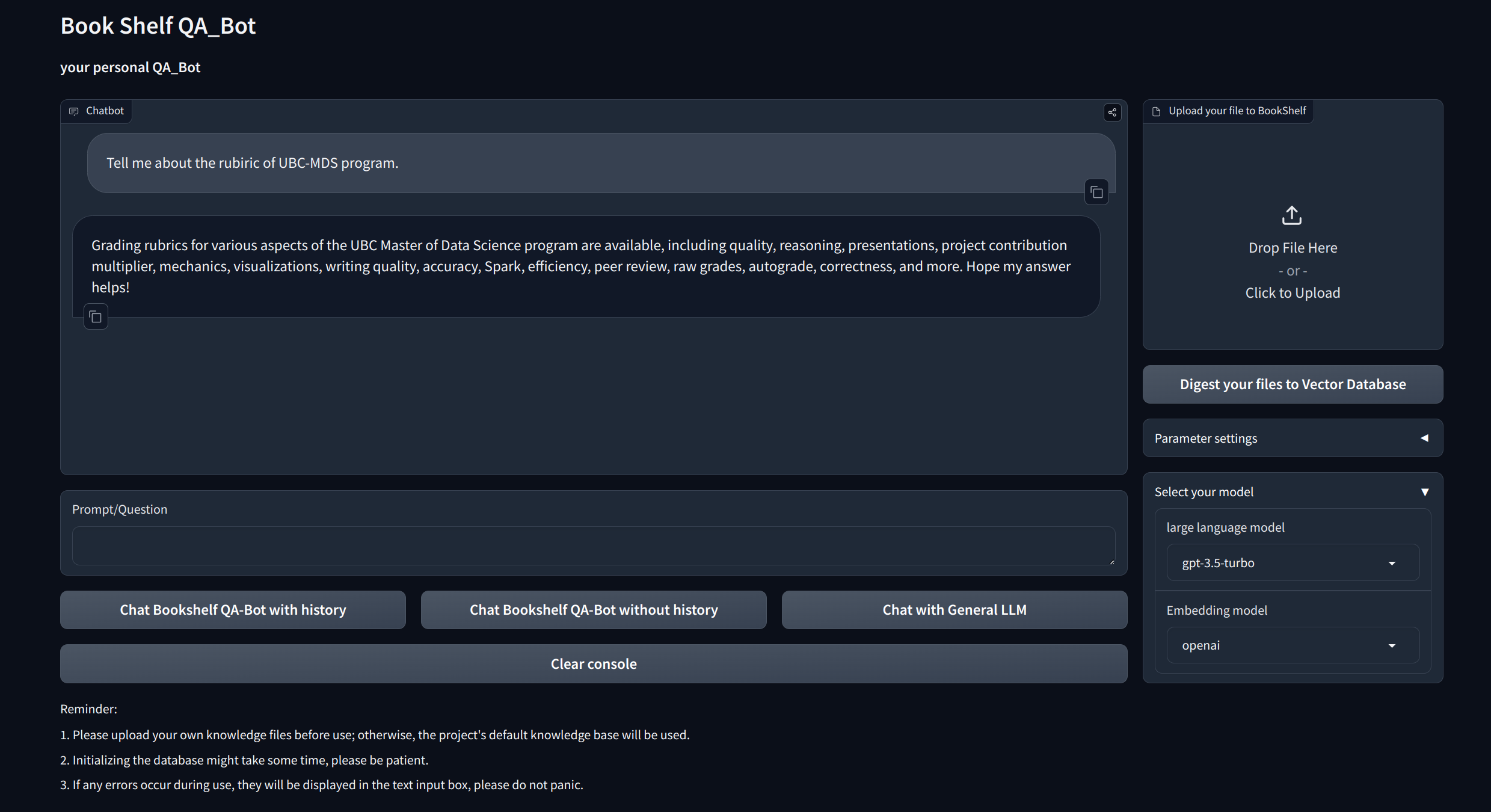
سؤال وجواب تفاعلي مع خرقة : الاستفادة من بنية الجيل (RAG) المتمحور في الاسترجاع لتسهيل الإجابة على أسئلة ديناميكية ودقيقة.
واجهات التصور : يوفر واجهات سهلة التنقل عبر Gradio و APIs عبر Fastapi لبدء المشروع ، وإظهار الأسئلة والأجوبة ، وعرض الأمثلة.
إدارة المعرفة المخصصة : توفر خيارات التخصيص لتخصيص قاعدة المعرفة لتفضيلاتك. يمكن للمستخدمين تحميل وتجاوز ducoments الخاصة بهم لإنشاء "رف كتب" فريد يتعامل مع بعض المعلومات الخاصة بالمجال.
التوافق متعدد النماذج : يدعم التبديل السلس بين نماذج لغة كبيرة متعددة (LLMS) مثل GPT-3.5 و GPT4 والمزيد. تتيح هذه المرونة للمستخدمين اختيار أفضل نموذج لمهام محددة ، وتحسين الدقة وسرعة الاستجابة والتكلفة.
استنساخ وإعداد المشروع:
git clone https://github.com/zhang-shizhe/Bookshelf-QABot
cd Bookshelf-QABot
conda create -n bookshelf-qabot python==3.10.14
conda activate bookshelf-qabot
pip install -r requirements.txtقم بإعداد مفتاح API
احصل على مفتاح API من Openai ، وإنشاء ملف .env ضمن دليل الجذر. نسخ ولصق سلسلة API مع التنسيق التالي.
OPENAI_API_KEY= " you openai api key string "بدء خادم API المحلي:
cd app
uvicorn api:app --reload
أو يمكنك ببساطة الجري
bash app/run_api.sh
قم بتشغيل المشروع عبر Gradio:
python app/run_gradio.pyيستفيد هذا المشروع من نهج الكامل الكامل يعتمد على نماذج لغة كبيرة ، مبنية على إطار Langchain. تتضمن التكنولوجيا الأساسية مكالمات واجهة برمجة تطبيقات LLM ، وقواعد بيانات المتجهات ، وسلاسل أسئلة وأجوبة استرجاع. العمارة العامة للمشروع هي كما يلي:
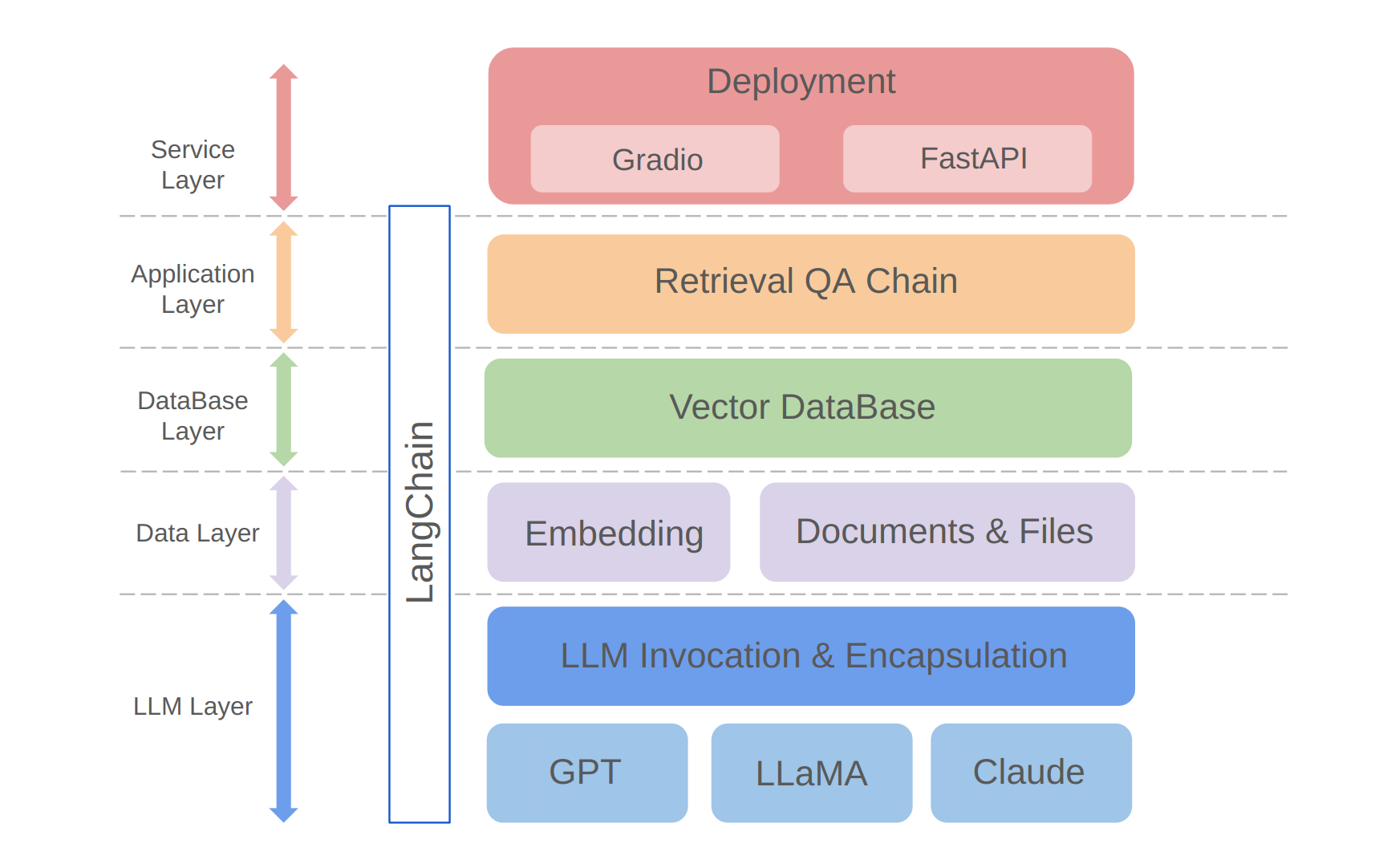
كما هو موضح أعلاه ، يتم تنظيم المشروع من أسفل إلى أعلى إلى طبقة LLM ، وطبقة البيانات ، وطبقة قاعدة البيانات ، وطبقة التطبيق ، وطبقة الخدمة.
① تتضمن طبقة LLM بشكل أساسي تغليف مكالمات LLM للعديد من واجهات برمجة التطبيقات والموديلات الشهيرة LLM ، مما يتيح للمستخدمين مدخلًا موحدًا وطريقة للوصول إلى نماذج مختلفة ، ودعم تبديل النماذج على الطاولة ؛
② تشتمل طبقة البيانات بشكل أساسي على بيانات مصدر قاعدة المعرفة الشخصية وواجهة واجهة برمجة تطبيقات التضمين ، حيث يمكن استخدام بيانات المصدر بعد التضمين من قبل قاعدة بيانات المتجه ؛
③ تعتمد طبقة قاعدة البيانات بشكل أساسي على قاعدة بيانات المتجه المبنية على بيانات مصدر قاعدة المعرفة الشخصية ، والتي اخترت Chroma في هذا المشروع ؛
④ طبقة التطبيق هي التغليف الأعلى للطبقة للوظائف الأساسية ، حيث تم تغليفنا بشكل أكبر بناءً على فئة قاعدة سلسلة أسئلة وأجوبة في الاسترجاع التي توفرها Langchain ، وبالتالي دعم مفاتيح النماذج المختلفة وتسهيل تطبيق استرجاع القاعدة المعتمد على قاعدة البيانات Q&A ؛
⑤ الطبقة العليا هي طبقة الخدمة ، حيث قمت بتطبيق Gradio لبناء العروض التجريبية و Fastapi لتجميع واجهات برمجة التطبيقات لدعم وصول خدمة المشروع.
شكرا لك على اهتمامك في هذا المشروع. إنني أتطلع إلى مساهماتك وأرى كيف ستستخدمها لتعزيز مهام إدارة المعلومات واسترجاعها أو قم بتوسيع نطاقها لتطبيقات الأعمال مثل خدمة العملاء!


